
Note: This blog post was originally published on 11/1/2017 and has been updated on 1/23/2019.
————————————————————————————————————–

Over time at 3Cloud, we have observed some customer confusion around when Azure SQL Data Warehouse is most appropriate to use. This blog post and the accompanying decision tree below are meant to help you answer the question: Is Azure SQL Data Warehouse the best technology choice for your implementation?
Azure SQL Data Warehouse (SQL DW) is a cloud-based Platform-as-a-Service (PaaS) offering from Microsoft. It is a large-scale, distributed, MPP (massively parallel processing) relational database technology in the same class of competitors as Amazon Redshift or Snowflake. Azure SQL DW is an important component of the Modern Data Warehouse multi-platform architecture. Because Azure SQL DW is an MPP system with a shared-nothing architecture across distributions, it is meant for large-scale analytical workloads which can take advantage of parallelism. The distributed nature of Azure SQL DW allows for storage and compute to be decoupled, which in turn offers independent billing and scalability. Azure SQL DW is considered an elastic data warehouse because its level of compute power can be scaled up, down, or even paused, to reserve (and pay for) the amount of compute resources necessary to support the workload.
Azure SQL DW is part of Microsoft’s ‘SQL Server family’ of products which also includes Azure SQL Database and SQL Server (both of which are SMP, symmetric multiprocessing, architecture). This commonality means that knowledge and experience will translate well to Azure SQL DW, with one notable exception: MPP architecture is very different from the SMP architecture of Azure SQL Database and SQL Server, thus requiring specific design techniques to take full advantage of the MPP architecture. The remainder of this post discusses some of the most important things to consider when making a decision to use Azure SQL DW.
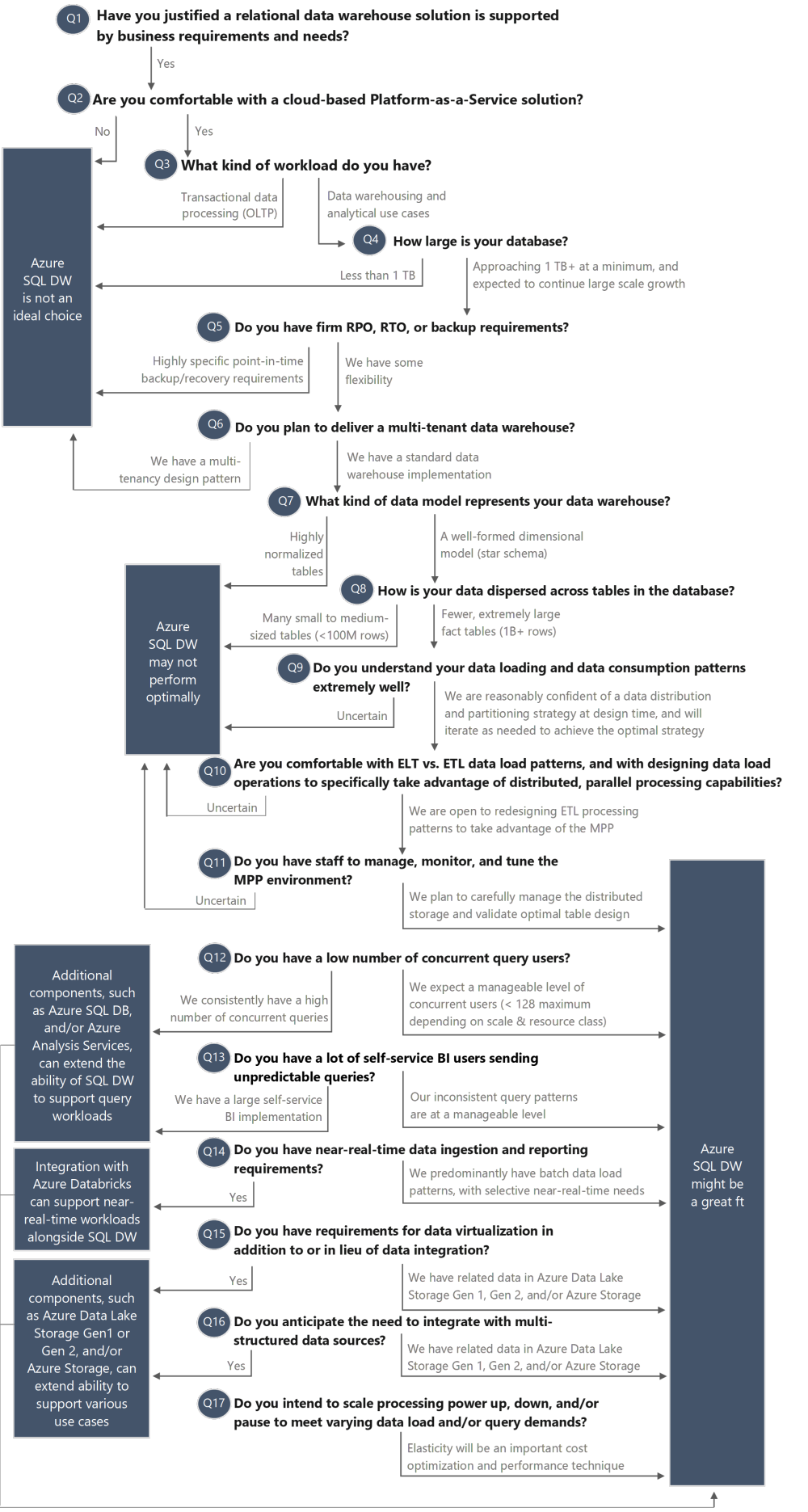
The following comments highlight each of the items in the decision tree above:
Q1: Have you justified that a relational data warehouse solution is supported by business requirements and needs?
The most common justifications for a data warehouse implementation include:
Consolidate and relate multiple disparate data sources. Data is inherently more valuable once it has been integrated together from multiple sources. A common example cited is the 360-degree view of a customer which could align customer master data, sales, open receivables, and support requests so they can be analyzed together.
Centralize analytical data for user data access. A data warehouse is most often thought of as supporting corporate BI efforts (typically thought of as standardized corporate reports and dashboards). It can also play a big role in self-service BI efforts by providing consistent, cleansed, governed data. Realistically, a “single version of the truth” can never be 100% met, but effective governance and master data management can increase the odds that the data warehouse provides consistent and accurate data for all types of analytics throughout the organization.
Historical analysis. The data warehouse supports historical reporting and analysis via techniques such as periodic snapshots and slowly changing dimensions. A common scenario is a customer’s sales representative has changed this quarter, or a department rolls up to a different division now. The flexibility to report on either “the way it was” or “the way it is” can offer significant value – and is rarely available from standard source systems.
User-friendly data structure. It is valuable to structure the data into a user-friendly dimensional model which really helps the largest portion of the user base. Other techniques such as friendly table and column names, derived attributes, and helpful measures (such as MTD, QTD, and YTD), contribute significantly to ease of use. Time investments here should encourage data analysts to utilize the data warehouse, leading to consistent results and, in turn, saving time and effort.
Minimize silos. When a business-driven analytical solution (often referred to as shadow IT) becomes critical to running the business, that is a signal that it’s time to promote the solution up to a centralized system so that it can be supported more fully, integrated with other data, and made available to a larger user base. The data warehouse can take advantage of business user efforts and continue gaining in maturity and value, as well as minimize silos and “one-off” solutions.
Multi-platform architecture which takes advantage of existing investment. If your existing data warehouse does bring value for certain use cases, it is not economically feasible to retire it or migrate everything to another architecture (ex: Hadoop or data lake). Instead, we recommend a multi-platform architecture in which the data warehouse is one, albeit important, component. For instance, using a data lake for data ingestion, exploratory analysis, staging for a data warehouse, and/or archival from the data warehouse, are all complementary to the data warehouse which can handle serving much of the curated, cleansed data.
![]() Tip: A data warehouse is most advantageous when is deployed alongside other services, such as a data lake, so that each type of service can do what it does best.
Tip: A data warehouse is most advantageous when is deployed alongside other services, such as a data lake, so that each type of service can do what it does best.
————————————————————————————–
Q2: Are you comfortable with a cloud-based Platform-as-a-Service solution?
Azure SQL DW is a service offering for the public cloud and the national (sovereign) clouds. It is a PaaS (Platform-as-a-Service) solution in which the customer has no responsibility for, or visibility to, the underlying server architecture. The storage and compute are decoupled, which is a very big advantage of Azure SQL DW. Costs for processing power (compute) are based on a consumption model, which is controlled by data warehouse units (DWUs for Gen1, and cDWUs for Gen2) that can be scaled to meet demanding data loads and peak user volumes. The persisted data is required to be stored on Azure premium storage, which performs better than standard storage and thus is more expensive.
![]() Tip: As a PaaS service, Microsoft handles system updates. For Azure SQL DW, customers may specify a preferred primary and secondary day/time range for system maintenance to occur.
Tip: As a PaaS service, Microsoft handles system updates. For Azure SQL DW, customers may specify a preferred primary and secondary day/time range for system maintenance to occur.
————————————————————————————–
Q3: What kind of workload do you have?
Azure SQL DW is most appropriate for analytical workloads: batch-oriented, set-based read and write operations. Workloads which are transactional in nature (i.e., many small read and write operations), with many row-by-row operations are not suitable.
![]() Tip: Although ‘data warehouse’ is part of the product name, it is possible to use Azure SQL Database for a smaller-scale data warehousing workload if Azure SQL DW is not justifiable. Keep in mind that Azure SQL DW is part of the SQL Server family; there are some limitations and feature differences between Azure SQL DW, Azure SQL DB, and SQL Server.
Tip: Although ‘data warehouse’ is part of the product name, it is possible to use Azure SQL Database for a smaller-scale data warehousing workload if Azure SQL DW is not justifiable. Keep in mind that Azure SQL DW is part of the SQL Server family; there are some limitations and feature differences between Azure SQL DW, Azure SQL DB, and SQL Server.
————————————————————————————–
Q4: How large is your database?
It is difficult to pinpoint an exact number for the absolute minimum size recommended for Azure SQL DW. Many data professionals in the industry see the minimum “practical” data size for Azure SQL DW in the 1-4 TB range. Since Azure SQL DW is an MPP (massively parallel processing) system, you experience a significant performance penalty with small data sizes because of the overhead incurred to distribute and consolidate across the nodes (which are distributions in a “shared nothing” architecture). We recommend Azure SQL DW for a data warehouse which is starting to approach 1 TB and expected to continue growing.
![]() Tip: It’s important to factor in realistic future growth when deciding whether to use Azure SQL DW. Since the data load patterns are different for Azure SQL DW (to utilize PolyBase and techniques such as CTAS which maximize MPP performance) versus Azure SQL DB or SQL Server, it may be a wise decision to begin using Azure SQL DW to avoid a future migration and future time redesigning data load processes. Do keep in mind though that it is a myth that you can provision the smallest size Azure SQL DW and expect it to perform just like Azure SQL DB.
Tip: It’s important to factor in realistic future growth when deciding whether to use Azure SQL DW. Since the data load patterns are different for Azure SQL DW (to utilize PolyBase and techniques such as CTAS which maximize MPP performance) versus Azure SQL DB or SQL Server, it may be a wise decision to begin using Azure SQL DW to avoid a future migration and future time redesigning data load processes. Do keep in mind though that it is a myth that you can provision the smallest size Azure SQL DW and expect it to perform just like Azure SQL DB.
————————————————————————————–
Q5: Do you have firm RPO, RTO, or backup requirements?
Being a PaaS offering, Azure SQL DW handles snapshots and backups each day. The service automatically creates restore points throughout each day and supports an 8-hour recovery point objective (RPO) over the previous 7 days. Once a day the service also automatically generates a geo-redundant backup, with its recovery point objective being 24 hours. Customers also have the capability of creating a user-defined restore point as of a specific point in time. The retention period for a user-defined restore point is still 7 days, after which it is automatically deleted.
![]() Tip: Backups are not taken when the compute resources for Azure SQL DW are in a paused state.
Tip: Backups are not taken when the compute resources for Azure SQL DW are in a paused state.
————————————————————————————–
Q6: Do you plan to deliver a multi-tenant data warehouse?
A multi-tenancy database design pattern is typically discouraged with Azure SQL DW.
![]() Tip: Although features which can be important to multi-tenancy (such as row-level security and column-level security) are available, you may instead want to evaluate using elastic pools in conjunction with Azure SQL Database for multi-tenant scenarios.
Tip: Although features which can be important to multi-tenancy (such as row-level security and column-level security) are available, you may instead want to evaluate using elastic pools in conjunction with Azure SQL Database for multi-tenant scenarios.
————————————————————————————–
Q7: What kind of data model represents your data warehouse?
A highly normalized data warehouse structure does not completely preclude you from using Azure SQL DW. However, since Azure SQL DW takes significant advantage of clustered columnstore indexes (which utilize columnar compression techniques), Azure SQL DW performs substantially better with denormalized data structures. For that reason, following sound dimensional design principles is strongly advised.
![]() Tip: Modern reporting tools are more forgiving of a substandard data model, which leads some data warehouse developers to be less strict with dimensional design. This can be a mistake, particularly if there are many users issuing self-service queries because a well-formed star schema aids significantly in usability.
Tip: Modern reporting tools are more forgiving of a substandard data model, which leads some data warehouse developers to be less strict with dimensional design. This can be a mistake, particularly if there are many users issuing self-service queries because a well-formed star schema aids significantly in usability.
————————————————————————————–
Q8: How is your data dispersed across tables in the database?
Even if you have a large database (1-4 TB+), table distribution is another consideration. An MPP system such as Azure SQL DW performs better with fewer, larger tables (1 billion+ rows) versus many small to medium-size tables (less than 100 million rows).
![]() Tip: As a rule of thumb, a table does not benefit from being defined as a clustered columnstore index until it has more than 60 million rows (60 distributions x 1 million rows each). In Azure SQL DW, we want to make the effort to use clustered columnstore indexes (CCIs) as effectively as possible. There are several reasons for this, but one key reason is because CCI data is cached on local SSDs and retrieving data from cache improves performance significantly (applicable to Azure SQL DW Gen2 only).
Tip: As a rule of thumb, a table does not benefit from being defined as a clustered columnstore index until it has more than 60 million rows (60 distributions x 1 million rows each). In Azure SQL DW, we want to make the effort to use clustered columnstore indexes (CCIs) as effectively as possible. There are several reasons for this, but one key reason is because CCI data is cached on local SSDs and retrieving data from cache improves performance significantly (applicable to Azure SQL DW Gen2 only).
————————————————————————————–
Q9: Do you understand your data loading and data consumption patterns extremely well?
Being a relational database, Azure SQL DW is considered “schema on write.” Since Azure SQL DW is also a distributed system, distribution keys inform the system how it should allocate data across the nodes. The selection of a good distribution key is critical for performance of large tables. In addition to distributing data, partitioning strategies are different in Azure SQL DW versus standard SQL Server. It is extremely important for Azure SQL DW developers to deeply understand data load patterns and query patterns in order to maximize parallelization, avoid data skew, and to minimize data movement operations and shuffling within the MPP platform.
![]() Tip: PolyBase can be used one of two ways: (1) for loading data into Azure SQL DW (in fact, it’s recommended), or (2) for querying remote data stored outside of Azure SQL DW. PolyBase is the recommended method for loading data in Azure SQL DW because it can natively take advantage of the parallelization of the compute nodes, whereas other loading techniques do not perform as well because they go through the control node. Usage of PolyBase for querying remote data should be done very carefully (see Q15 below).
Tip: PolyBase can be used one of two ways: (1) for loading data into Azure SQL DW (in fact, it’s recommended), or (2) for querying remote data stored outside of Azure SQL DW. PolyBase is the recommended method for loading data in Azure SQL DW because it can natively take advantage of the parallelization of the compute nodes, whereas other loading techniques do not perform as well because they go through the control node. Usage of PolyBase for querying remote data should be done very carefully (see Q15 below).
————————————————————————————–
Q10: Are you comfortable with ELT vs. ETL data load patterns, and with designing data load operations to specifically take advantage of distributed, parallel processing capabilities?
The principles and patterns for loading a distributed MPP system are very different from a traditional SMP (Symmetric Multi-Processing) system. To utilize parallelization across the compute nodes, PolyBase and ELT (extract>load>transform) techniques are recommended for Azure SQL DW data load processes. This means that migration to Azure SQL DW often involves redesigning existing ETL operations to maximize performance, minimize logging, and/or utilize supported features (for example, merge statements are not currently supported in SQL DW; there are also limitations with respect to how insert and delete operations may be written; using CTAS techniques are recommended to minimize logging). New tables added to Azure SQL DW often involve an iterative effort to find the best distribution method.
![]() Tip: Although PolyBase does significantly improve the performance for data loads because of parallelization, PolyBase can be very challenging to work with depending on the data source format and data contents (for instance, when commas and line breaks appear within the data itself). Be sure to include adequate time in your project plan for development and testing of the new data load design patterns.
Tip: Although PolyBase does significantly improve the performance for data loads because of parallelization, PolyBase can be very challenging to work with depending on the data source format and data contents (for instance, when commas and line breaks appear within the data itself). Be sure to include adequate time in your project plan for development and testing of the new data load design patterns.
————————————————————————————–
Q11: Do you have staff to manage, monitor, and tune the MPP environment?
Although Azure SQL DW is a PaaS platform, it should not be thought of as a hands-free environment. It requires monitoring of data loads and query demands to determine if distribution keys, partitions, indexes, and statistics are configured well.
![]() Tip: Azure SQL DW does have some emerging features offering recommendations. Integration with Azure Advisor and Azure Monitor is continually evolving, which makes it easier for an administrator to identify issues. Specifically, Azure SQL DW Gen2 utilizes “automatic intelligent insights” within Azure Advisor to display if issues exist related to data skew, missing statistics, or outdated statistics.
Tip: Azure SQL DW does have some emerging features offering recommendations. Integration with Azure Advisor and Azure Monitor is continually evolving, which makes it easier for an administrator to identify issues. Specifically, Azure SQL DW Gen2 utilizes “automatic intelligent insights” within Azure Advisor to display if issues exist related to data skew, missing statistics, or outdated statistics.
————————————————————————————–
Q12: Do you have a low number of concurrent query users?
Queries are queued up if the maximum concurrency threshold is exceeded, at which time queries are resolved on a first-in-first-out basis. Because of concurrent user considerations, Azure SQL DW frequently has complementary solutions in a multi-platform architecture for handling different types of query demands. We often see Azure Analysis Services and/or Azure SQL Database as the spokes in a hub-and-spoke design.
![]() Tip: The number of concurrent queries executing at the same time can be as high as 128 depending on the service tier (i.e., the pricing level) and based on resource class usage (because assigning more resources to a specific user reduces the overall number of concurrency slots available).
Tip: The number of concurrent queries executing at the same time can be as high as 128 depending on the service tier (i.e., the pricing level) and based on resource class usage (because assigning more resources to a specific user reduces the overall number of concurrency slots available).
————————————————————————————–
Q13: Do you have a lot of self-service BI users sending unpredictable queries?
A data warehouse is primarily intended to serve data for large queries. Although a tool such as Power BI supports direct query with Azure SQL DW, this should be done with some measure of caution. Specifically, dashboards can be troublesome because a dashboard page refresh can issue many, many queries all at once to the data warehouse. As noted in Q12, for production use of Power BI we often recommend using a semantic layer, such as Azure Analysis Services, as part of a hub-and-spoke strategy. The objective of introducing a semantic layer is to (a) reduce some of the query demand on the MPP (reducing data movement when unpredictable queries come in), and (b) reduce concurrent queries executed on the MPP system, and (c) include user-friendly calculations and measures which can dynamically respond as a user interacts with a report.
![]() Tip: It is certainly possible to use Azure SQL DW directly with an analytical tool like Power BI (i.e., with Power BI operating in DirectQuery mode rather than import mode). However, usage of DirectQuery mode should be tested thoroughly, especially if the user base expects sub-second speed when slicing and dicing. Conversely, if the expected usage is more data exploration where query response time is more flexible, then it’s possible direct querying of Azure SQL DW from a tool such as Power BI will work. The Gen2 tier of Azure SQL DW introduced adaptive caching for tables which are defined as a clustered columnstore index (CCI). Adaptive caching increases the possibility that self-service user queries can be satisfied from the cached data in Azure SQL DW, which improves performance significantly. Another option to potentially consider: Power BI Premium now also has aggregations which can cache data in Power BI’s in-memory model for the first level of queries, requiring a drillthrough to Azure SQL DW only when the user gets to a lower level or less commonly used data.
Tip: It is certainly possible to use Azure SQL DW directly with an analytical tool like Power BI (i.e., with Power BI operating in DirectQuery mode rather than import mode). However, usage of DirectQuery mode should be tested thoroughly, especially if the user base expects sub-second speed when slicing and dicing. Conversely, if the expected usage is more data exploration where query response time is more flexible, then it’s possible direct querying of Azure SQL DW from a tool such as Power BI will work. The Gen2 tier of Azure SQL DW introduced adaptive caching for tables which are defined as a clustered columnstore index (CCI). Adaptive caching increases the possibility that self-service user queries can be satisfied from the cached data in Azure SQL DW, which improves performance significantly. Another option to potentially consider: Power BI Premium now also has aggregations which can cache data in Power BI’s in-memory model for the first level of queries, requiring a drillthrough to Azure SQL DW only when the user gets to a lower level or less commonly used data.
————————————————————————————–
Q14: Do you have near-real-time data ingestion and reporting requirements?
Distributed systems like Azure SQL DW are most commonly associated with batch-oriented data load processes. However, capabilities continue to emerge which support near real-time streaming data ingestion into Azure SQL DW. This works in conjunction with Azure Databricks streaming dataframes, which opens some interesting new scenarios for analysis of lower latency data (such as data generated from IoT devices or the web).
![]() Tip: When using Azure Databricks for streaming data, it is the front-end for the ingestion stream before being output to Azure SQL DW in mini-batches via PolyBase—meaning this can be classified as a near-real-time system, but you should expect there to be some latency. Also, keep in mind that Azure Databricks can also be effectively utilized as a data engineering tool for data processing and loading to Azure SQL DW in batch mode (the JDBC Azure SQL DW connector from Azure Databricks does take advantage of PolyBase).
Tip: When using Azure Databricks for streaming data, it is the front-end for the ingestion stream before being output to Azure SQL DW in mini-batches via PolyBase—meaning this can be classified as a near-real-time system, but you should expect there to be some latency. Also, keep in mind that Azure Databricks can also be effectively utilized as a data engineering tool for data processing and loading to Azure SQL DW in batch mode (the JDBC Azure SQL DW connector from Azure Databricks does take advantage of PolyBase).
————————————————————————————–
Q15: Do you have requirements for data virtualization in addition to or in lieu of data integration?
PolyBase in Azure SQL DW currently supports Azure Storage (blobs) and Azure Data Lake Storage (Gen1 or Gen2), which can be used for very selective data virtualization and data federation needs. Data virtualization refers to querying the data where it lives (thus saving work to do data integration to relocate the data elsewhere).
![]() Tip: When using PolyBase for data virtualization (i.e., querying remote data stored in Azure Storage or Azure Data Lake Storage), there is no pushdown computation to improve query performance. This means that Azure SQL DW needs to read the entire file into TempDB to satisfy the query. For queries which are issued rarely (such as a quarter-end analysis, or data to supply to the auditors), it’s possible to use virtualized queries effectively in very specific situations where expectations for query response speed is not of utmost importance.
Tip: When using PolyBase for data virtualization (i.e., querying remote data stored in Azure Storage or Azure Data Lake Storage), there is no pushdown computation to improve query performance. This means that Azure SQL DW needs to read the entire file into TempDB to satisfy the query. For queries which are issued rarely (such as a quarter-end analysis, or data to supply to the auditors), it’s possible to use virtualized queries effectively in very specific situations where expectations for query response speed is not of utmost importance.
————————————————————————————–
Q16: Do you anticipate the need to integrate with multi-structured data sources?
It is very common for a data warehouse to be complementary to a data lake which contains multi-structured data from sources such as web logs, social media, IoT devices, and so forth. Although Azure SQL DW does not support data types such as JSON, XML, spatial or image, it can work in conjunction with Azure Storage and/or Azure Data Lake Storage (Gen1 or Gen2) which might provide additional flexibility for data integration and/or data virtualization scenarios.
![]() Tip: When connecting to external data, PolyBase currently supports reading Parquet, Hive ORC, Hive RCFile, or delimited text (such as a CSV) formats. Parquet has emerged as one of the leading candidates for a data lake storage format.
Tip: When connecting to external data, PolyBase currently supports reading Parquet, Hive ORC, Hive RCFile, or delimited text (such as a CSV) formats. Parquet has emerged as one of the leading candidates for a data lake storage format.
————————————————————————————–
Q17: Do you intend to scale processing power up, down, and/or pause to meet varying data load and/or query demands?
One of the best features of a cloud offering like Azure SQL DW is its elasticity of compute power. For instance, you could scale up on a schedule to support a demanding data load, then scale back down to the normal level when the load is complete. The Azure SQL DW can even be paused during times when no queries are sent to the data warehouse at all, during which the storage of data is safe, yet there are no compute charges at all (because storage and compute are decoupled). Utilizing scale up/down/pause techniques can prevent over-provisioning of resources, which is an excellent cost optimization technique.
![]() Tip: When an operation to scale up or down is initiated, all open sessions are terminated, and open insert/update/delete transactions are rolled back. This behavior is to ensure the Azure SQL DW is in a stable state when the change occurs. The short downtime may not be acceptable for a production system and/or may only be acceptable during specific business hours. Also, keep in mind that the adaptive cache (available with the Gen2 tier) is cleared when a scale or pause occurs, requiring the cache to be re-warmed to achieve optimal performance.
Tip: When an operation to scale up or down is initiated, all open sessions are terminated, and open insert/update/delete transactions are rolled back. This behavior is to ensure the Azure SQL DW is in a stable state when the change occurs. The short downtime may not be acceptable for a production system and/or may only be acceptable during specific business hours. Also, keep in mind that the adaptive cache (available with the Gen2 tier) is cleared when a scale or pause occurs, requiring the cache to be re-warmed to achieve optimal performance.
If you’re exploring the best data analytics architecture for your firm’s needs, 3Cloud would love to help. Contact us today to discover how our team designs solutions that fit your company and your budget.



