
Traditionally in Data Warehouse and BI projects, data processing is done in batch mode. ETL processes run for a set amount of time, generally during the night. When everyone arrives at the office in the morning the data is updated, reports are current, and everyone can move on with their day.

In today’s world of constant information, the way we consume and process data is changing. Data is being generated faster and faster, and in larger quantities. We no longer talk in terms of “yesterday’s numbers”, we want to know what’s happening right now.
The Internet of Things, or more recently, the Internet of Anything, is taking enterprises by storm and it’s changing how we need to approach data projects.
Move Over Batch Processing; Hello Stream Consumption
In the world of sensor data, we deal with streams of information. Streams have two main features
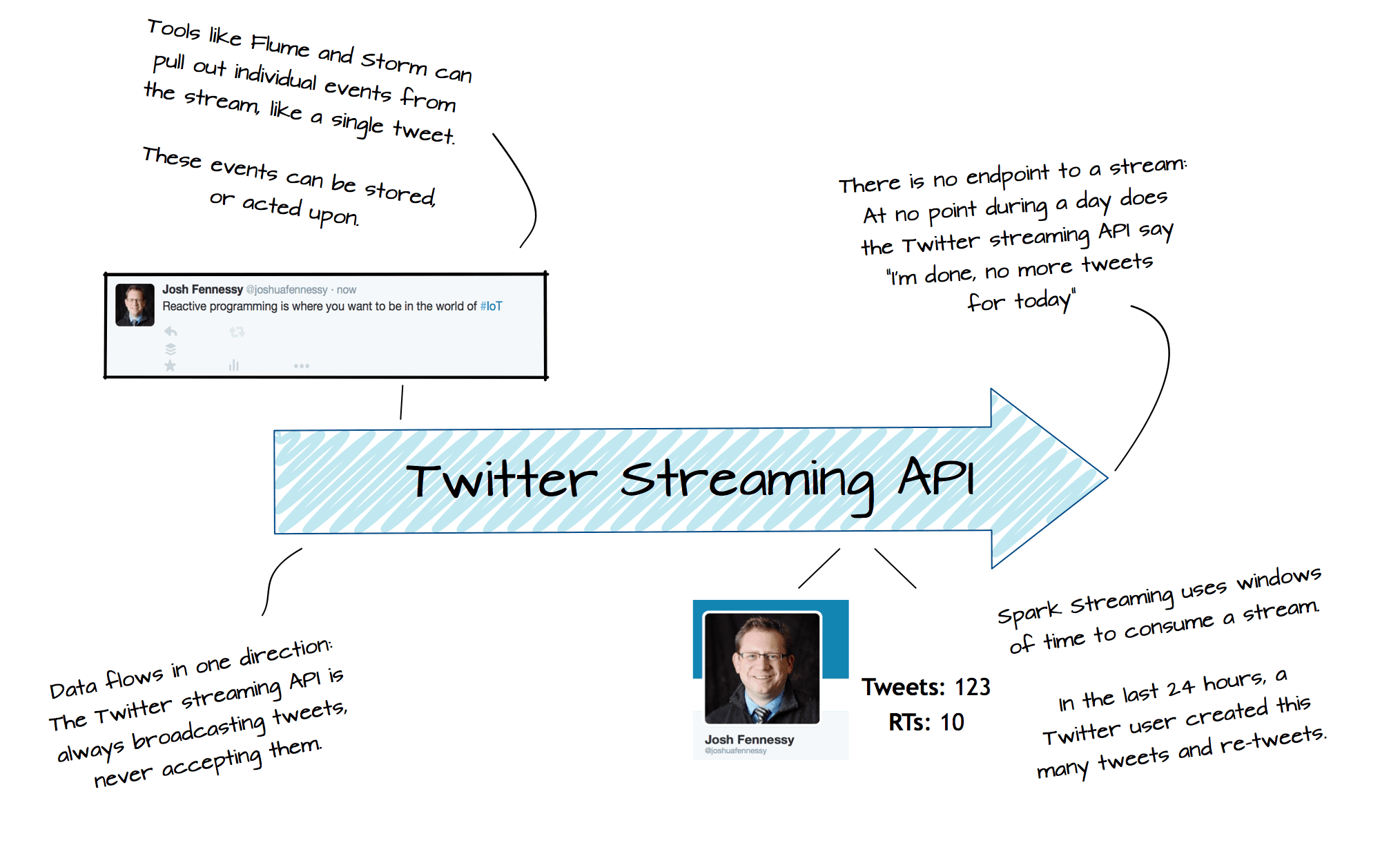
- Streams are continuous
Streams don’t have a defined endpoint. Data is continuously transmitted. It is not possible to define a time of day that makes sense to process the stream. It must be always processed.
- Streams travel in a single direction
Information moves from a sensor to an endpoint. A separate stream of information may move from the endpoint to another sensor. A single stream will always move in only one direction. Our data processing framework for a single stream needs to only know about the source and endpoint of the stream. It will not have to deal with the possibility of data moving in an unknown direction.
Because streams tend to move massive amounts of data and never end, we need a new way to interact, collect, aggregate, and analyze that data. It’s not enough anymore to just act upon data at rest; we have to react to data in motion.
Why Reaction instead of action
 In the traditional world of data architecture, batch ETL processing was sufficient. Our workloads were well defined. They often had an endpoint — the end of the business day — transactions could be easily grouped up and moved into a data warehouse.
In the traditional world of data architecture, batch ETL processing was sufficient. Our workloads were well defined. They often had an endpoint — the end of the business day — transactions could be easily grouped up and moved into a data warehouse.
In today’s sensor driven world, analytics often need to happen more often than just at the end of the business day. Reactive programming methodologies give us that platform we need to consume and process continuous streams of data, without missing data generated by the stream during an ETL processing window.
The Reactive Programming Manifesto tells us that reactive programs should be:
- Responsive – The data processing framework should respond to an event in a timely matter if it needs to. When a sensor measures a value outside of defined limits, it should notify the operator immediately. Not at the end of the day. Not all data architecture projects will require responsive alerts.
- Resilient – The data processing framework should be resilient to failure. If a listening node fails, another should take over. If a listening process on a single node fails, it should not take down other processes that may be running on that node. Hadoop and YARN provide the framework to support resiliency in our stream processing applications.
- Elastic – The data processing framework should respond to workload demand incresase or decreases. When more streams of data are added, the system should detect this extra traffic and spin up more cycles to allow the stream to be processed. Hadoop and YARN provide the framework to do this.
- Message Driven – The data processing framework should be message-based. These systems are inherently fast, as messages can be queued and delivered with little overhead. They are also fault tolerant as the transmission of the messages are handled by a different sub-system than is handling consumption of the stream.
In order for our Modern Data Architecture to support stream processing, we need to have the right tools that can handle directed and continuous currents of data. Some of these tools are system based, others are framework based, allowing data developers to build the right solution for the problem with source code.
Hadoop includes Reactive tools
Modern versions of Hortonworks’ HDP already include tools than can be used to create Reactive designed data frameworks:
- Apache Flume — is a stream consumption tool that can be used to passively listen to a stream and save information in a variety of formats. When run in cluster mode, it will automatically scale to increased workloads.
- Apache Storm — is an event driven stream consumption framework that allows robust applications to be created. Not only can Streams be consumed, but actions can also be taken in response to events that are happening in the stream. Apache Storm applications are commonly associated with the Lambda Architecture, which says that we can use a single stream to both react to and archive, without impact on the stream itself.
- Apache Kafka — is a distributed messaging system that allows for guaranteed transmission of data from source to subscriber. Kafka is often used when the stream throughput is more than a single machine can handle, and delivery AND order of the data needs to be guaranteed. Kafka is commonly used in conjunction with frameworks like Apache Storm to provide message based stream processing frameworks.
- Spark Streaming — is a micro-burst stream processing framework that allows for very short intervals of stream consumption. While not truly event driven, it is often times quite sufficient to poll the stream at a certain short interval, say 2 seconds, rather than consuming every event that happens Spark Streaming will poll the stream at the defined interval and allow for robust applications to be built that process that interval’s data.
- Hortonworks DataFlow — HDF is a new tool that provides a web-based graphical interface to design IoT architectures (see my first impressions here.) DataFlow is based on Apache NiFi and is a great new way to process streams of data. Not only does it contain nearly 100 data processors for working with all sorts of data ranging from REST APIs to sensor created data, it also provides a robust security model to ensure that only the right users can modify the flow architecture. In addition, it provides a number of reporting options that allow DevOps teams to monitor their IoT solutions. It is one of the first open source fully comprehensive IoT platforms available and is a very exciting product to keep an eye on.
Where do we go from here?
As always, in the data management world, there are many options to design a solution. An Architecture Design Session (ADS) is a great way to take a high level look at the features of the project. Working with an expert during the ADS will help to define what tools should be used during project development. Please contact us today for more information or to schedule a call.



