
Microsoft recently announced a new data platform service in Azure built specifically for Apache Spark workloads. Azure Databricks is the fruit of a partnership between Microsoft and Apache Spark powerhouse, Databricks. The service provides a cloud-based environment for data scientists, data engineers and business analysts to perform analysis quickly and interactively, build models and deploy workflows using Apache Spark. Below are some of the key reasons why Azure Databricks is an excellent choice for data science and big data workloads.

Reason #1: Speed
Anyone familiar with Apache Spark knows that it is fast. It can run up to 100x faster than Hadoop MapReduce when running in-memory, or up to 10x faster when running on-disk. Azure Databricks is even faster!
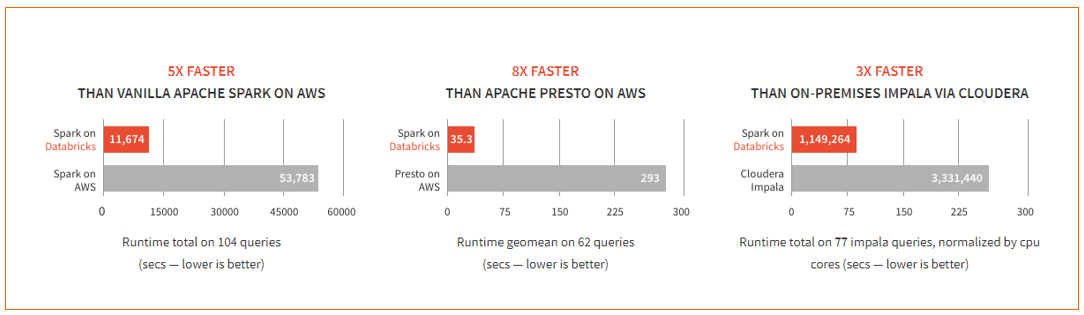
The team at Databricks provides a series of performance enhancements on top of regular Apache Spark. These include caching, indexing and advanced query optimizations. The benchmarking data below, from a recent post by Juliusz Sompolski and Reynold Xin on the Databricks Engineering Blog, shows that these optimizations contribute to a performance increase of up to 8x over other, similar big data SQL platforms. Tack that on to the already 10 to 100x performance gains, and one can see the obvious processing efficiencies this engine provides.
Reason #2: Security
Azure Databricks integrates directly with Azure Active Directory (AAD) out of the box, with no custom configuration. This differs greatly from Apache Spark on Azure HDInsight, where AAD integration is a premium feature requiring considerable configuration using Apache Ranger.
After creating the Azure Databricks service and initializing the Databricks workspace, users with access can simply go to the workspace URL and log in using their AAD credentials.
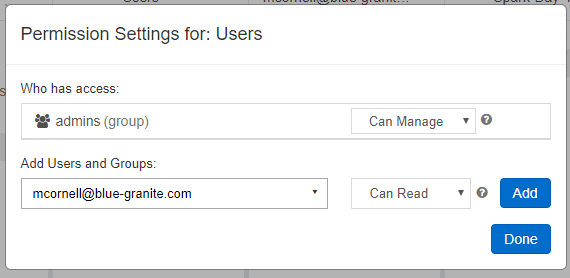
Once inside the Databricks workspace, administrative users can navigate to the Admin Console where they can easily add, delete and manage users in the workspace. They can even invite external users (users not in the same AAD) to the workspace, as long as the user belongs to another AAD.

Reason #3: Collaboration
Collaboration is the third reason to choose Azure Databricks for data science and data engineering workloads. Azure Databricks provides a platform where data scientists and data engineers can easily share workspaces, clusters and jobs through a single interface. They can also commit their code and artifacts to popular source control tools, like GitHub.
Within Azure Databricks, users can spin up clusters, create interactive notebooks and schedule jobs to run those notebooks. Using the Azure Databricks portal, users can then easily share these artifacts with other users. This allows users to create and build models together in the same notebook in real time, to re-use data assets, libraries and compute resources across the same cluster, or to re-use and monitor scheduled jobs.
Data engineers and data scientists that use popular source control tools like GitHub and Bitbucket to manage their code can continue to do so with Azure Databricks. This will allow companies that have adopted enterprise-wide, platform-independent source control processes to continue using their established methods. Azure Databricks makes it easy to link and sync artifacts like notebooks to a Git repository where they can live, even if the Azure Databricks workspace goes away.
Azure Databricks, the exciting new Azure service, helps companies innovate more effectively and efficiently on top of big data. If you are interested in learning more about this service, and how it might fit your company’s data platform, contact us, or check out our Azure Databricks Resources.



