
We are all looking for ways to save time, right? Today, I want to tell you about a time saving feature of the Azure Data Factory Copy Activity called Implicit Column Mapping.
What this does is if you were pulling data from a source data set and loading it to a sync or target data set and those two data sets have the same column names, you do not need to define the schema or map the columns from your source to your destination – with the Azure Data Factory Copy Activity, it will handle all that for you.
This allows you to use a single copy activity and re-use it simply by changing the connections properties or locations of your source and your destination. A couple of examples:
- If you were extracting data from a file in Data Lake and loading it to a table in SQL Server and the columns of the file in Data Lake and the table you’re loading to are the same, all you have to do is define the file you want to extract from and the table you’re loading to and the Azure Data Factory Copy Activity takes care of the rest.
- If you have a number of files in Azure Data Lake, possibly in different folders but all have different structure, and you’re mapping them to a corresponding set of tables in a database that also have varying structure but there’s a one-to-one between the file and the table, you can use that single task repeatedly by changing the names of the connections and it will map this automatically.
If you’re developing in Azure Data Factory and you’ve got a repetitive pattern this is a powerful and time saving tool.
In contrast, if you’ve ever used integration services, you know that with a data flow task, you’d have to map columns from your source to your destination. If the columns matched, the designer would help you do that automatically, but you’re left with explicit column mappings and you couldn’t really use the same data flow task to load data sources of varying structure.
But you can use the same task to load data files with varying structure in the Data Factory Copy Task.
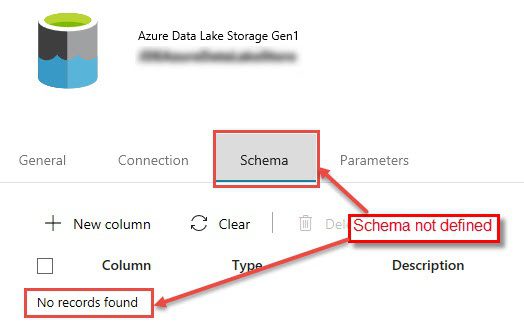
Part of the trick is when you’re defining your source and sync data sets, you do not need to define the schema (see graphic below). You can define the schema if you want but if you know the source and target column names are the same, you do not need to do that.
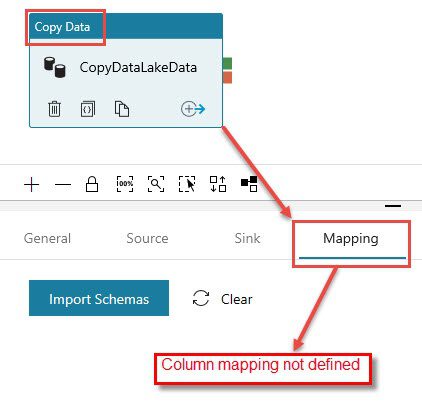
In the screenshot below, you’ll see this is the same with mapping – you do not need to define the mapping if your target and source columns are matching.
So, with the Implicit Column Mapping feature in Azure Data Factory, it’s that simple.
Need further help? Our expert team and solution offerings can help your business with any Azure product or service, including Managed Services offerings. Contact us at 888-8AZURE or [email protected].



