
It’s been almost 2 months since our last post and 2020 is still throwing curve balls, but Databricks and Microsoft are still hitting home runs with technology innovation. If you are a Data Engineer, you need to check out features 3 through 5 on our list below so you can be hitting dingers on your Modern Data Platform projects. Continue reading below for insight into our remaining top MDP features and more cheesy sports lingo.

3) Azure Synapse Analytics SQL On-Demand for Serverless Querying of Data Lake
Being able to tap into data in the Data Warehouse and the Data Lake is key for a Modern Data Platform solution. Being able to easily access data in the Data Lake enables the scalability, flexibility, and speed of delivery components of the Modern Data Platform story. Tools in the Azure Data services have allowed us to do this for some time, but we’ve always had to have compute running (Spark cluster or Hive cluster), which can get expensive and/or administratively intensive. Additionally, it required tooling outside of SQL Server to accomplish the goal, which could feel awkward for some types of users.
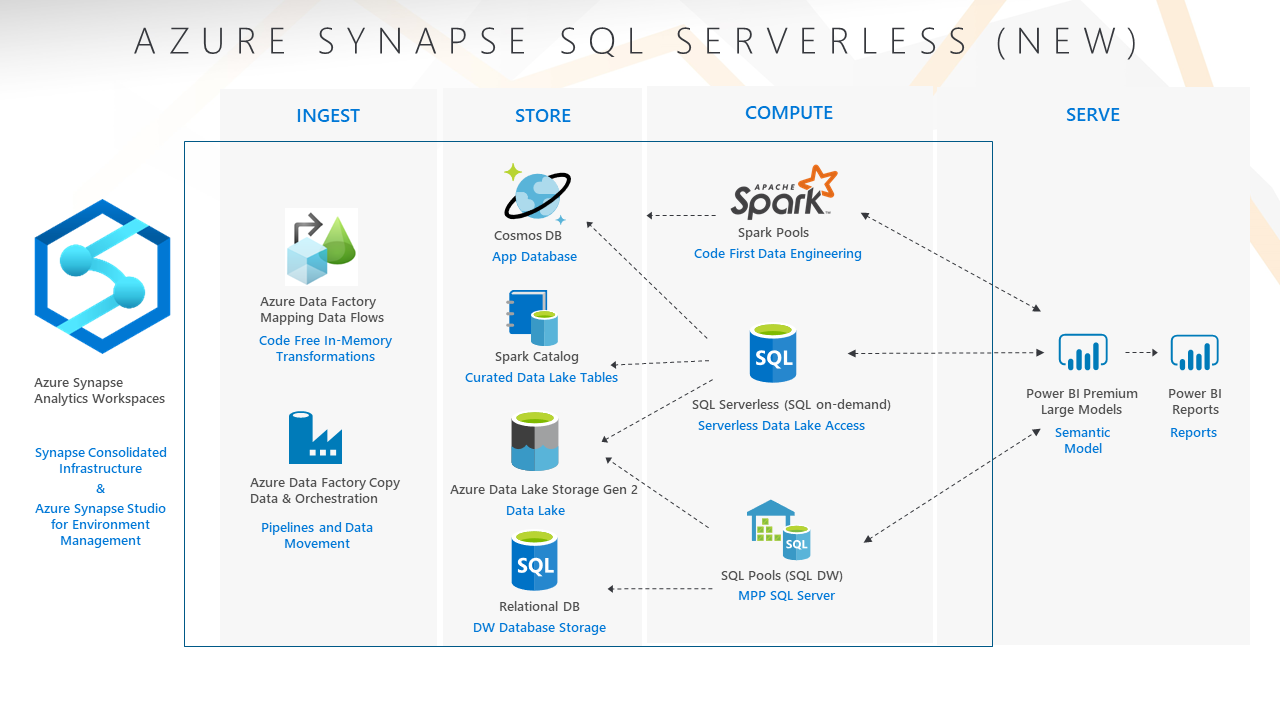
SQL On-Demand is a new tool in Azure Synapse Analytics that allows users to fetch data from the Data Lake without provisioned compute, all while using the same simple process used to get data from the Data Warehouse. This is a complete and total game changer in the Modern Data Platform. Users can use plain SQL in a development tool or the GUI of Power BI to interact with files or tables in the Data Lake. Serverless compute immediately handles their request and the user is only charged for the volume of data that is returned by each query (a rate of $5 per TB – pretty cheap).
While this user experience may seem simple, the tight integration of existing tools and drop in price tag for enabling this capability will drastically enhance the usability of the Modern Data Platform and increase its value to many organizations.
{% video_player “embed_player” overrideable=False, type=’scriptV4′, hide_playlist=True, viral_sharing=False, embed_button=False, autoplay=False, hidden_controls=False, loop=False, muted=False, full_width=False, width=’1920′, height=’1048′, player_id=’37396994307′, style=” %}
4) Delta Lake Support in Azure Synapse Analytics and Azure Data Factory Data Flows & Copy Activity
Delta Lake is a newer file format for that Data Lake that builds upon the populate open source file format Apache Parquet. Delta Lake is an all-star storage format in the Data Lake because it tacks on transaction level ACID support on top of the parquet features of metadata storage and columnar compression. With Delta Lake format, Data Engineers can build pipelines in the Data Lake that use common coding techniques like DELETE, UPDATE, and even MERGE (also called UPSERT), which wasn’t previously capable on the Data Lake. Delta Lake also enables compaction, indexing, and even time travel on the data. See the documentation for a complete overview of the Delta Lake capabilities.
Prior to some recent announcements, Delta Lake really only worked when using Azure Databricks. Azure Synapse SQL pools (on-demand and provisioned), Synapse Spark pools, and Azure Data Factory Data Flows/Copy Activity couldn’t read Delta format – three strikes and you’re out.
Delta Lake has since moved on up to the Big Leagues. Now, components of Azure Synapse Analytics Workspaces and Azure Data Factory can fully leverage the Delta Lake storage format. This means that Delta Lake can be fully adopted and embraced as the Data Lake file format of choice without concessions on how it is used and managed. More on these announcements is below. Please note that some of the Delta Lake functionality in Synapse Workspaces via SQL on-demand will not be available until GA.
Delta Lake in ADF Copy Activity
{% video_player “embed_player” overrideable=False, type=’scriptV4′, hide_playlist=True, viral_sharing=False, embed_button=False, autoplay=False, hidden_controls=False, loop=False, muted=False, full_width=True, width=’1920′, height=’1048′, player_id=’37396994310′, style=” %}
5) Azure Synapse Analytics Workspaces
Azure Synapse Analytics Studio is a new UI tool on top of Azure Synapse Analytics Workspaces that allows for a single interface for development, querying, management, and monitoring of the entire Modern Data Platform – a grand slam of functionality. Using Synapse Studio, users can:
- Browse files and tables in the Data Lake
- Browse tables in the Data Warehouse
- Query files and tables in the Data Lake and Data Warehouse
- Copy and orchestrate data to the Data Lake or Data Warehouse
- Develop data transformation routines at scale using vanilla Spark pools
- Transform data in the Data Lake and Data Warehouse using scripts, notebooks, or jobs programmed using popular programming languages like SQL, SparkSQL, PySpark, Scala, or .NET Spark.
- Transform data using dynamic, code-free pipeline in data flows
- Monitor data pipelines and jobs
- Configure data sources and networks, and manage the Modern Data Platform
- Create and consume Power BI reports
While this integration may seem trivial, Azure Synapse Analytics Workspaces and Azure Synapse Analytics Studio consolidate the power of 6+ Azure PaaS services and 6+ developer/analyst data applications into a single interface. More integration means less deployment, development, and configuration, and more time analyzing and gaining insights from data. No other tool on the market (in or outside of Azure) provides this much integration and simplicity to create, manage, and consume a Modern Data Platform architecture!
If you’d like to learn more about Azure Synapse Analytics Workspace or Azure Databricks (or these top 5 features) and how they can help you win the World Series of Modern Data Platform, contact BlueGranite today.



