
The novel SARS-CoV-2 coronavirus has thrust us into novel times. Many foundational norms – social, economic, education, civil – have been turned upside down. Lives are disrupted. Health is at risk. Hope and fear mingle in equal parts. But we are a resilient society, and ultimately we will pull through.
As we collectively grapple with the daily challenges of these uncertain times, we must also look to what comes next. Unfortunately, many among us haven’t that luxury. Our heroic health care providers and first responders must maintain focus on the here and now. But those who can look to the future should be working to assure that what comes after the crisis will honor their sacrifices.
How Data Science is Taming COVID-19
When we say that the COVID-19 disease is caused by the novel SARS-CoV-2 coronavirus, novel expresses that we have not encountered this particular virus before. In lieu of that direct experience, we turn to our experience with other coronaviruses and viruses in general to inform our responses. This alternate experience is codified in various historic epidemiology models for infection, hospitalization, and mortality. Starting with these alternate models, we conservatively calibrate them with initial parameters that drive disease progression projections based on observations of the disease from other countries. Then, over time, we continue to refine the parameters and select the most meaningful models as we learn more and more about this new disease.
One of the benefits of this approach to modeling COVID-19 is that our leaders can make decisions based on the best information that they can get from these models before the models have been perfected. Actions from these decisions alter real world disease progression, so model refinements must take these changes into account also. Although each generation of the models is short-lived, over time the leading generations become more and more accurate and predictive.
The results of the cyclic process by which the COVID-19 models are perfected can be illustrated by this example showing the increased precision of their estimates of total deaths over time:
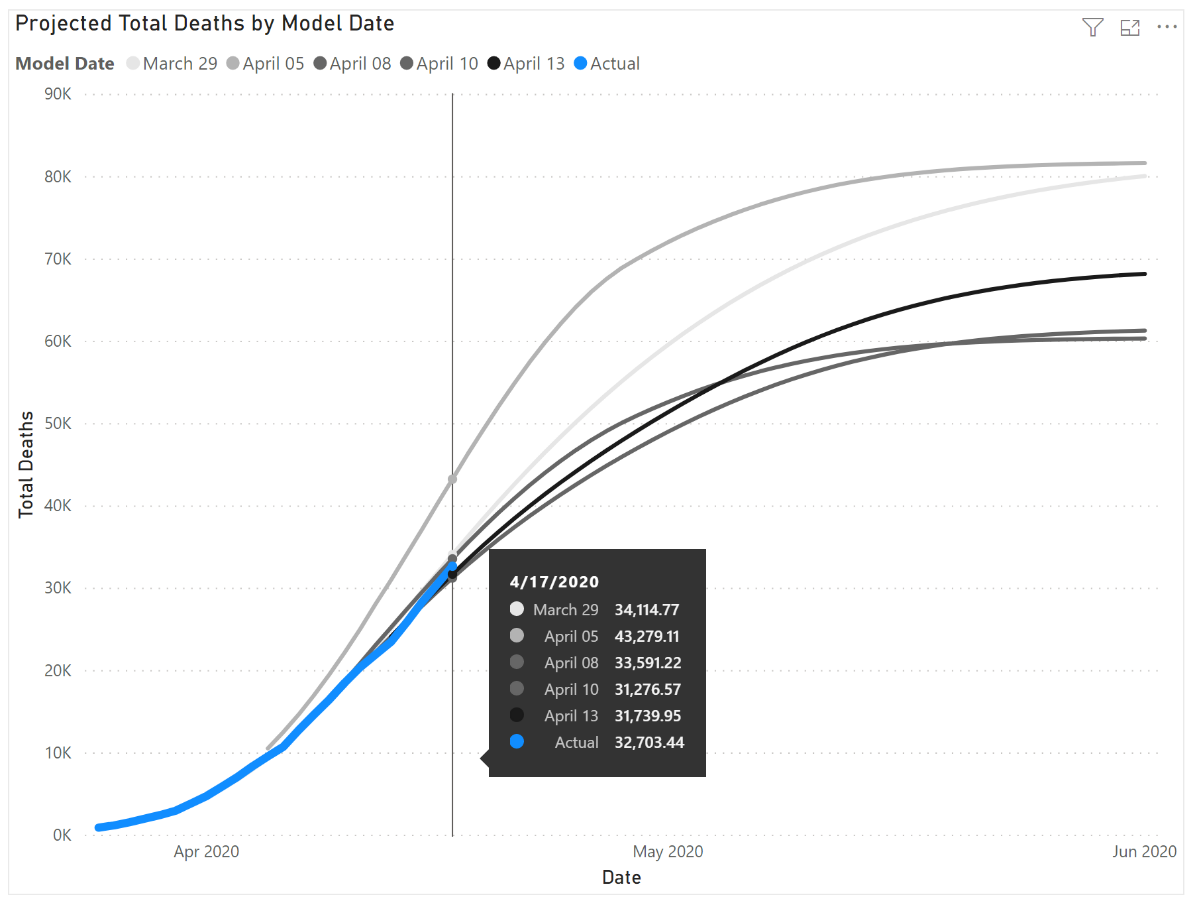
In the graph, the information box shows the dates of each analytics generation and their increasingly more accurate predictions.
How COVID-19 is UnTaming Data Science
In the last decade, there has been an explosion of analytics embedded into everyday processes. Resource management systems automatically place orders when inventory analytics detect that current (or anticipated) holdings fall below a certain threshold. Human resource analytics assess and report the turnover risk of key personnel (like nurses). Remote monitoring analytics assess biometric telemetry to predict near-term outcomes for patients with complex cases. Emergency department utilization analytics detect rising patient loads in real-time, triggering staff surges to meet increasing demand. Condition management systems scan populations for tell-tale signs of precursors to chronic diseases. Analytics are deeply woven into the fabric of health care delivery.
Across the globe, these carefully crafted analytics are dutifully sounding alarms as they detect that operations are currently outside normal limits. However, their warnings go unheeded and alarms are summarily silenced because the world they were made to monitor and evaluate has been greatly altered by COVID-19. Their assessments no longer apply to the current state of the processes that they inform.
Many of these analytics were developed and are maintained using a traditional machine learning methodology consisting of five-step cycles:
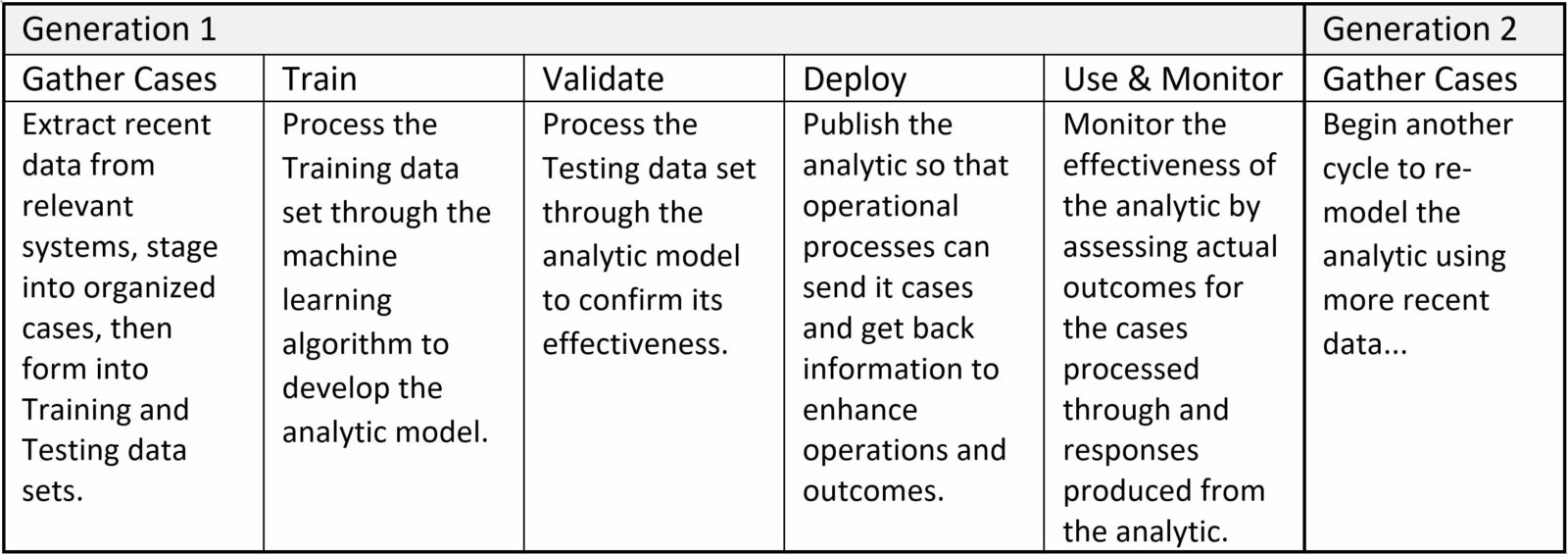
Under this process, the effectiveness of the analytics is based on the foundational premise that the past is a good indicator of the future. Consequently, analytics can be less effective over time as conditions change due to the (hopefully) positive impact of the analytic or for other external reasons. This is true for many pre-COVID-19 analytics: the cases used to train and validate the analytic models is not indicative of the current state, thus they are producing erroneous responses that do not lead to the intended increases in the effectiveness of operations or outcomes.
Many organizations must simply “work around” these current disruptions to their operational analytics, waiting for the time when we are past the immediate crisis and things will return to “normal”. But the Big Question is: What will “normal” look like then? Are the lessons we learn from this crisis likely to introduce lasting, structural change to core processes? Increased telemedicine utilization would alter time and place of care delivery. Preparedness policies would change how we provision for large-scale events. Communications channels could expand and increase in responsiveness. Advance detection algorithms would provide more advanced notice that events were upon us. Many of the changes may be an acceleration of existing trends, while others might be completely new paradigms for care delivery.
It is a unknown how the many pre-COVID-19 analytics will fare in the “new normal”. While some will be unaffected and others require only minor updates, many may no longer be fit for their original purpose – a “mass extinction event” for analytics driven by rapid and drastic environmental change resulting from COVID-19!
Many organizations may struggle to remedy the many simultaneously mal-operating analytics due to their number and complexity. And while the situation persists, organizations and those they serve will suffer both the original and emerging inefficiencies that led them to adopt these analytics in the first place.
Adaptable Analytics – Survival of the Fittest
Taking a lesson from biological systems, species that can adapt to changing circumstances will thrive while species which are less adaptable will not. This is true also for analytics – those which can adapt more readily to changing circumstances will be more effective in improving operations and outcomes.
How can analytics be made more adaptable? In the Traditional machine learning methodology, analytics are monitored for continued effectiveness and periodically replaced as their effectiveness wanes. The cycle time to detect and address reduced effectiveness of analytics can itself contribute to overall reduced effectiveness. A proven variant of the Traditional machine learning methodology, Continual Learning, can be used to create analytics that are more effective and resilient in changing circumstances.
Continual Learning Analytics
Traditional machine learning methodology uses serial cycles of model development to implement successive generations of an analytic. Continual Learning methodology expands on the Traditional methodology as follows:
- Re-modeling of analytics is continuous and automatic
- Training and Testing data sets for each generation are a combination of prior generations’ historic and live cases from Monitoring
- Multiple generations of an analytic can be live simultaneously, with configurable case distribution logic determining which cases are processed by which generation(s)
- The current generation in development is virtually in continuous “pilot” mode since its responses to live data are assessed whenever it is (re-)validated
- Older generations are soft-retired by case distribution logic that considers Monitoring results to determine that cases are no longer processed through older generations
Continuous Learning analytics are developed using parallel machine learning cycles:
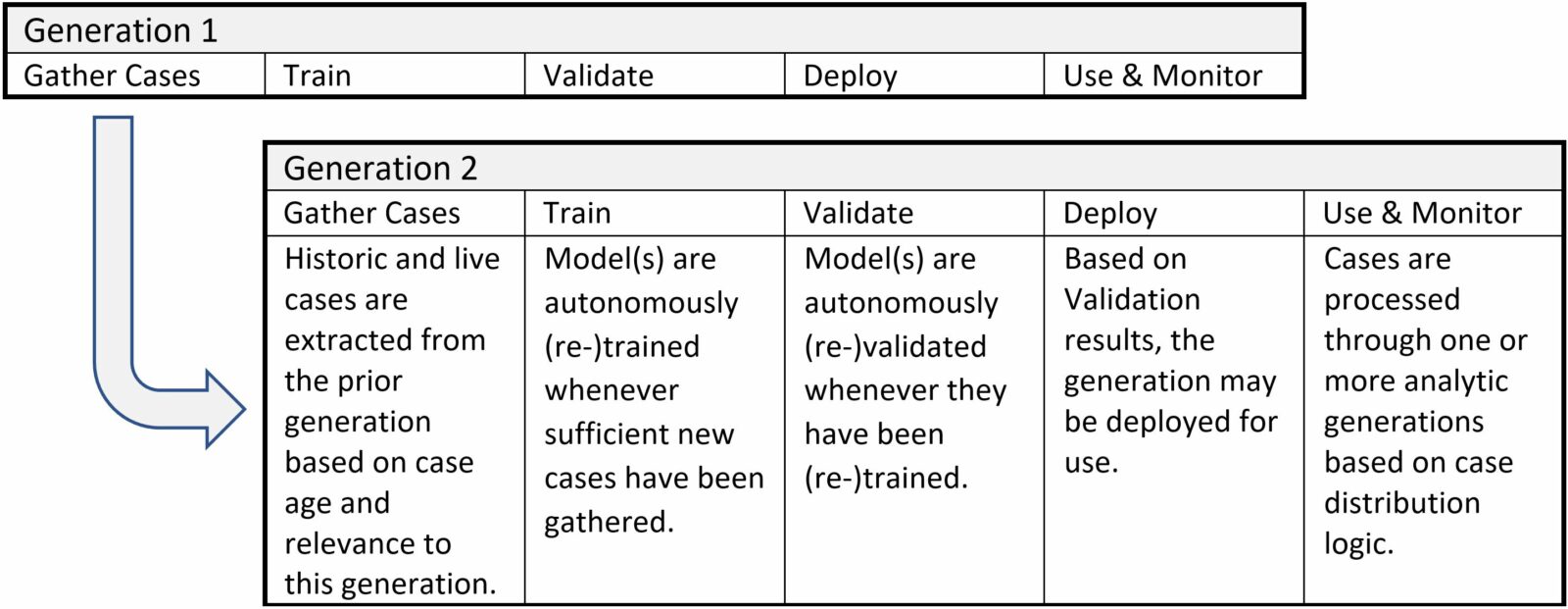
One or more previously published, live generations are selected to process live events, while a current generation in development extracts both historic and live cases from prior live generations to support Continual Learning. Thus a typical journey for a live event through the Continual Learning analytic is:
- An event is routed by a requesting process to the analytic for insight
- The event’s contextual details are considered by the analytic’s configurable case distribution logic to select which generation(s) of the analytic will process the event, and then a selected generation processes the event to add a calculated insight computed using the analytic’s models
- The event and calculated insight are returned to the requesting process for further action
After some time, the outcome of actions taken based on the calculated insight will be evident. Then:
- The actual outcome of the event is gathered from operational systems by the analytic’s Monitoring logic
- The event, its prior calculated insight, and actual outcome are staged into an organized case
- The case is assessed by the analytic’s Monitoring logic for effectiveness and reported
After sufficient cases have been staged:
- The current generation in development considers each case’s contextual details and may select the case for Training or Validation for the current generation in development based on its age and relevance
Continual Learning Illustration
When the nature of cases changes rapidly, analytics implemented with Continual Learning can be much more accurate than analytics implemented without.
The example below depicts daily mortality rate projections using two custom COVID-19 analytics developed in Power BI:
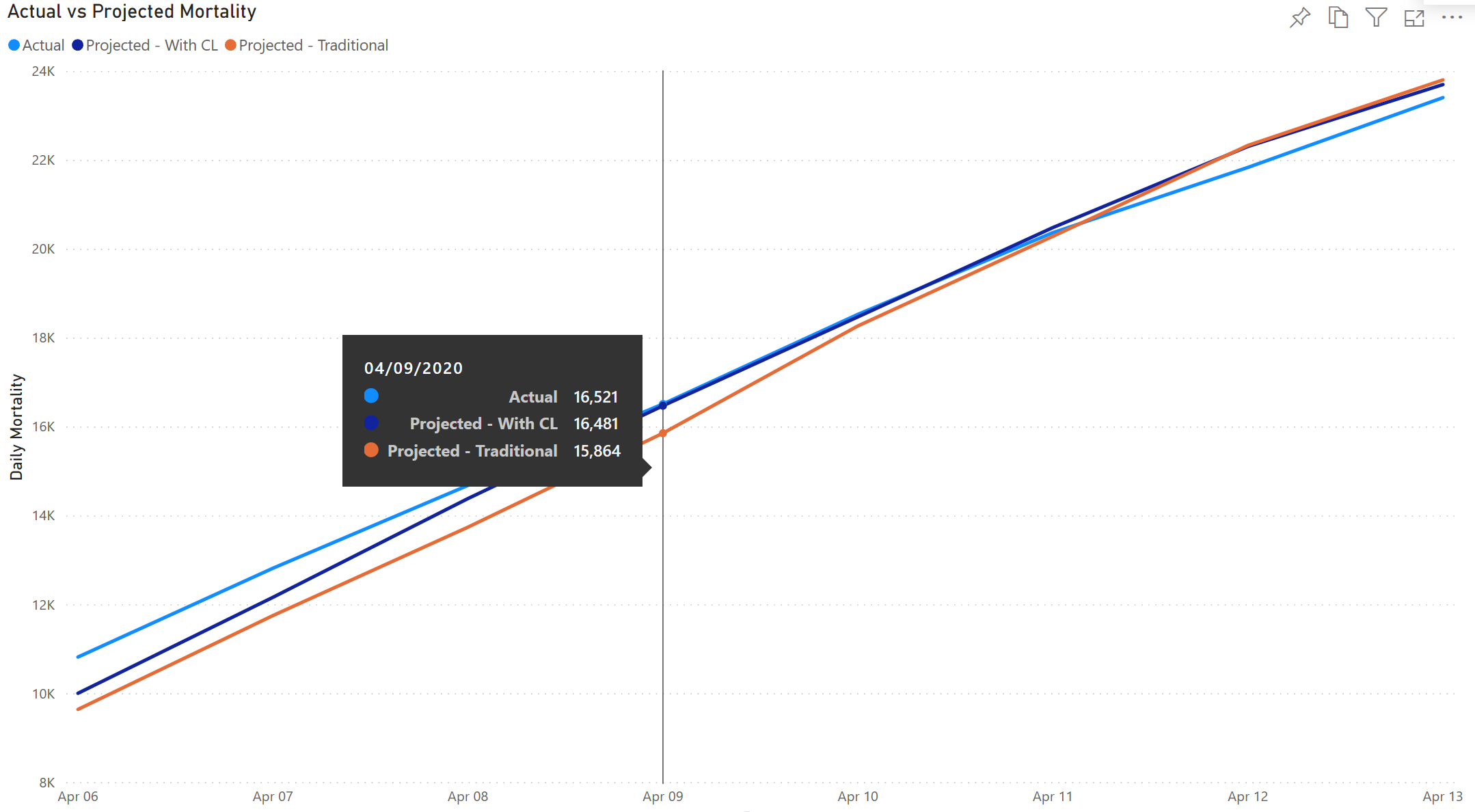
Each of the two analytics accumulates expected mortality across 2,637 independent county-level mortality models to project overall mortality. One analytic uses a Traditional machine learning methodology (orange line), while the second uses Continual Learning (dark blue line). The Continual Learning analytic is autonomously re-modeled daily and its projection is consistently closer to the actual mortality (light blue line) than is the projection from the Traditional machine learning analytic that is re-modeled weekly. For the specific values called out for 04/09/2020, the difference is most dramatic.
Summary
COVID-19 reminds us that models are only as good as what goes into them. And as real-world conditions change, our analytic models must be updated to reflect those changes if they are to be effective. The widespread impact of COVID-19 has impacted many analytics, creating a need for widespread updates. These updates are neither free nor easy, and many organizations will lack the resources to make timely updates to them all – especially as we are in a period where they may require ongoing update as COVID-19 continues to alter real world conditions. So our finely tuned processes that have come to rely on our valuable analytics may be chaotic for a time.
An important lesson for analytics managers and machine learning practitioners is that in order to mitigate the impact of changing conditions on our analytic-enabled processes, we should strive to make our key analytics change-ready through Continual Learning so that they easily adapt to changing conditions.



