
Lambda architecture is the state-of-the-industry, Big Data workload pattern for handling batch and streaming workloads in a single system. If you’re researching how to modernize your data program, the lambda architecture is the place to start.
Let’s review the key concepts, parse through the tooling options in Microsoft Azure, examine some sample reference architectures, and discuss common criticisms of lambda. In a follow-up post, we’ll introduce the emerging kappa architecture and compare the benefits and limitations against lambda.

Lambda Architecture Overview
The key components of the lambda architecture are the hot and cold data processing paths, and a common serving layer that combines outputs for both paths. The hot path refers to streaming data workloads and the cold path applies to batch-processed data. The goal of the architecture is to present a holistic view of an organization’s data, both from history and in near real-time, within a combined serving layer, as the following Microsoft visual illustrates.
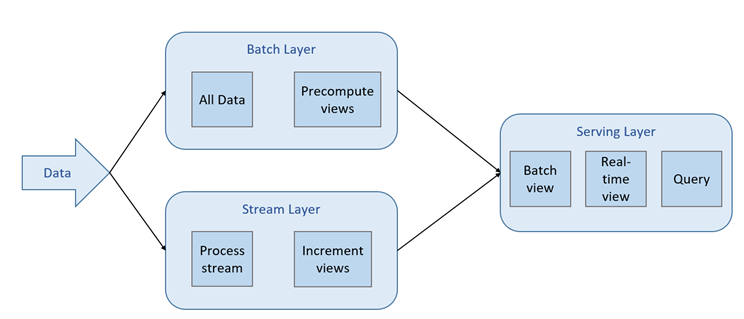 |
| Lee Stott, Microsoft UK, Big Data on Azure with No Limits Data, Analytics and Managed Clusters. Retrieved from https://blogs.msdn.microsoft.com/uk_faculty_connection/2017/02/24/big-data-on-azure-with-no-limits-data-analytics-and-managed-clusters |
Tooling for Lambda Architecture in Azure
You can run any tooling you want in Azure as Infrastructure as a Service (IaaS), but the value-add in cloud platforms for Big Data is in the Platform as a Service and Software as a Service tiers. The non-IaaS options in Azure are to either use the fully managed, native Azure services, HDInsight, or the new Azure Databricks offering (currently in preview).
Reference Architecture using Native Azure-Managed Services
Implementing native, Azure-managed services for lambda simplifies your list of services to choose from. This may or may not be a good thing. The exciting and frustrating pace of change in distributed systems means there’s always something new on the horizon, so if you go all in with native Azure-managed services, you lock in your capabilities to the Azure product team’s release cycle. This isn’t a concern most of the time, however, there might be edge cases where managed services just can’t meet your organization’s needs. For example, when considering Stream Analytics: is your reference data for streaming greater than 100MB? Do you need throughput of more than 1GB / sec? Is a maximum time to live (TTL) of 7 days sufficient?
Unless you’re outside of the current capabilities of a service (or will be soon), then the managed service architecture is the best place to start.
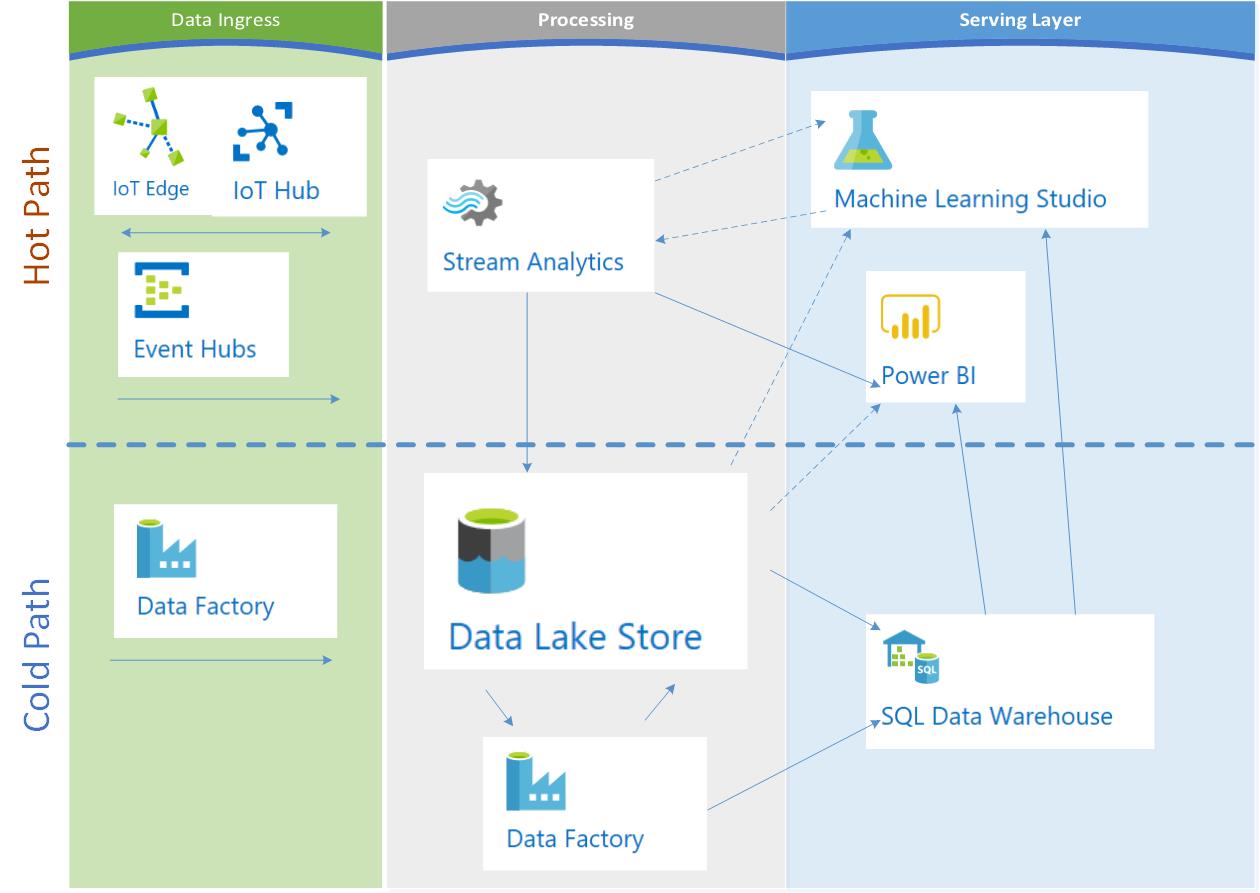
There are lots of options for augmenting, substituting, and extending this architecture. The goal here is to give a baseline of what you would probably need in your ecosystem to support lambda if preferring native Azure services.
Reference Architecture for HDInsight
Below is an implementation with preference for HDInsight services:
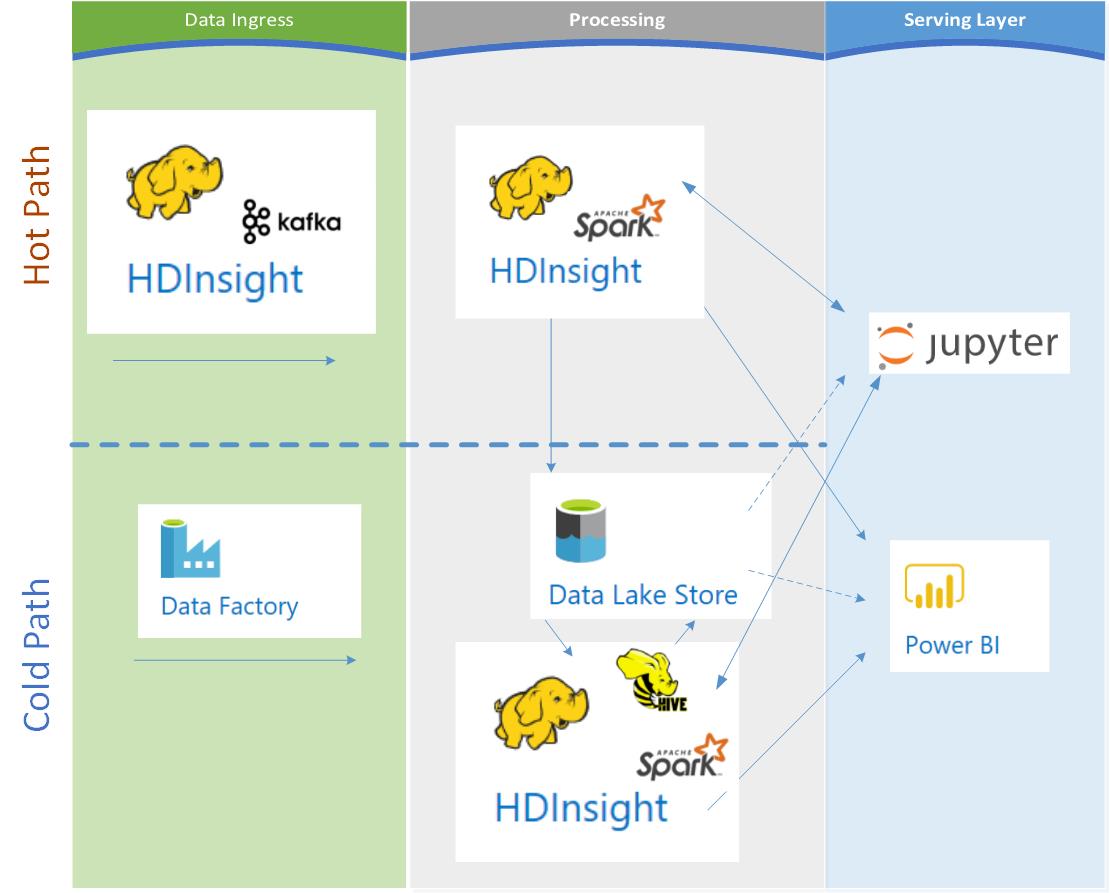
You’ll notice that we’ve listed Azure Data Factory (ADF) as the ingest engine for batch. The data movement, lineage, monitoring, and orchestration capabilities of ADF are extremely difficult to substitute for in the Azure cloud. Even running HDInsight jobs as Data Factory linked services automatically handles the spin up and tear down of clusters for you. So, while you have lots of options as far as analytics, machine learning, querying, and compute services, if you’re considering any type of Big Data workload in Azure, then planning on ADF as part of your architecture will simplify and accelerate your development cycle.
Limitations of Lambda
Extending for concurrency and frequency
An assumption that you often see with lambda, as modeled above, is low concurrency and/or frequency, specifically in the cold path. This does not fit many large organizations’ internal needs, or even those of small organizations offering reporting and analytics to their end customers. In practice, the serving layer is usually extended to include a hub-and-spoke architecture that incorporates a structured data mart to support the most commonly queried data (either by partition or entity). I personally don’t know of a common name for this, but I like to think of it as the warm path. We are purposely prioritizing some batch-processed data into services that support higher concurrency at a lower cost. Over time, the partitions are aged out of the warm path, but persist within the cold query path. This augmentation to lambda also helps simplify multi-tenancy, self-service BI, and embedded analytics use cases.
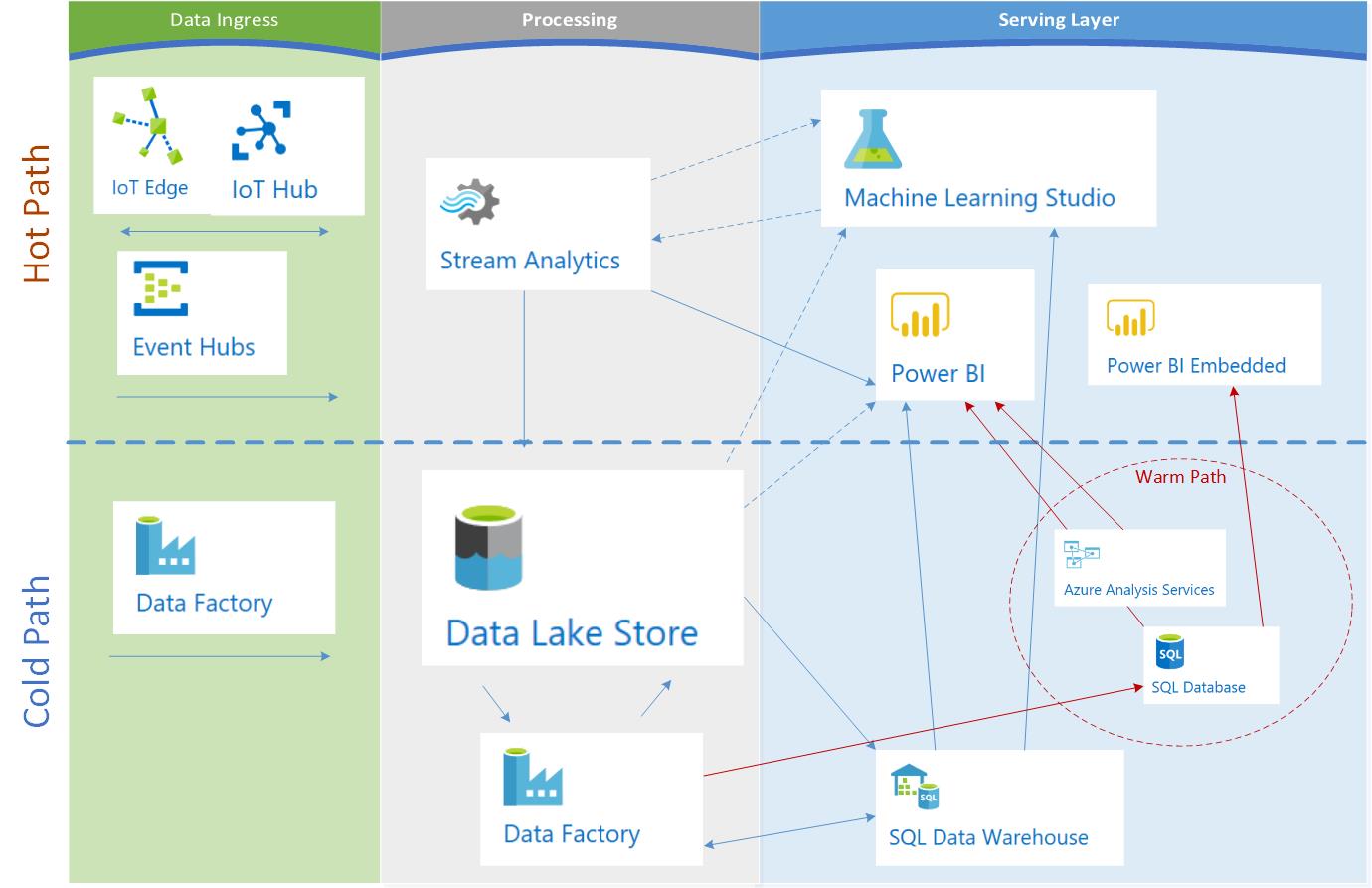
Common Criticisms
Lambda is an organic result of the limitations of existing tools. Distributed systems architects and developers commonly criticize its complexity – and rightly so. Those of us that have worked extensively in Extract-Transform-Load and symmetric multiprocessing systems see red flags when code is replicated in multiple services. Ensuring data quality and code conformity across multiple systems, whether massively parallel processing (MPP) or symmetrically parallel system (SMP), has the same best practice: the least amount of times you reproduce code is always the correct number of times.
We reproduce code in lambda because different services in MPP systems are better at different tasks. The maturity of tools historically hasn’t allowed us to process streams and batch in a single tool. This is starting to change, with Apache Spark emerging as a single preferred compute service for stream and batch querying, hence the timing of Azure Databricks. However, on the storage side, what was meant to be an immutable store that is the data lake in practice, can become the dreaded swamp when governance or testing fails; which is not uncommon. A fundamentally different assumption to how we process data is required to combat this degradation. Enter: the kappa architecture, which we’ll examine in the next post of this series.
For those looking to delve further in the lambda architecture, there are several highly detailed resources available. Check out this blog post by BlueGranite’s Josh Fennessy for starters.
Want to discover the best way to handle your organization’s data? We design our custom cloud analytics solutions around your business. Contact BlueGranite today to learn more.



