
The Microsoft Intelligent Data Platform, combined with Databricks, provides a forward-looking data lakehouse solution that will support your analytics needs into the future. You may be thinking, why do you need a data lakehouse solution right now? As you continue to evolve your data estate, modernization and optimization come into play. The Microsoft Intelligent Data Platform with Databricks is designed to be flexible and durable to support your data and analytic needs for years to come.
Databricks with the Microsoft Intelligent Data Platform creates a flexible data analytics solution for your organization by leveraging the power of Delta and the data lake. By using the data lake as your primary storage solution, you can standardize your storage methodology while at the same time supporting multiple methods for integrating and consuming your data. This flexibility is built on standard practices and open-source technologies. These platforms give you the ability to leverage both Microsoft and non-Microsoft tools to engage in more complex scenarios using Databricks.
Databricks has spent time developing tried and true methods of data ingestion, from small workloads to big data workloads. Effectively partnering with Microsoft will provide a best of breed solution to fit all organizations. For example, while at the time of this article converting Iceberg tables to Delta Lake is in public preview, Databricks has continued its advancement on converting parquet to delta. What does this mean to organizations? This means you can quickly use built-in functions like AUTOLOADER or COPY INTO to get off the ground and start ingesting data into the lakehouse architecture.
This platform is also durable in that it will be a technology that supports the advancements of data management into the future. The most significant improvements in handling data for analytics and advanced workloads, such as AI, have happened within the data lake arena. With Delta live tables, developers and engineers can interact with data while it sits in the lakehouse architecture. Databricks continues to invest in their Photon Engine’s advancements, which provides low cost and fast capabilities to interact with an organization’s data. Since the Photon Engine is compatible with Apache Spark, it offers ease for migration as it will not require code changes.
3Cloud uses a combination of Databricks and Microsoft technologies to help accelerate their customers into the Microsoft Intelligent Data Platform. We use custom developed dynamic processes to ingest data from multiple sources and land it to delta tables which replicate various source systems to the lakehouse architecture. These processes give developers, engineers, and data scientists a platform to quickly use various tools to access and provide businesses insights into their data.
The data lake is unique in that it allows for the continued evolvement of how to use the data without the need to move the data into another structure. By leaning on this method, you can have a data analytics platform and data that could be used in a variety of ways for years to come.
This pattern is shown in the image below and is an exceptional way to realize the most benefit out of your data.
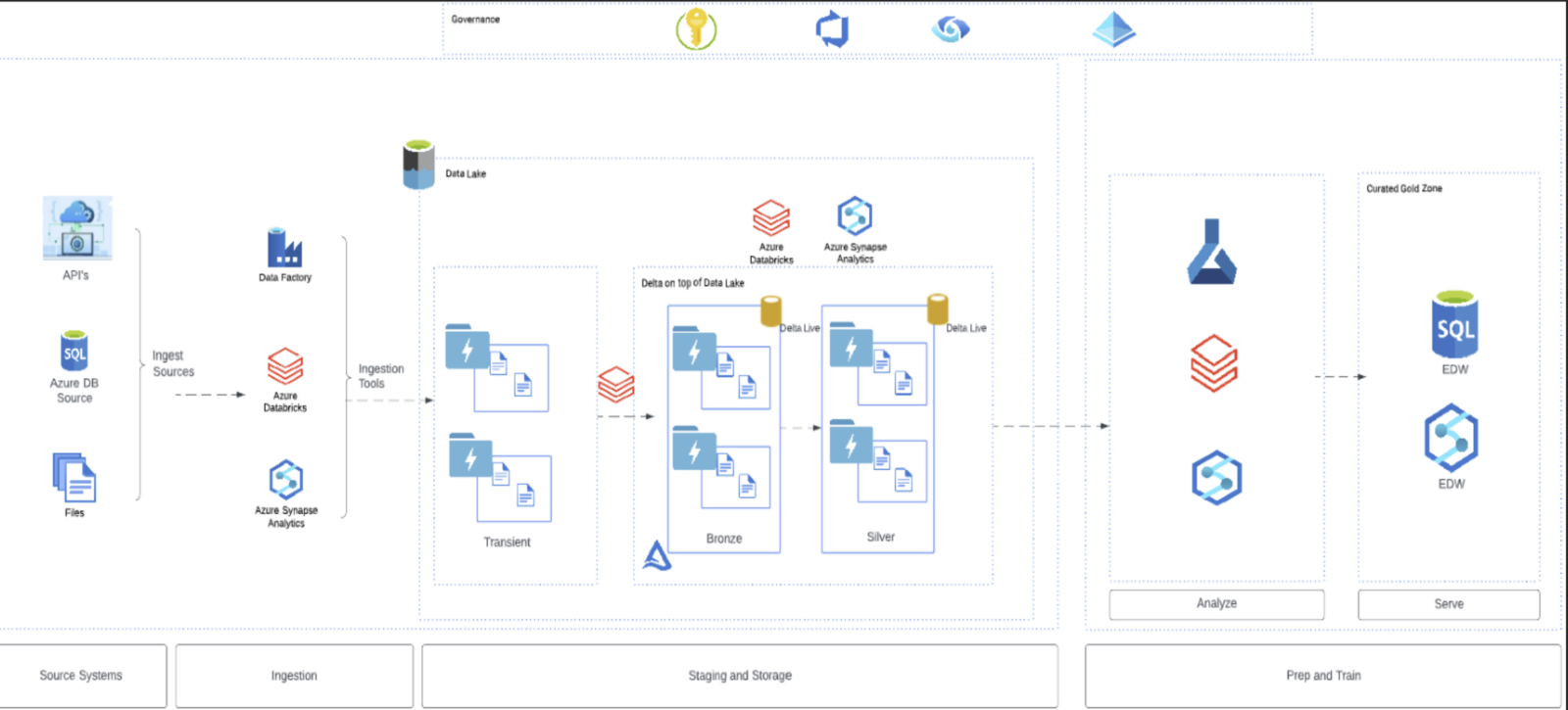
As you look at your current data estate, you may see the opportunity to upgrade or improve your environment if only you could migrate your existing data warehouse into the new intelligent data platform. The ability within this platform to be the new home of your data warehousing and data analytic needs is, without a doubt, a target for you.
Why Databricks?
Databricks is the leading technology supporting the lakehouse methodology. By embracing Databricks in the Microsoft Intelligent Data Platform, Microsoft is enabling users to take advantage of the latest advancements in data lakehouse and related technologies from Databricks. In this blended environment, we can work with Databricks in context with other Azure technologies, getting the best of breed across the board.
At Microsoft Ignite and PASS Summit, Microsoft renewed its commitment to its partnership with Databricks, and Databricks did the same in return. This means we will see a continued investment in Databricks from Microsoft and a return from Databricks in working with Microsoft technologies as you move into the next stage of data lakehouse. This combination of two powerhouse data vendors creates a unique opportunity for us to build a best-in-class data lakehouse solution to be the target for your data warehouse and data analytic needs.
Now, let’s shift our focus to the how around what we are going to do. A lakehouse is not a relational database, and considerations need to be made when executing a migration. We’re going to walk you through some considerations and discuss an opportunity for more investigation as we move forward.
From Relational to Lakehouse
So, you have determined you want to make the journey. The next step is evaluating your current data warehousing solution to determine how you would like to migrate this to the lakehouse. There are a lot of considerations when you are doing this migration. We will need to evaluate the design of the current data warehouse and how it will best be modeled in the lakehouse. From there, we need to also determine the best route to incorporate the ETL processes from the source systems. In many cases, your existing work can be used as a starting point in this migration.
As can be expected by changing the overall structure of your data, you will likely need to incorporate new ETL processes to support the initial ingestion. Moving the data from your source systems to the data lakehouse is meant to be as noninvasive as possible to those source systems. The goal is to copy that data into the data lake and use the strength of the data lakehouse and Databricks to handle any required transformation or cleanup. 3Cloud has been working with these products for years and has developed accelerators that can be used to land raw data into your lakehouse and prep it for data warehouse workloads. These accelerators allow us to move your migration forward by handling many of the simpler tasks in a standard process and format.
You’ll need to model or plan how you want to handle the lakehouse as you move forward. It needs to incorporate new and better approaches than you currently have, as well as maintain what you need for reporting solutions. You can retain your current design, such as a dimensional model, but you should also plan on how all the data can be used in new and exciting ways such as AI.
If the core of your data warehouse solution is built on the SQL Server platform, much of your code will need to be translated from SQL to Spark as part of this process in order to take advantage of the Photon Engine. This is the heavy lift portion of this project. 3Cloud has invested time in building custom processes that easily translates 75% of your common SQL functions to Spark. There are many functions not compatible between the two, and we have developed automated processes to significantly decrease the amount of time needed to translate and convert to equivalent Spark functions.
From the Lakehouse to Reporting
Now that you have data in the lakehouse, how does it affect your overall reporting solution? This is where Synapse Analytics plays a major role. The lakehouse stores data in the data lake as expected which can then be leveraged or used by serverless in Synapse Analytics. Serverless over the top of Delta allows end users and report writers the ability to work with the lakehouse data as they would have a data warehouse, but they now have access to the data in more ways. Report writers who are fluent with SQL will be able to use a serverless database with familiar tools and syntax to update and manage their reports.
The lakehouse further supports the ability to interrogate and discover the data before it has been modeled in a database. This gives data analysts and report writers the ability to create or influence data models that are best suited for the reporting requirements. Because the data models themselves are effectively metadata, changes can easily be made to the schemas without impacting the underlying data. If your data has been moved into a SQL Server environment, you may need to refresh that data once your schema changes are made. However, there is a big change from a traditional data warehouse environment, all data and states of data can be stored in the data lake, which is recommended. This gives you replay advantages across your environment while at the same time giving you cost savings in storage.
Power BI is a recommended approach for reporting because of its expansive and built-in support for data lakes and databases. Power BI can be natively built on top of data lakes to support short term reporting without requiring significant changes to schemas within the data warehouse environment. Power BI can also take advantage of the Databricks environment and pull data directly as needed for reporting or analytics.
Expanding on the Lakehouse
Once you have built out your lakehouse and have met your reporting needs and demands, you can now expand your analytics capability, including implementing machine learning and AI against the data. Data in lakehouses is uniquely positioned to support multiple use cases, including machine learning from the Azure machine learning suite as well as the Databricks machine learning suite. You have the opportunity and flexibility to choose the right tool for the work that you are planning to do.
Whether you are deeply experienced or a beginner in the world of machine learning in advanced analytics, the lakehouse is a great platform to work from. Because the lakehouse itself is not vendor specific, you can leverage native Azure tools such as Azure ML and Cognitive Services with this data. If you already have a significant investment in Python or similar machine learning or advanced analytics tools, you can port those over to Databricks ML including the notebooks for ease of migration to a single platform. Databricks supports many sophisticated machine learning options for you as you move forward.
While this is not an exhaustive list of what will become available to you once you move from a data warehouse to a data lakehouse, is important to understand that data lakes and the lakehouse provide a common storage platform from which to launch the reporting and analytics needs of your data state for your company.
What’s Next?
Hopefully now you have a vision for what is possible and a path to that possibility. While moving to a lakehouse represents a significant change from the traditional data warehousing solutions, we have seen in the past that it creates a durable and flexible solution for your data estate now and into the future. At 3Cloud we specialize in building out intelligent data platform solutions with Databricks and Microsoft as significant partners.
Connect with Us!
Please reach out to us to find out more about how 3Cloud’s talented team can help you bring clarity and efficiency to your Modern Analytics endeavors today.
3Cloud offers a variety of resources to help you learn how you can best leverage your Modern Data Platform.
Please visit our website and YouTube Channel to learn more or contact us directly to see how we can help you explore your modern data analytics options and accelerate your business value.



