
I’d like to tell you about a newly announced feature called Static Data Modeling. This feature is not exclusive to Azure as it’s available with both Azure SQL Database and SQL Server on prem. I had a chance to try out this interesting feature and wanted to share my experience.
At this writing, to use Static Data Masking, you do need to use SQL Server Management Studio 2018 Preview #5; this feature is not available in any earlier versions. It is something you enable through management studio.
In the past we’ve had Dynamic Data Masking where you could set up a policy such that when a certain user would query a field that may have sensitive information, you could mask the underlying data with some other characters, such as masking a social security number with a string of x’s.
The key to note is with Dynamic Data Masking, the underlying data does not change but with Static Data Masking, it alters or updates the data in your database. The way it works is you’re creating a copy of your database and then applying updates that modify the data in your database, so it’s quite different from Dynamic Data Masking.
Why would you want to do that? Well certainly, this is not something you would apply on your live production databases but let’s say you have a team that needs to do some performance monitoring or test performance improvement on the database. To do this they would need a full copy of the live data with all the latest indexes and stats and you often need your full database to do that.
If you apply the Static Data Masking to a copy of the database, the team doesn’t have access to the sensitive info, but does have access to the full structure, data volume, etc. that they need.
Again, this is an update, not some type of encryption that you can decrypt and go back to the original value. Once you’ve masked that data, it’s masked, and you can’t change it.
Let me show you how this works. As I stated, this is implemented through SQL Server Management Studio. Look at the screenshot below. This is something you enable at the database level. I right-click the database and choose the tasks. In my version, I chose the option marked as a preview of mask the database.
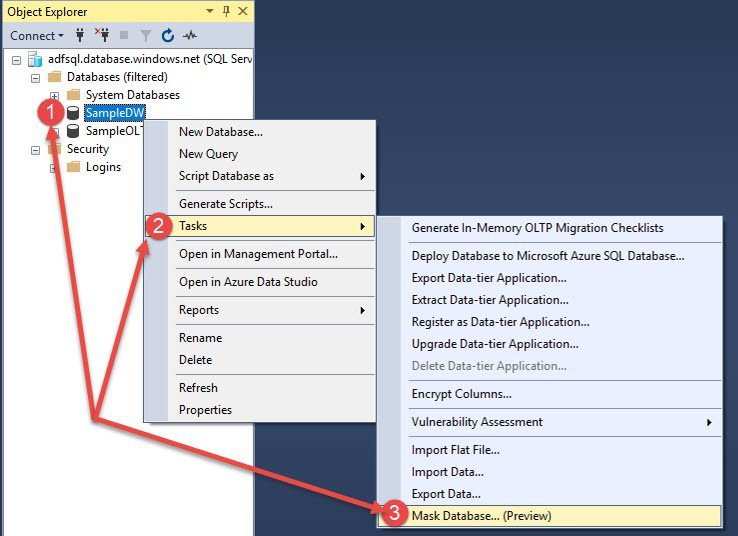
This next screenshot shows the configuration box of how you set up the masking. In this case, I selected one field and one table. In the drop down, I’ve shown the different options you have for how to mask the data.
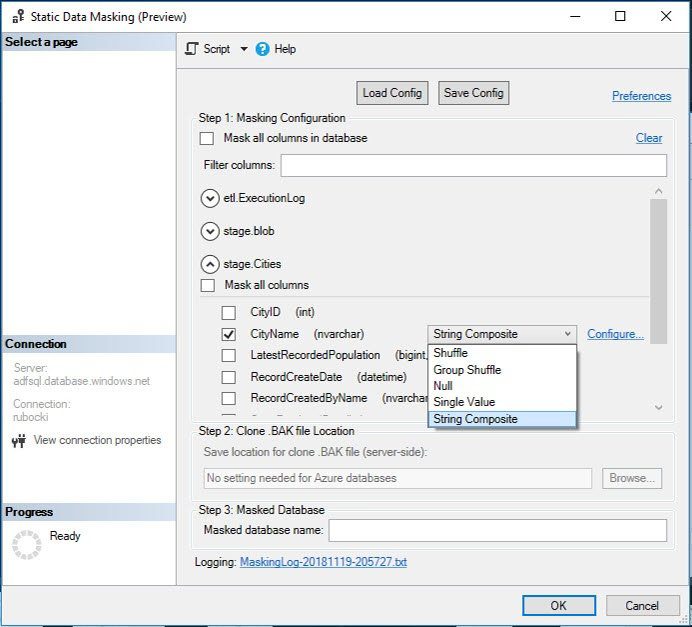
I selected a neat option called the string composite, which worked well, and you can do all kinds of regular expressions inside there. You have a lot of flexibility in how you want to mask data. The shuffle and the shuffle group will choose different values from your data and mix it up.
You’ll also see an option at the top for saving a configuration, a nice feature where if you’ve set this up with many fields you want to mask, you can save that configuration and use it later.
Once you’ve chosen the fields you want to mask and how you want them masked, simply click OK and it will kick off the process of creating a back up if it’s on premises, then applying updates. Or if it’s in Azure SQL Database, it will create a clone of the database and then perform those updates on the clone.
This could take a few minutes or more depending on the size of your database. You’ll see a message that the masking is complete if it’s successful.
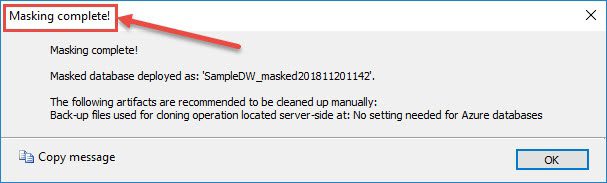
So, a great feature to try out with some definite benefits. If you have any questions about Azure Data Platform, data warehousing or anything within Azure, we’re here for you. Click the link below or contact us – our Azure experts would love to help.



