
The heart of any retail analytics solution is product data. Retail and CPG organizations need the ability to model and load complex product granularities, attributes, and relationships in order to fulfill valuable analytics, visualizations, and Artificial Intelligence (AI) capabilities. These requirements often materialize into the Product dimension in the organizational Data Warehouse.
The Azure Data Services provide a rich and robust set of tools for modeling, loading, and maintaining product data from various data sources. With such a wide variety of options and a lack of official documentation on best practices, it can be confusing to know which tools and patterns to use to load your Data Warehouse in Azure. The purpose of this blog post, and the subsequent ones to follow, is to help provide clarity on this topic. In each post, we’ll review the tools and patterns to load your product dimension.
3 Simplified Patterns
Heavily simplified, there are three Data Warehouse load patterns and tool combinations in Azure to perform ETL/ELT. Each option has its own pros/cons that should be evaluated by organizations to understand the best fit for their use cases, requirements, cost, and staff skillsets.
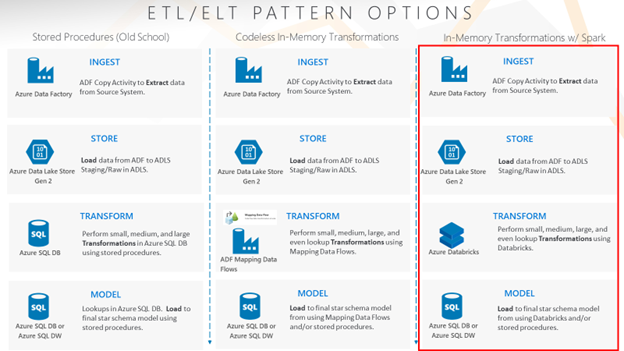
In today’s blog post, we’ll review the pattern and tools associated with what I am calling In-Memory Transformations with Spark. The focus on this pattern is to use Azure Databricks to transform the data in the Data Lake into meaningful data and land it into the Data Warehouse and our Product dimension.
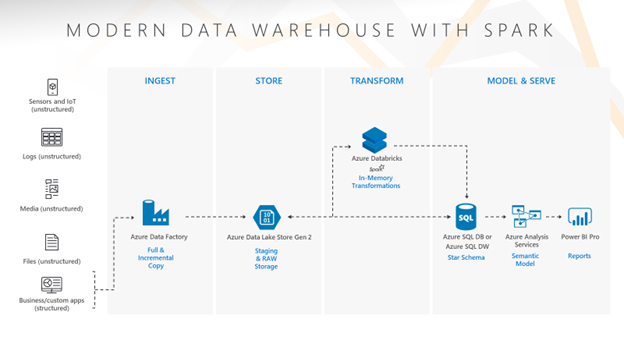
The architecture diagram below outlines the tools used in this pattern and the order/flow of the data.
- Ingest Data using the Azure Data Factory Copy Activity (ADF) – ADF Copy Activities are used to copy data from source business applications and other sources of data into the RAW area of the Data Lake.
- Store Data in Azure Data Lake Store Gen2 (ADLS) – ADLS Gen2 is used to store the data for our Data Lake. It combines the best of Azure Storage and ADLS Gen1 to enable the Hadoop Distribute File System (HDFS) as a service. It is a cheap and robust storage system built for analytics.
- Transform Data using Azure Databricks – Databricks is used to source data from the Data Lake and enhance/transform the data in-memory before landing it into the Data Warehouse star schema.
- Model Data in Azure SQL Database (DB) or Azure SQL Data Warehouse (DW) – Azure SQL DB or Azure SQL DW are used to store the data for the Data Warehouse star schema. Both solutions are SQL Server based and provide an easy consumption layer for business/data analysts and dashboard/report writers. Azure SQL DB is a robust SMP (symmetric multiprocessing) based relational database solution enabling scalability up to single-digit terabyte (TB) sized Data Warehouses. For larger Data Warehouse solutions (single-digit TBs to triple-digit TBs) Azure SQL DW provides an MPP (massively parallel processing) capability based upon SQL Server.
- Serve Data using Azure Analysis Services or Power BI Premium – Azure Analysis Service or Power BI Premium enable a rich semantic layer capability in the architecture. Tables are pre-joined, columns use business vernacular and are organized for ease of consumption, security is embedded into the model, and business calculations are added for analytics.
- Consumption of Data using Power BI – Power BI provides a rich experience to Azure Analysis Services or Power BI Premium via Live Connection. Users can create ad-hoc reports, consume reports and dashboards, and even create paginated reports. Sophisticated authors can even create feature rich reporting solutions that look and feel like a reporting application.
Ingesting Data to the Data Lake
Ingesting data into the Data Lake occurs in steps 1 and 2 in our architecture. Azure Data Factory (ADF) provides an excellent mechanism for loading data from source applications into a Data Lake stored in Azure Data Lake Store Gen2. In fact, Microsoft offers a template in the ADF Template gallery which provides a metadata driven approach for doing so. The template comes with a control table example in a SQL Server Database, a data source dataset and a data destination dataset. More on this template can be found here in the official documentation.
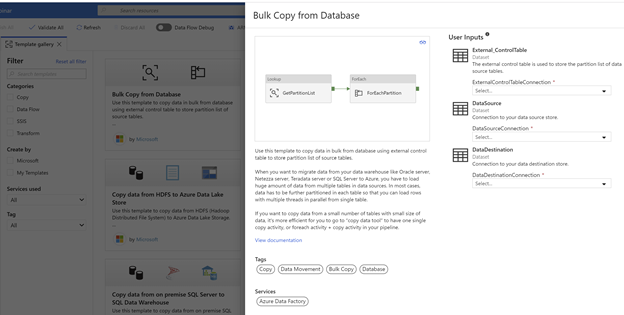
The ADF pipeline starts with a Lookup activity which retrieves the record set from the control table and makes it available to the pipeline. The control table holds records which have the table name, the query to use for filtering the data in the source system, and the destination folder path for the data in the Data Lake. The ForEach activity iterates over the GetPartitionList data set.
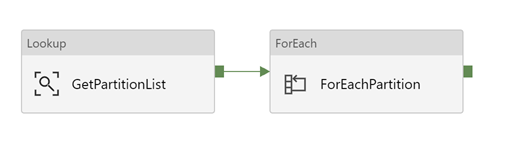
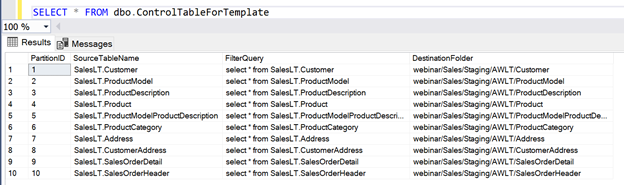
Within the ForEachPartition activity, two Copy Activities execute for each record of the control table. The CopySourceToStage Copy Activity runs the SQL query in the control table against the source system. The results are then loaded to the Staging destination folder location in ADLS which is also provided by the control table. The CopyStageToRaw Copy Activity copies the data from the Staging folder location and moves the data copy to a RAW location in ADLS that is partitioned by a timestamp.
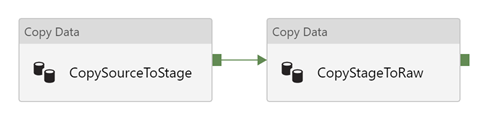 An example of an output directory structure of the Data Lake is below. We can see that after our ADF pipeline completes, our Data Lake has a directory structure that mimics the following topology: storage container -> subject area -> data lake zone -> source system -> table -> table data.
An example of an output directory structure of the Data Lake is below. We can see that after our ADF pipeline completes, our Data Lake has a directory structure that mimics the following topology: storage container -> subject area -> data lake zone -> source system -> table -> table data.
In this example, the data for our tables are stored in Apache Parquet format (Product.Parquet). Parquet file format is useful because it provides columnar compression by default and it stores the metadata of the file in the file itself, which can be used by downstream systems.

In the second Copy Activity, we can see that the data is copied from the Staging zone into a Raw zone of the Data Lake, which includes a timestamp of when the ETL was executed. Subsequent runs will create new folders which will allow the Data Lake to show history in the data.

Loading the Production Dimension with Azure Databricks
Pulling data from the Data Lake, transforming that data, and loading it into the Data Warehouse occurs in steps 3 and 4 in our architecture. Azure Databricks does the bulk of the work for these steps. Before we dive into our ETL code, it’s important to know why we’re using Databricks in this pattern. The following list outlines why organizations should use Databricks for their ETL/ELT workloads:
- Efficient In-Memory Pipelines – Databricks, based upon Apache Spark, is a highly scalable Data Engineering platform that is able to source, transform, and load batch and streaming data using efficient in-memory pipelines that can be scaled out to multiple nodes (MPP). This post focuses on batch loaded data; read this blog to learn about implementing a streaming pipeline using Databricks.
- Connect to Almost Everything – Databricks has connectors for all of the Azure Data Services and can handle structured and unstructured data sources. It can also be used to make connections to relational database management systems (RDBMS) using java database connectivity (JDBC). Many RDBMS systems are supported natively, like SQL Server, MySQL, and MariaDB. You can also add your own JDBC driver for RDBMS systems like PostgreSQL, Oracle, or DB2.
- In-Flight Scalability – Spark clusters can be created in minutes and can be configured to automatically scale up or scale down in-flight and turn off when idle.
- Popular Language Support – Developers can use a collection of languages to complete their pipelines including SparkSQL, Python, Scala, and R.
- Multi Use Case Support – Databricks Unified Analytics Platform can not only handle Data Engineering, but also enables AI, Streaming, and Graph processing using the same solution.
- Pay for What you Need/Use – You only pay for Databricks when a cluster is up and running. Jobs can be created that spin up a cluster, perform ETL, and spin down afterwards to save cost.
The following Databricks Notebook provides a walkthrough/example of how to load a Product dimension table in Azure SQL DW using an Azure Databricks Notebook with code written in Python, SparkSQL, and Scala. The notebook would be executed from a master Azure Data Factory pipeline using ADF’s native connectivity with Databricks. At a high level, the notebook does the following:
- Establishes connections to the Data Lake and the DW.
- Loads the Data Lake product tables into DataFrames.
- Uses SparkSQL to form a source query.
- Loads the DW dimension table to a DataFrame and compares it with the staged data using SparkSQL.
- Updates existing dimension records if needed.
- Writes new records directly to the DW dimension.
Stay tuned for the next blog post reviewing how Azure enables scalable, code-free ETL using Azure Data Factory Mapping Data Flows. And as always, if you need help designing and building your Data Warehouse and ETL solution in Azure, contact 3Cloud.



