
Many business decisions need to be made with incomplete information, and require managers to plan for uncertain outcomes. If implementing a new inventory policy has the promise of reducing holding costs across the enterprise by $10 million over the next 2 years, what’s the chance the savings will be exactly $10 million? Well, it’s about zero. Would a manager’s decision to move forward with the initiative change if they were told there’s an 80 percent chance of saving more than $10 million? What about only a 50 percent chance? How about 10 percent? Incorporating measures of uncertainty can be tremendously helpful for decision makers. Unfortunately, many analytic techniques produce very deterministic, or single point, estimates (e.g., “Our model predicts exactly $10 million in savings!”). In a recent project, we applied fuzzy logic to a common machine learning technique – clustering – to provide probabilistic information for inventory management.

For many organizations, inventory management policies can vary by groups of products that are similar. This could mean they come from the same distribution center, have similar sales patterns, require the same cost or effort to produce, etc. But across many product attributes, it can be challenging to define what makes products “similar.” Applying an inappropriate policy, as might happen when associating an item with the wrong group, can be tremendously expensive, especially when inventory or stock-out costs are high.
The machine learning task of clustering is a common way to find hidden structures in data, namely which data points are more closely related to certain points than others – or groups. Examples in industry include customer segmentation for targeted marketing, image processing and recognition, and patterns of gene expression in bioinformatics. The objective in this project was to use clustering to help identify groups of similar products across several identifying characteristics, and fuzzy logic to pinpoint items that may not currently belong strongly to any one particular group. This was done in support of a supply chain management group that wished to get deeper insight into product relationships for inventory policies. By having a prioritized list of items that do not strongly associate with one particular group, managers can easily keep an eye on a subset of products that may hold higher potential savings, or require a hybrid management policy.
To illustrate an application of fuzzy clustering, we created an example using the classic Iris data set and performed analysis using the R statistical programming language. The Iris data consists of 150 observations, and 4 features. In a supply chain context, these might represent average periodic sales volume, holding cost, stock-out cost, and shelf life. We’ll set the number of clusters (K) to 3. The values have been normalized since they are on different measurement scales. The R code is here.
Figure 1 shows the original values in 2-dimensional principal component space (a technique to represent multiple attributes in a compact number of dimensions). We can see a clear separation of values along the left side. But what about the products on the right? How can we group them?
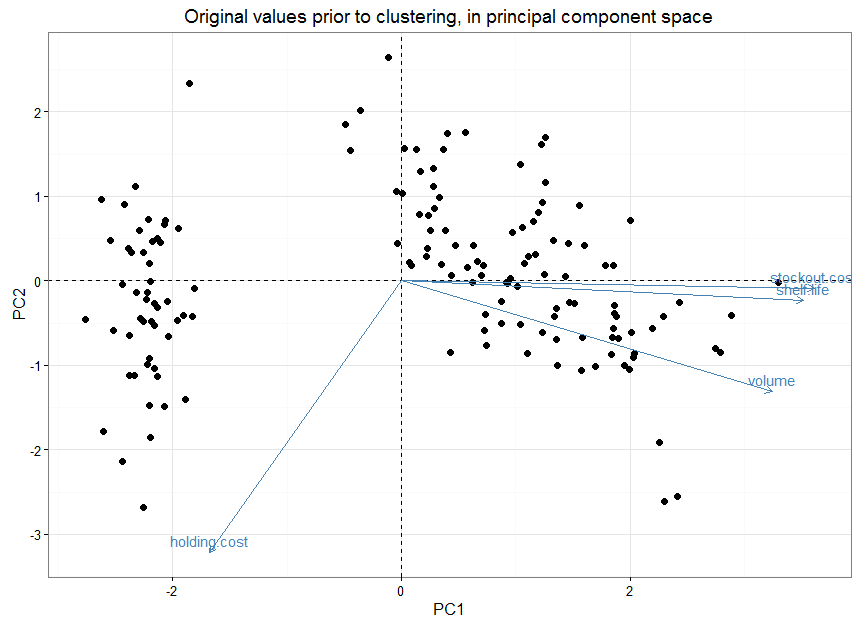
Figure 1
Figure 2 illustrates the 3 K-means clusters. Using a distance calculation, K-means performs multiple iterations to calculate the best group for item membership. Using fuzzy K-means, we also have the benefit of understanding the degree, or probability, of cluster membership. Larger dots have a stronger membership; smaller dots have a weaker membership. Notice that dots near the perimeter of clusters are smaller; there is less certainty to which cluster they belong.
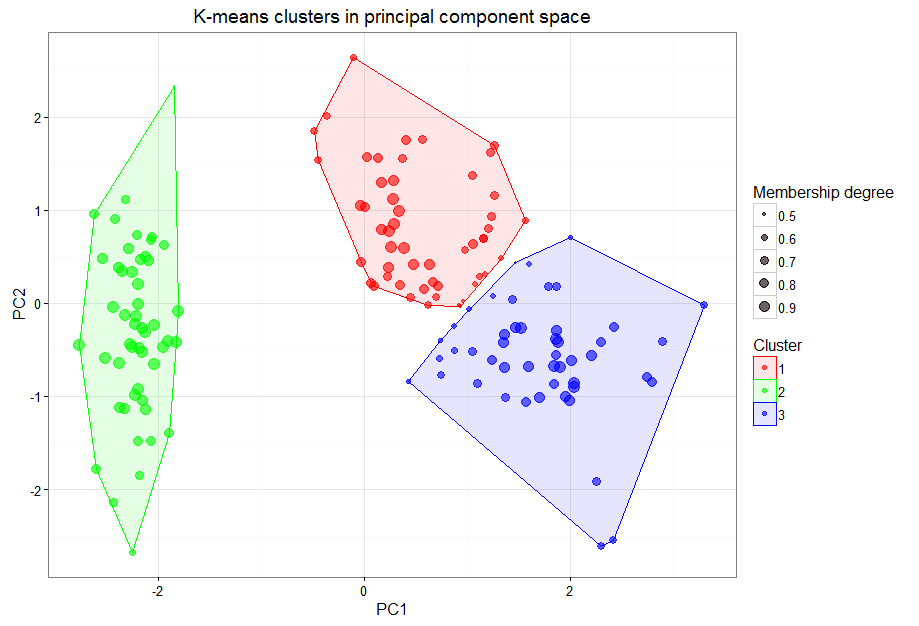
Figure 2
Figure 3 adds a fuzzy cluster according to a given membership threshold. In this case, any item in clusters 1 or 3 that does not have at least a 60 percent membership degree in its primary cluster falls into the “fuzzy” category; these are items we want to watch more closely – they may be special cases or likely to move from one cluster to another.
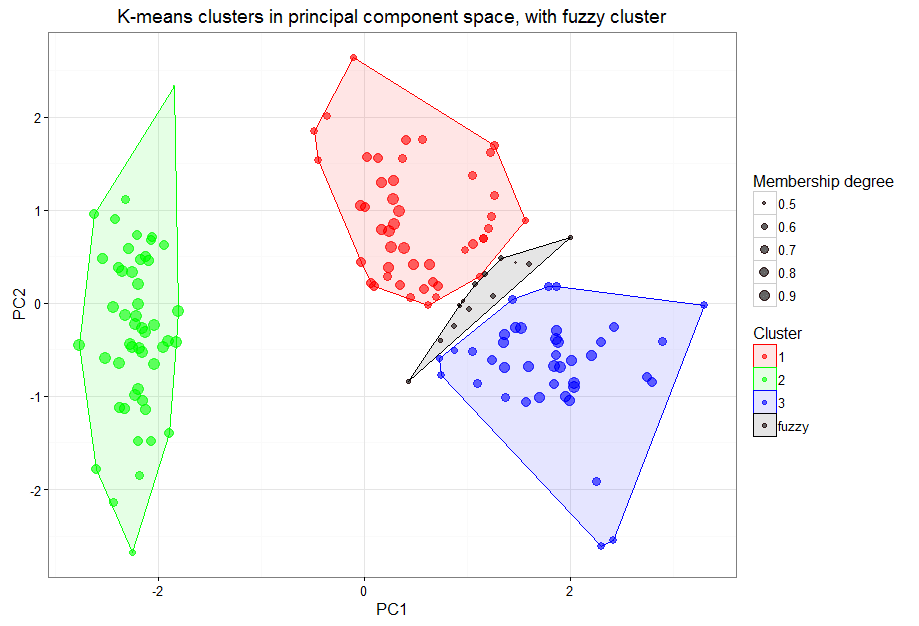
Figure 3
Figure 4 shows the item numbers of the fuzzy cluster and a summary table, where we can more closely inspect the items in the fuzzy cluster as well as all other products according to their cluster membership. Using the fuzzy clustering results, as well as a discovery tool like Power BI, would allow an even deeper dive into the data.
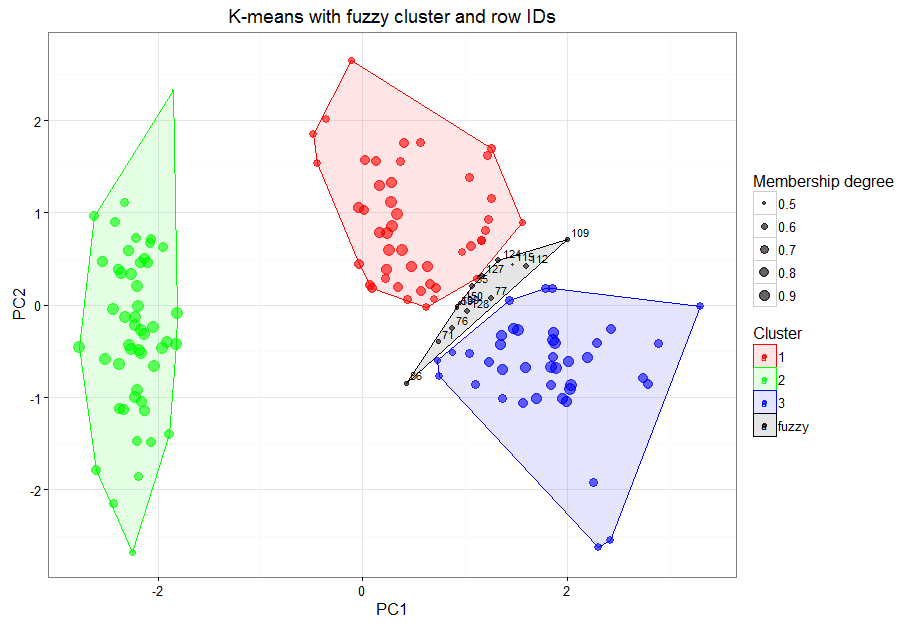
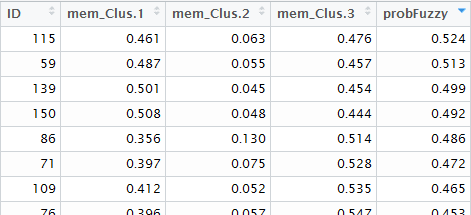
Figure 4
For those of you wondering about the smaller dots on the perimeter of all the clusters, these items have small membership degrees because they may represent outliers. The ‘fclust’ package used in this example also has a function to detect and create an ‘outlier’ cluster for anomaly detection!
Fuzzy clustering represents an excellent way to visualize statistical groupings of data and also highlight items of interest that might need special attention. R, a platform designed especially for analytics, makes this easy. For more information on advanced analytics, be sure to check out the helpful resources on our Microsoft R landing page and our webinar on text analytics.
If you have questions or need assistance with an advanced analytics project please contact BlueGranite today.



