
This post contains highlights of our recent “Intro to Personalized Marketing” webinar.
The continued growth of e-commerce, social media, and streaming services, combined with growing data volumes related to digital activity, has made it possible – and even an expectation – for brands to provide personal experiences to their customers. Global research giant Gartner estimates that organizations using online personalization will outsell companies that aren’t by 30%, and, that by 2020, 90% of brands will practice at least one form of personalized marketing[1]. Effective digital marketing provides richer insights from customer interactions, allowing organizations to create better content, develop deeper prospect relationships, and ultimately achieve greater return on investment (ROI) from advertising.
 Personalized marketing utilizes modern tools, like machine learning (ML) and AI, then operationalizes insights from those tools. Common barriers to success when using data science technology include difficulty collaborating among team members, managing experiments and other modeling artifacts, scalability, and using predictions in applications. This post will discuss some introductory concepts for digital marketing professionals and data scientists to overcome these challenges.
Personalized marketing utilizes modern tools, like machine learning (ML) and AI, then operationalizes insights from those tools. Common barriers to success when using data science technology include difficulty collaborating among team members, managing experiments and other modeling artifacts, scalability, and using predictions in applications. This post will discuss some introductory concepts for digital marketing professionals and data scientists to overcome these challenges.
What does a consumer want to see next and how likely are they to purchase? What information about the product should be presented? Personalized marketing refers to deciding what content should be shown to different groups of customers based on your knowledge of those groups. That knowledge can come from what the customer has told you about themselves, how they’ve behaved in the past (their purchases and online activity), and details about the products or services you’re offering. Above all, this content should be more interesting and relevant to your customer than if you were treating them “like everyone else.” Benefits of this type of modern marketing approach include increased open rates, conversions, and page views, shorter sales cycle times and lower overall marketing costs. HubSpot, a leading customer relationship management (CRM) provider, finds 68% of marketers say that personalization based on behavioral data has a high impact on ROI, while 74% say it has a high impact on engagement. But only 19% do it[2]. So, what are the challenges?
 Personalized marketing depends on the quality and volume of data available – about your customers and their preferences – and the analytic tools and talent to make sense of it. Defining different groups, or segments, can be performed in various levels of sophistication and detail. For example, basic customer list segmentation can be performed manually using information your users have volunteered about themselves, usually from registration forms. However, moving beyond the basics is best accomplished with advanced tools like machine learning. The essence of machine learning is using prior examples to predict outcomes of future occurrences, without being explicitly programmed. It’s pattern recognition from the data, but this can involve complex patterns across multiple data sets and variables.
Personalized marketing depends on the quality and volume of data available – about your customers and their preferences – and the analytic tools and talent to make sense of it. Defining different groups, or segments, can be performed in various levels of sophistication and detail. For example, basic customer list segmentation can be performed manually using information your users have volunteered about themselves, usually from registration forms. However, moving beyond the basics is best accomplished with advanced tools like machine learning. The essence of machine learning is using prior examples to predict outcomes of future occurrences, without being explicitly programmed. It’s pattern recognition from the data, but this can involve complex patterns across multiple data sets and variables.
A common machine learning technique used for personalized marketing is a recommendation system. Most of us have been on the receiving end of a recommendation system if we’ve been advised of the “next best” product or movie we might like. What makes recommendation systems so powerful is the breadth and volume of data they can incorporate. In addition to the registered customer preferences discussed in the basic example, we can also include transaction history, click-stream data (i.e., Google Analytics), demographics from a third party, and ratings or sentiment from social media. Recommendation systems can use data sets and algorithms that, like personalization in general, can vary in complexity. You can read more about recommender systems here on this Microsoft data science blog[3].
Let’s discuss a basic recommendation scenario. You are preparing an email campaign for a new product. Your data set includes a customer list, purchase history, and product information about your existing products, as well as your new product. Patterns within this data set can reveal clues about the likelihood of each customer making a purchase. How recently has the customer made any purchase from you, and how much have they spent? Is this new product related to the customer’s interests – is it attractive for their age, geography, income level, and activities? How similar is the new product to products previously purchased? From this data, we can use a machine learning technique called classification – a type of recommendation system – that will predict the probability of purchase for each customer. With that, we can prioritize the mailing list, and maybe even avoid sending to large groups of customers unlikely to buy. It’s like lining up only our best customers (for that product) to come through the door first, and not bothering the rest. This preserves and improves relationships with customers over time, developing trust that we know what they do, and do not, like. In data science for marketing, capitalizing on predictions like this is called “lift.” If we have relatively accurate predictions, we can capture a large percentage of the relevant audience through contact with a comparatively smaller portion of the total customer base. In the illustration below, we achieve more than 30% lift by using machine learning compared to random guessing.
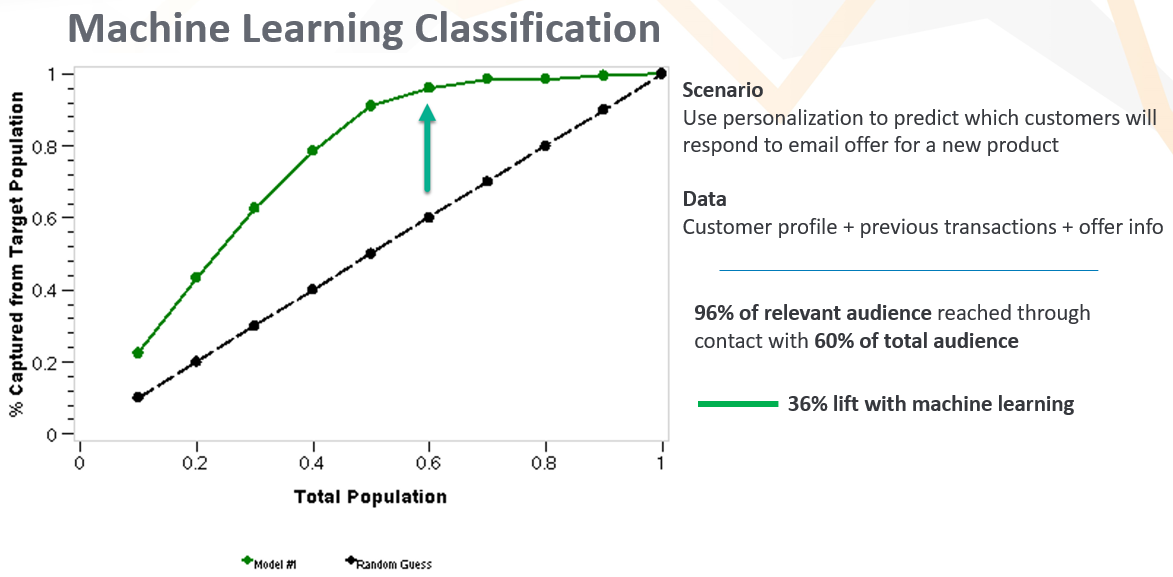
We still haven’t directly addressed all the challenges that might be inferred by only 19% of marketers using personalization. Data availability is one. Creating predictions using machine learning is another. But perhaps the biggest challenge is using the predictions in an operational system for real-time recommendations or decision making. Assuming you have the proper data, creating a classification model requires just a few lines of code in tools like Python or R. But in most organizations, these lines of code and the predictions they create remain in a data scientist’s local environment. Problems arise when trying to use big data sets like Google Analytics, collaborating with distributed teams, and keeping track of myriad development artifacts. For most organizations, getting real use out of a machine learning approach is an issue of scale and using best practices from software development like DevOps[4]. This is where a service such as Azure Machine Learning[5] can help.
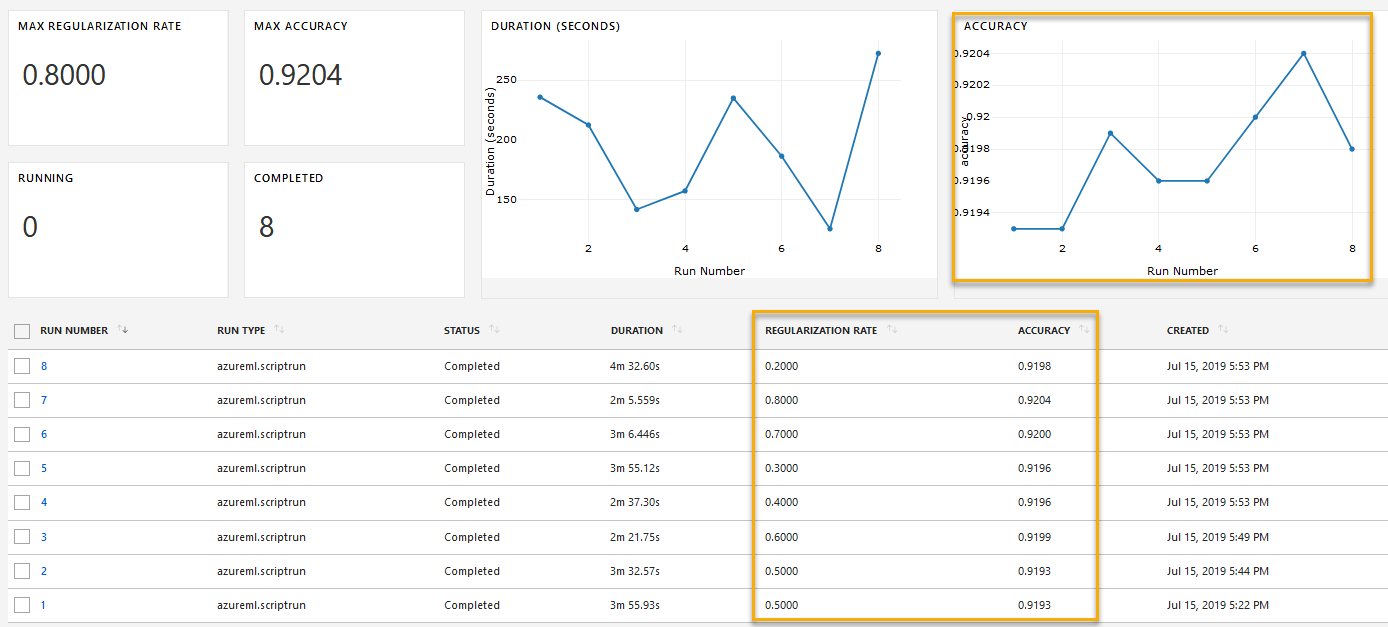
Azure Machine Learning service (Azure ML) is Microsoft’s cloud service for managing and deploying machine learning models, which can lead to major gains in terms of ML value and data scientist productivity. For model development, it allows data scientists to use their current code via the Python SDK and preferred frameworks (like PyTorch, TensorFlow, and scikit-learn) with scalable and on-demand compute environments like Spark and CPU/GPU clusters. Data scientists can stick with familiar development tools like local integrated development environments (IDEs) and notebooks, or use cloud-based notebook virtual machines (VMs)[6] that integrate directly with the service and are great for collaboration. Training experiments and results are registered in a workspace, and artifacts can be retrieved through the SDK, command-line interface (CLI), or web portal. The image below illustrates how a user can track experiment results across different model settings, such as hyperparameter values. This view can be accessed with a notebook widget or through the Azure portal.
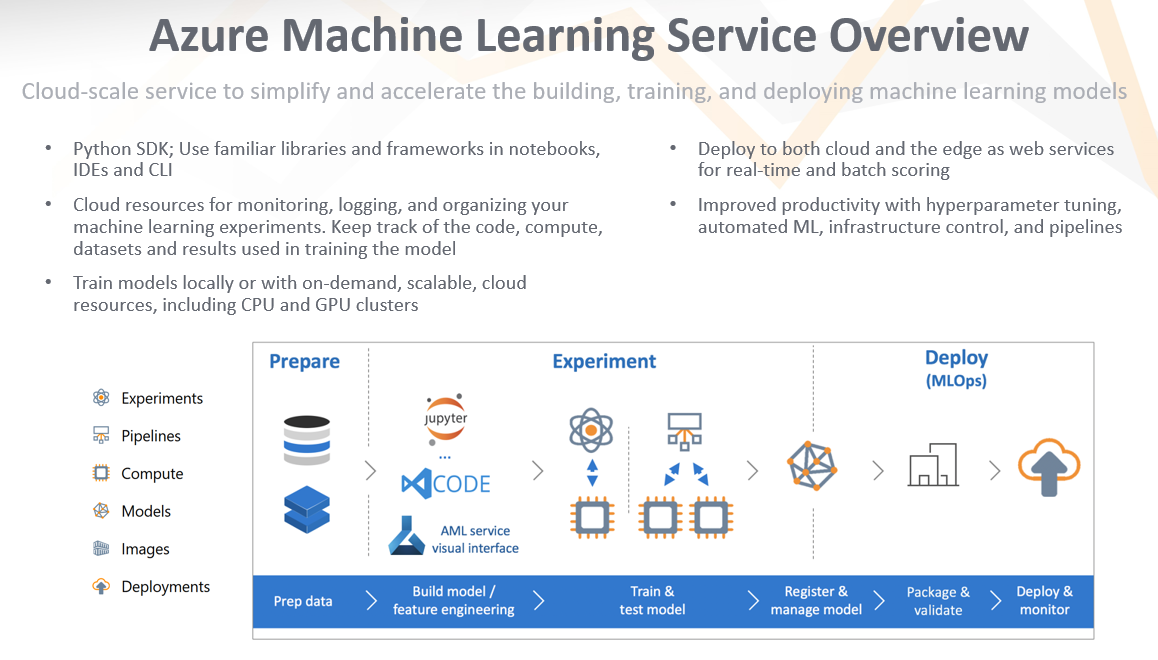
Once a model has been trained and selected, a model object and associated metadata can be registered on the service. I like to think of this stage as the bridge between traditional data science development and operational deployment. With the registered model, Azure ML provides great tools to deploy it as a web service. The model, along with information about the compute environment, are used to create a Docker image. These images can then be deployed as containers for testing or production as web services in applications[7] – serving your model and its predictions where they’re needed most. Even better, Azure ML provides tools to automate this production process into ML pipelines[8], DevOps-style. An overview of the service and its benefits are below:
As I was preparing for this post and the associated webinar, I was inspired by the wealth of resources Microsoft provides for getting started with personalized marketing. A great place to begin is this post here about building recommender systems with Azure Machine Learning service[9]. It discusses different types of recommenders, multiple machine learning algorithms, and considerations for deployment. It also has a companion GitHub repository, here,[10] with a rich set of recommender code examples, best practices, and utilities along the spectrum of development environments and ML frameworks. It has great setup instructions, whether you’re using a local machine or a more complex environment like Azure Databricks.
I hope you found this post helpful. The companion webinar also includes a live demonstration of using Azure ML from model training to deployment and accessing the web service in Power BI[11].
For more information on getting started with Azure Machine Learning, including a free Azure account, click here to visit Microsoft’s Azure account sign-up page.
Feel free to Contact Us with any questions regarding this blog post or the webinar.
[1] https://blogs.gartner.com/noah-elkin/the-long-and-winding-road-to-real-time-marketing/
[4] https://en.wikipedia.org/wiki/DevOps
[5] https://azure.microsoft.com/en-us/services/machine-learning-service/
[7] https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-deploy-and-where
[8] https://docs.microsoft.com/en-us/azure/machine-learning/service/concept-ml-pipelines
[10] https://github.com/microsoft/recommenders/blob/master/README.md
[11] https://docs.microsoft.com/en-us/power-bi/service-machine-learning-integration



