
One struggle for genomics research is the ability to analyze the vast amounts of data in an efficient way. Previously, this would have been performed using large, on-premise high performance computing (HPC) cluster jobs. Today, the cloud offers us opportunities to perform bioinformatics analyses interactively and at-scale.
In this demo (see the video at the end of this post), I’ll be showing how Azure Synapse can be used to analyze millions of variants quickly using basic structured query language (SQL) commands. I retrieved >80 million variant records from over 2,500 individuals from the 1000 Genomes Project (Phase 3 release). In its variant call format (VCF) form, this data is about 168GB in size, which encompasses all 22 autosomes, X and Y sex chromosomes, and mitochondrial variants.

What’s Azure Synapse?
Azure Synapse Analytics is a recent amalgamation/rebranding of some services in Azure, including Azure SQL Data Warehouse with connectors to Power BI and other services. Synapse includes serverless pool, dedicated SQL pool, and Apache Spark pool options for flexible and scalable data workloads in Azure.
Learn more about Azure Synapse Analytics here.
This service isn’t marketed for any specific industry, but its immense scalability makes it a perfect tool for browsing tons of genomics data. All we need to do is get our data in a format that’s usable in Synapse.
Converting from VCF to Parquet
VCF files, though popular in bioinformatics, are a mixed file type that include a metadata header and a more structured table-like body. Using the Glow package in Apache Spark, we can convert VCF files into the Parquet format, which works excellently in distributed contexts like a Data Lake or in Azure Synapse.
We can perform this conversion at scale in Spark (either in Azure Databricks or Azure Synapse) using only four lines of code (plus two more lines for calculating optional summary statistics). The following code reads a VCF file from a mounted genomics data lake location.
When this VCF file is read into Spark, it converted into a Spark DataFrame. Then, after calculating some optional summary statistics, the cluster will write out multiple partitioned Parquet files back to the data lake. For the 1000 Genomes data I’m using here, the Parquet format reduces the ~168GB of VCF data down to ~74GB.
External Tables
In Azure Synapse, external tables are a really awesome capability to connect to data that lives in your data lake. Once you create an external table, you can query the data just as if it were a real table in your database. This works on delimited text files (like CSV or TSV), Hive Orc files, or Parquet.
A snippet of the CREATE EXTERNAL TABLE script for VCF data looks like this:
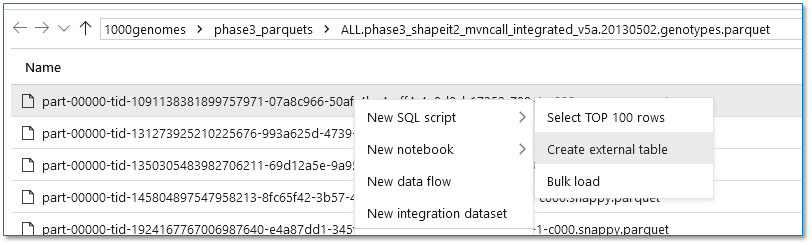
While you could write this yourself, Synapse will help you generate scripts automatically. Find the Parquet file(s) that you want to load, right-click it, click New SQL Script, and then click Create external table. This will generate a basic script, which you should edit to fit your specific VCF file needs. (Specifically, make sure the data types are correct.)
Speedy Queries
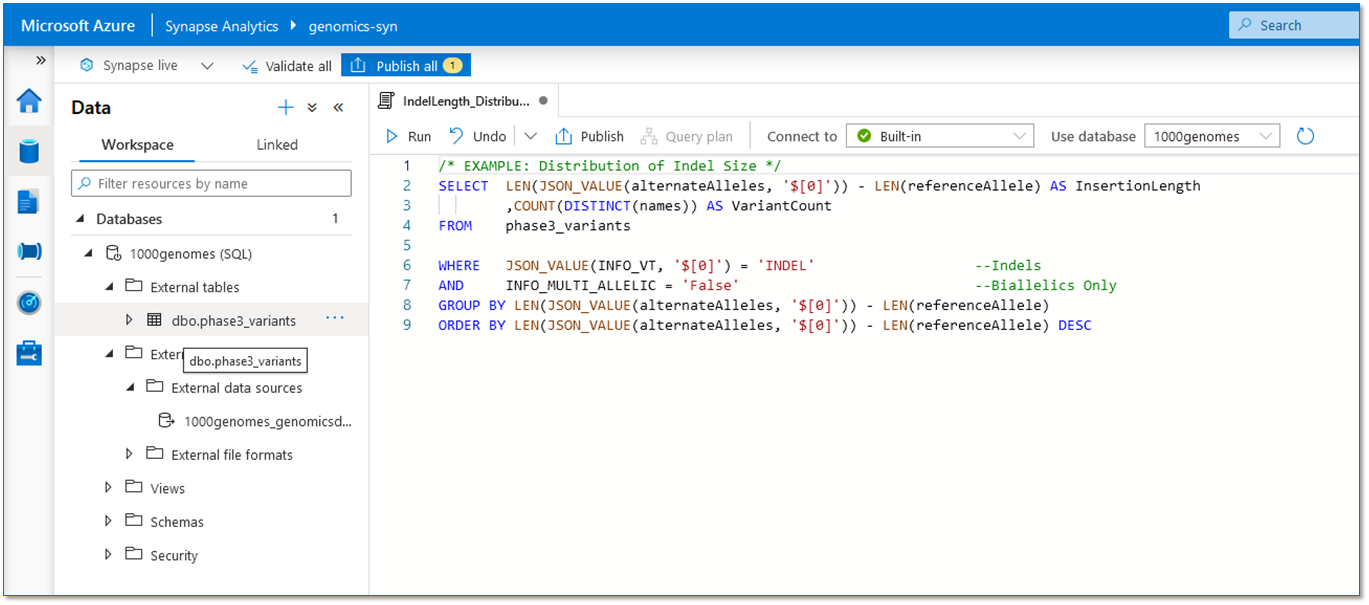
Azure Synapse can perform queries on this data very quickly. In fact, for some of my example queries, it only took a couple minutes to return the results from >80 million variant records. Here are some example queries:
| Sample Task | Query Time (in minutes) |
Find Minor Structural Variants |
1:11 |
Calculate Indel Size Distribution |
1:34 |
Find Motif Matches |
1:49 |
Note: Processing times may vary. These are based on the serverless built-in pool that comes standard with Azure Synapse. If you create a dedicated SQL pool, you may reduce query times even further.
To learn more about best practices around making dedicated SQL pools, click here.
Resources
To view the full demonstration, check out the video below.
How can 3Cloud Help?
If you’re reading this post, you’re probably no stranger to 3Cloud. We have industry experts with experience in both healthcare and life sciences, plus a deep expertise in all things cloud. Contact us today to find out how we can help you with your data and analytics solutions.



