
In today’s post, I want to talk about designing a data flow for a warehousing situation. I’ll refer to the reference cloud-based data warehouse data flow architecture that Microsoft has published which you’ll see in the image below.
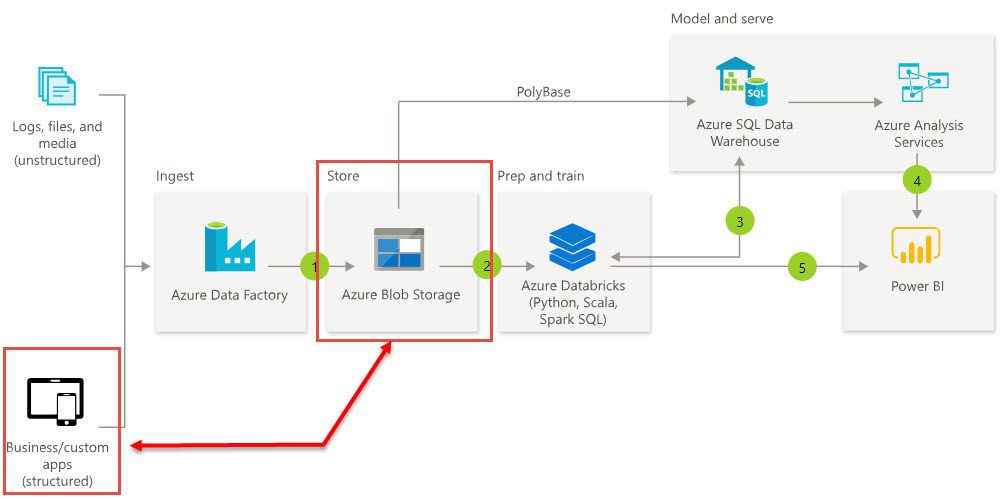
I want to talk about the idea of taking data from our source systems and storing it in file storage. The diagram indicates we’d do this in blob storage. We sometimes prefer using Azure Date Lake, but regardless, the data is still being extracted from a source and put into files which are then loaded into the data warehouse.
I’m frequently asked, why would I store my data in files? For instance, if my source data is coming from a relational database, maybe pulling from an ERP system, why would I take data from that system, store it in files and then load it to my data warehouse?
Let me point out some reasons why:
-
- It generally reduces the number of times that we need to access our source databases. We can extract files one time, particularly in development testing, and use them over and over without having to re-query our source database. The fewer times we can touch our source database, the better.
- If I have that data from my application sitting in files, I can use that data for any number of analytics cases. Let’s say I’m building a data warehouse and I need some data from my system. I pull the data out and build my data warehouse. With the data sitting in those files, I have a wide variety of opportunities to analyze that data using other analytic tools, like Power BI, to view those files and do analysis on them. I can also use tools like Hive, Spark and Databricks to do analysis on my application data without having to go back to the application.
- A big reason I prefer to do this is I increasingly prefer to separate the process of extracting my source data from the process of loading it to the data warehouse in a data warehouse loading scenario. Traditionally those types are combined where I’ve got one big ETL process; it pulls data from my source, does transformations and then it loads into my warehouse. But in a scenario where that data warehouse load fails, then I have to re-extract data from my source system. By building a separate process of extraction and loading, I can minimize the number of times I have to extract data.
- Lastly, what if that source system goes away, like it gets sun-setted or migrated to a new platform for example? In that case, my source data may no longer be available. But if I have that data available in files, then I can use it for analyzing legacy data or whatever the case may be, I have it.
So, these are some key reasons/benefits to help you understand why you may want to store data in files prior to loading it into the data warehouse. As I’m asked about this a lot, I hope you found this useful.
Need further help? Our expert team and solution offerings can help your business with any Azure product or service, including Managed Services offerings. Contact us at 888-8AZURE or [email protected].



