

For many beginners, learning to code for a data science project can be just as intimidating as flying a Boeing 757 for the first time. Fortunately, Python offers a myriad of powerful libraries to get us beginners quickly into the cockpit to do some cool analyses. One of such Python libraries is Textblob, which provides a simple API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, and much more.In this blog, we are going to learn how to write a simple python program that performs sentiment analysis of Martin Luther King, Jr.’s ‘I Have a Dream’ speech and writes the results to a .csv file.
Before we hit the throttle and leave the runway, I want to give a brief background of myself and how 3Cloud cultivated my interest in data science. I started at 3Cloud fresh out of college in the summer of 2017. Having no professional experience in neither consulting nor data science, 3Cloud put me through their consultant boot camp—a rigorous 3-week program that covers the ins and outs of consulting, data warehousing, cloud services, data modeling, advanced analytics, and many other tools and soft-skills that every employee needs to succeed. The experience was immensely useful and enjoyable, but one of the courses that really grabbed my attention was the course on advanced analytics.That course was my first introduction to python as a data science language. Our instructor, Ahmed Sherif, gave us real data sets to work with and really pushed us to “think in python”.By the end of that 2-hour session, I knew that I wanted to do some more cool analyses with python, which led me to write the program I’m about to walk you through.
So let’s get started, shall we?
First, I chose to use Notepad++ to write my code, but feel free to use whatever IDE or text-writing tool you’re comfortable with (FYI Jupyter is great if you’re a beginner).

In lines 4 and 5, we are importing the Textblob and csv libraries.The former is how we will invoke the NLP sentiment analysis functions.The latter is how we will invoke the functions necessary to write our sentiment analysis results to a .csv file.

In line’s 9 and 10, we have declared two file path variables. File_path is the location of the “I Have a Dream” speech and sentiment_csv_path is the [eventual] location of the sentiment analysis results .csv file.

In line 15, we create array fieldnames that will be used to populate the headers of our .csv file. A quick note about each of these 5 headers. Sentence_ID represents a unique identifier number to identify each sentence of the speech. Polarity and Subjectivity represent the respective sentiment analysis scores for each uniquely identified sentence.Sentence is to be populated with the text from each uniquely identified sentence. Lastly, Strong Opinion? is to represent a Boolean value (0=F, 1=T) if the program determines a sentence to be a ‘strong opinion’—I’ll elaborate on this shortly.

In line 19, we declare the sentence_ID variable which is set to 0. It will later be incremented as the program traverses the text file and identifies each sentence.

In lines 22-25 we do three things.Frist, we create the .csv file in the file path location stored in sentiment_csv_path. Then, we write the headers to the .csv file with the array fieldnames. Then finally, we close the file.

Lines 29 is where we open the speech file found in the location stored in file_path.Line 30 read the open speech file through the TextBlob library.

Line 33 takes the open speech file and splits it up into sentences.
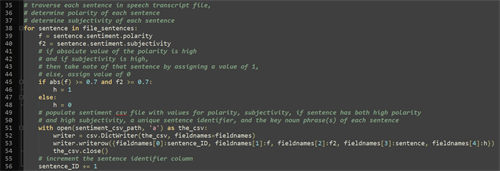
Now we get to the meat and potatoes of this program. Line 38 is the beginning of a for loop that loops through each sentence of the speech file. Lines 39-40 assign polarity and subjectivity scores to a sentence coming in from the speech file.
Then in lines 45-48, the program determines if the sentence is a strong opinion based on the polarity and subjectivity scores—If the absolute value of the polarity is greater than 0.7 and the subjectivity is greater than 0.7, then assign the sentence a value of 1 (true)—Otherwise assign a value of 0 (false).
Lines 51-54 open up that .csv file once more, then populate it with data corresponding to each of the 5 headers (Sentence_ID, Polarity, Subjectivity, Sentence, and Strong Opinion?).
In line 56, we reach the end of the loop.If there is another sentence to be processed, sentence_ID is incremented by 1. Once there are no more sentences left, the loop completes (breaks).

Finally, once the program has looped through each sentence of the speech file, analyzed it through textblob, and published the results to a .csv file, we close the file in line 59. Although you’ll still be able to view the complete results if you skip this step, it is still a programming best practice—especially if you need to access the speech file later in the program via a different library.

Once your program successfully completes, you should be able to open the .csv file (I opened in Excel here) and have all the analysis results for easy consumption.Now that the results are neatly organized onto a .csv file, there are a multitude of options to store, consume, and creatively visualize this data!
To those of you reading this post who are new to programming and programming for data science—I hope you’ve found this post as helpful and maybe just as inspiring my first exposure to it in 3Cloud’s consultant boot camp.
To read more on our capabilities, get in touch today.
Editor’s Note: The post was originally published in [January, 2018] and has been updated for freshness, accuracy and comprehensiveness.



