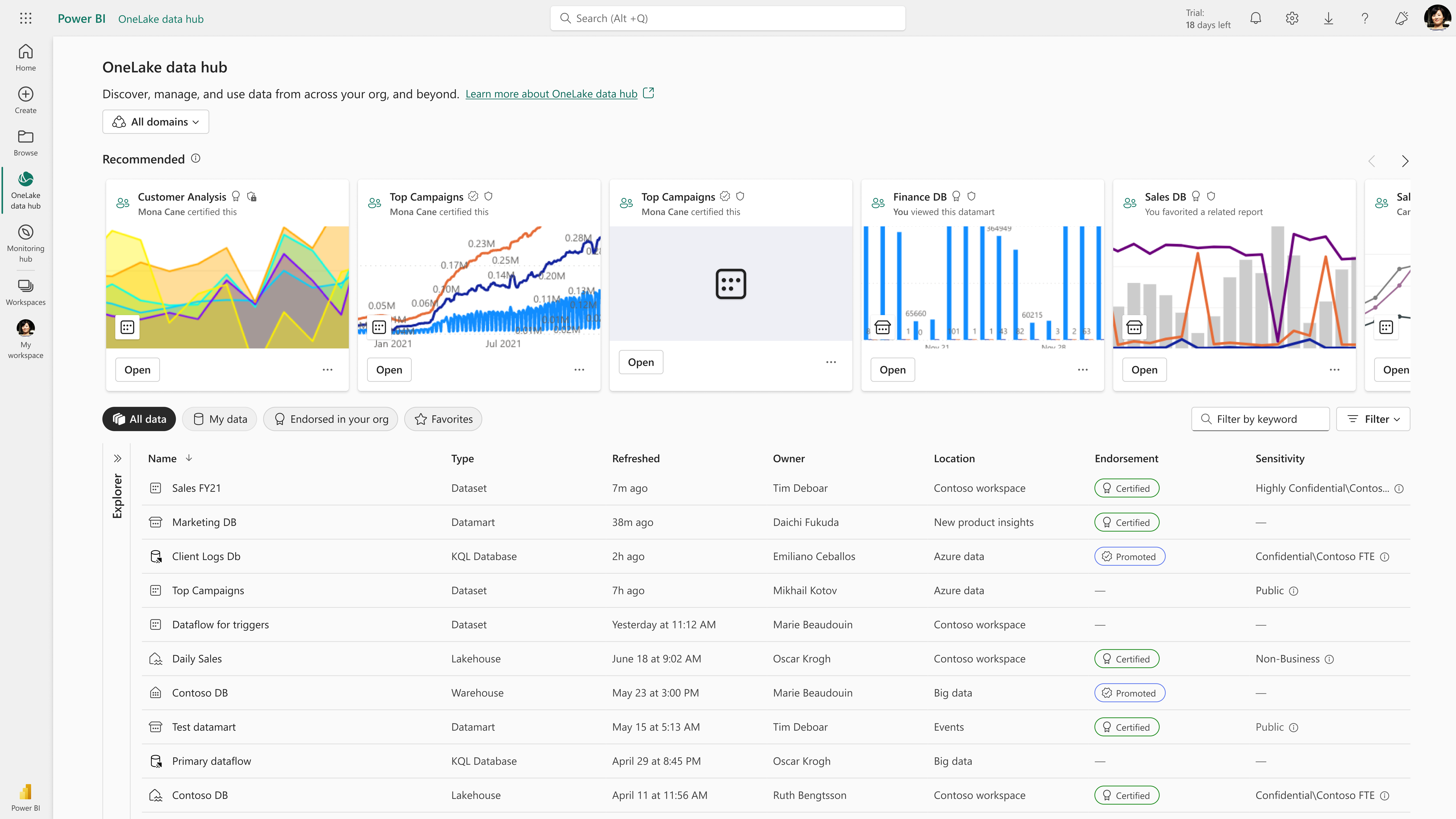
Microsoft has just announced their new software as a service intelligent data platform called Microsoft Fabric. This platform supports a single user interface to build out and share all the necessary components of your intelligent data solution. From data engineering to data storage to data visualization, this is the one stop shop for all things data and analytics. 3Cloud is proud to have partnered with Microsoft during the private preview by providing feedback and insights into how this product will work best for us and for our customers.
Microsoft Fabric is built on the much-loved Power BI platform. It brings in various other components from Azure such as Azure Data Factory for data movement and Spark technologies across data lakes to support medallion architectures. This, however, is just the beginning. Besides incorporating some of the key features and functionality required to run a successful intelligent data solution, Microsoft has continued to introduce innovative technologies and capabilities only available on this platform. They have incorporated features such as streaming as a no code solution and support for Power BI CI/CD natively.
Let’s talk about the improved streaming solutions. Microsoft Fabric brings front and center new paths to stream data from various sources. Introducing an event streaming landing page gives users a graphical way to trace streaming data sets from source to KSQL databases. It’s targeted to provide optimized low latency data analysis. By mirroring your Kusto DB to your lake house, real-time analytics or reporting becomes a much easier achievement for organizations.
Microsoft also listened to its users worldwide and enhanced core features used in daily activities. A prime example of this is how long it takes to spin up Spark resources to run notebooks. Historically, in Synapse, it could take more than 10 minutes for resources to be allocated and ready for notebooks to execute. Microsoft heard the pain this caused organizations and, now, resources are allocated and ready to go in seconds. Way to go Microsoft! This is truly a much-needed improvement that will encourage people to use Microsoft Fabric even more.
Microsoft also introduced a combination of features in a simple to use interface allowing users to start from an area of knowledge, whether that be in report modeling with Power BI or in data engineering with Synapse. With Microsoft Fabric, a business user or data analyst can easily ingest new data into a common data lake called OneLake and shape that data as needed. Engineers also have the capability to apply reporting or machine learning techniques to the data they have collected and then share that with the rest of the organization.
The Power of One
A feature that makes Microsoft Fabric so unique is the idea of one. To start with, Microsoft Fabric is built on the idea of one unified lake called a “OneLake” for your organization. OneLake is meant to be the OneDrive for data. The concept behind OneLake is to minimize the duplication of data across your environment by allowing the sharing of data in a single lake. The goal is to remove the silos of data that you can experience in common data lake and data warehouse scenarios today. Besides removing these silos of data, Microsoft Fabric is focused on storing the data in one way, using delta and parquet. This removes the barrier of having data stored in a variety of proprietary formats and allows for an open source format, which is available and accessible outside of Microsoft Fabric as well.
This is reinforced by having one security model throughout as well. Typically, environments are siloed in diverse ways including data versus reporting or other assets within your environment. In Microsoft Fabric, you can secure data at the lowest level and have that security enforced throughout the rest of the platform. Whether working with your data in development or consuming your data in reporting, your data will stay secure. This helps you with simplified governance and security management, thus reducing the workload on your team.
Working in Workspaces
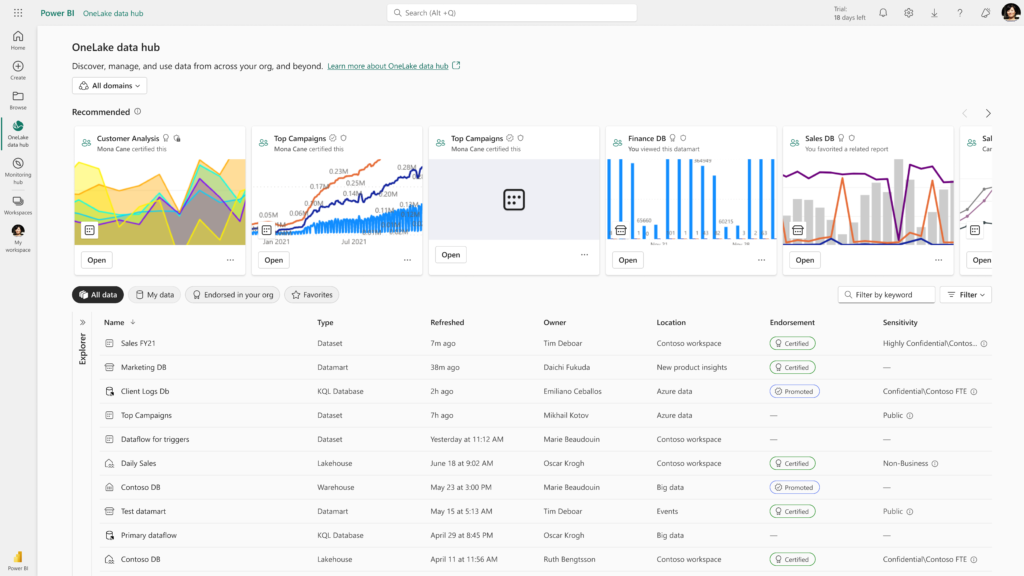
Now that you understand some of the unified components within Microsoft Fabric, let’s talk about workspaces. Services and data within Microsoft Fabric are managed within the context of the workspace like a Power BI workspace. Each workspace has security associated with it that allows you to manage work being completed within the workspace, as well as the data generated or managed within that space. This allows for a flexible implementation, while at the same time leveraging unified security, as noted above. You might have business teams owning their entire data estate from ingestion to reporting. They can then share that content with other business areas while maintaining the security and quality of the data they own from a business perspective. This allows businesses to have data managed by the team that best understands their data, not necessarily a technology team. This is commonly referred to as a data mesh architecture and is easily supported within Microsoft Fabric.
Workspaces not only provide a data mesh type of architecture support, but also support various other data warehousing and data lake techniques such as medallion architectures and centralized data warehouses. The workspace provides a security and work boundary that can be used to match your business in the way that you operate. For example, you might choose to use separate workspaces to handle your bronze and silver domains. Each workspace can contain the compute resources required to manage the data movement and transformation, as well as the data itself. This allows you to separate the teams as needed to support the type of work required in that environment. It also allows you to make sure that the only people that have access to the tools and data at this point in the process are those individuals who should be working in that environment.
Hybrid Scenarios
You already have an existing data warehouse or data lake. How will Microsoft Fabric help you? Microsoft Fabric is not limited to only data that lives within OneLake. Using an innovation called shortcuts, you can access data residing in Microsoft Azure and Amazon Web Services without migrating that data or migrating the technology required to load that data. The ability to run in a hybrid environment is a common scenario when working with Microsoft and Azure cloud services. In this case, you can leverage the existing assets you have created over time and share the resulting data within Microsoft Fabric where it can be used in new processes or just in reporting. Over time you may choose to migrate components to Microsoft Fabric to take advantage of the pristine environment, but you do not need to do that immediately to take advantage of the new capabilities.
How is this software as a service?
There are two main components that make this software as a service as we see it. The first is a common charge structure, making it easier for customers to consolidate their costs and manage their overall consumption. Microsoft Fabric uses a consumption-based model like Power BI Premium but has more flexibility in the sizes of the capacity that are available. Microsoft Fabric will have a small capacity, which can support small businesses who want the capabilities of Microsoft Fabric, but not necessarily the complexity of building out their own solution. It will also support large enterprises who have a myriad of data assets that they want to make available in a simpler fashion, as well as distribute various portions of the cost using Microsoft Fabric compute.
The other area we see Microsoft Fabric making substantial impact in as software as a service is in the simplicity of the solution. Significant work has gone into Microsoft Fabric to simplify tasks so you can focus on getting insights out of your data, not on building data solutions. Many aspects of Microsoft Fabric are low or no code. That said, full code options such as Jupyter notebooks are available to support more complex scenarios requiring Spark or similar programming languages. This means that you can create a workspace in Microsoft Fabric, build out your solution, and deliver insights with limited custom code. However, when you run into that scenario where you have more complexity, Microsoft Fabric can be used for that as well.
Call to Action
Now that Microsoft Fabric is in public preview and available for you to try, where do you think you’ll start? Do you have a workload that you’d like to evaluate in Microsoft Fabric to determine if the workspace and data mesh environment is well-suited for the work you’re doing? Let our experts at 3Cloud come alongside you and leverage the experience we’ve acquired while working with the product through its preliminary stages. We can provide guidance on how to apply and work with Microsoft Fabric along every step of the way. We also encourage you to check out our YouTube channel for many different how-to videos based on where you are starting from and what you would like to try. Contact us directly today to learn more!
Find more resources about Microsoft Fabric here: