
In this post I’d like to review some information about using ORC, Parquet and Avro files in Azure Data Lake, in particular when we’re extracting data with Azure Data Factory and loading it to files in Data Lake.
In the screenshot below, I’ve shown how we can set up a connection to a text file from Data Factory. When you create a connection to a text file, we have choices of file formats. I’ve highlighted the three I’m discussing here – ORC, Parquet and Avro.
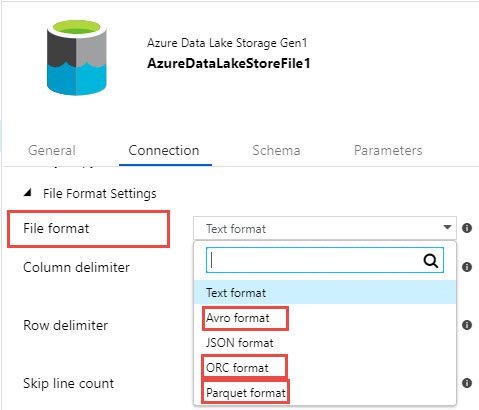
One important thing to understand is that Azure Data Lake is an implementation of Apache Hadoop, therefore ORC, Parquet and Avro are projects also within the Apache ecosystem. These were built on top of Hadoop with Hadoop in mind, so they are kind of one and the same in many ways.
All three of these file formats were developed with the primary goal of improving query performance. The idea was, if I have data in one of these file formats, if I query it, my query results will be faster than anything that was previously available.
ORC, Parquet and Avro focus on compression, so they have different compression algorithms and that’s how they gain that performance. ORC and Parquet do it a bit differently than Avro but the end goal is similar. One difference with Avro is it does include the schema definition of your data as JSON text that you can see in the file, but otherwise it’s all in a compressed format.
So, if you have data in any of these three formats, you can use Data Factory to read that out of Data Lake.
Another feature of these files,compared to text and JSON files, is that if we’re reading data from a source system, it’s more flexible as far as text formatting. So, we don’t have to choose column or row delimiters or text qualifiers. We’ve worked with a few clients where we’re pulling data from Salesforce. Salesforce (and some others) have many fields that have very large text values, which makes it hard to load that data into a text file without running into problems with delimiters, etc. Using ORC, Parquet or Avro is a way around that.
I ran a small test and the results are shown in this screenshot below. I had a simple table in a SQL Database with a couple hundred rows. I dumped the contents of that table to the 5 file formats that are available from Data Factory when we load to Data Lake.

What I want to highlight is the size of these (again this is a very small file), and you can see that when I load to ORC and Parquet, the file size is considerably smaller than the others. This is not a great example for the Avro file as it’s a small dataset, so in this example it compares size-wise to the .txt file, but not surprisingly, the JSON file is quite large.
The key point here is that ORC, Parquet and Avro are very highly compressed which will lead to a fast query performance.
Need further help? Our expert team and solution offerings can help your business with any Azure product or service, including Managed Services offerings. Contact us at 888-8AZURE or [email protected].



