
The ability of computers to process tabular and numeric data is unequivocally an essential part of industries today. However, while being able to process massive amounts of numeric data in a matter of minutes is critical, human beings’ general mode of communication is not expressed as a table or number, but rather as words and sentences. Crucial information can be discovered in the type of unstructured data we produce through language. Whether the goal is to analyze written responses and reviews or process and classify documents, being able to gain insights swiftly and accurately from text can drive better business decisions. Natural Language Processing (NLP) is a branch of AI that’s goal is to increase computers’ understanding of the human language.

Unfortunately, without domain knowledge, NLP can be challenging to implement in open-source programs. For instance, in Python there are a wide variety of NLP libraries (Natural Language Toolkit, spaCy, Gensim, etc.) that all serve different functions and purposes with associated pros and cons. Determining which library to use and then what parameters the model requires can be time extensive. Azure Cognitive Services, which are cloud-based services that enable Rest APIs, aids in remedying these issues by providing an out of the box Text Analytics API that conducts NLP over raw text.
The set up for Cognitive Services is fairly straightforward. Once the resource is created within the Azure Portal, service keys and endpoints are generated that are then used to send the Text API requests. The Text Analytics API includes four main components: language detection, sentiment analysis, key phrase extraction, and named entity recognition. This blog will demonstrate each of these functions within a Databricks notebook through an Amazon text reviews use case.
Formatting Data
For all Text Analytics functions the data must be in the json format of {‘id’: ‘text’}. In this example, the raw data is read into Databricks as a dataframe:

Mapping functions within Databricks are then used to compile the dataframe into a dictionary and then json format:


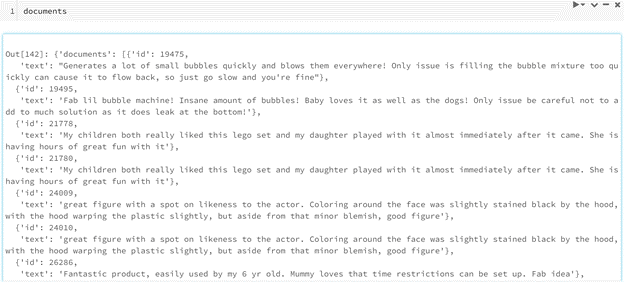
This results in the final data structure below:
Language Detection
Amazon review data can come in a variety of languages. The ability to detect the language being used can lead to valuable insights in the demographics of customers.
As mentioned above, the requests are sent using the endpoints and subscription keys located in the Azure Portal. To access the specific Text API needed, the corresponding string is simply appended to the main endpoint.

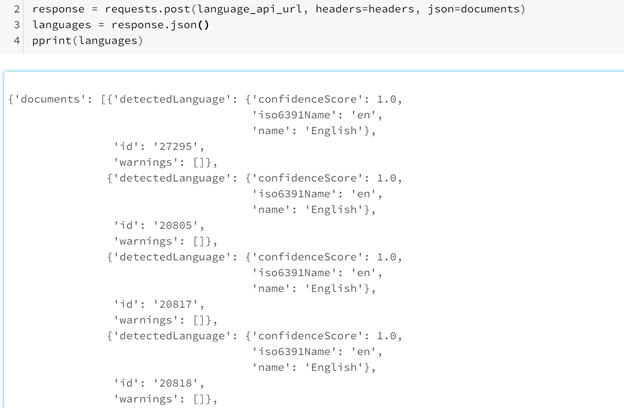
The language detection feature of the Text Analytics API then evaluates the input for each document and returns the confidence score, abbreviation name, and full name:
Sentiment Analysis
Another key insight that can be gained from text reviews are whether the review is positive or negative. Knowing which products are meeting and which products are failing customers’ standards can indicate to businesses which products need reevaluation.
To access the sentiment feature, the sentiment endpoint is simply appended to the main endpoint in the same manner as the language url:

The output from the request contain sentiment labels and scores for the overall review as well as each sentence within the review. For example, the review below is comprised of two sentences. Each sentence is analyzed for a confidence score with the first sentence being more positive than the last sentence. The overall confidence score is judged to be positive.

Key Phrase Extraction and Named Entity Recognition
Finally, being able to identify and categorize key words can be useful for understanding the main point of a review as well as performing clustering analysis. Sending a request to the Key Phrase Extraction endpoint returns a set of main phrases found within the review. In the example below, the key phrases found in a review pertaining to a computer game include ‘year old son’ and ‘coding’.


To take this analysis a step further the Named Entity Recognition endpoint can be used to categorize important elements found in the review. The same computer game review from above contains Quantity, PersonType, and Skill categories:


Overall, while the Text Analytics API within Cognitive Services may not provide as many customizable options as an open-source NLP library, it does provide users with an easy to implement program and easily understandable results.
BlueGranite’s expert data and analytics consultants can help you get a grip on your data and propel you toward success. Contact us today with questions or for help.



