
Data science is the process of using advanced algorithms to extract insights from your data and often predict new data. You consume data science every day. Your phone has a voice-activated assistant; your mobile banking app can deposit a check by reading a photograph; your GPS suggests an alternate route based on traffic ahead; the online stores you shop suggest substitutes for the item you’re viewing; your car may even have self-driving features like accident avoidance.
But then something strange happens when you go to work. The futuristic life you lead suddenly vanishes, and you have to make decisions based on weeks-old data. Your systems don’t make intelligent predictions, and they certainly don’t provide suggestions of what you should do next. Where are the robots? Where is the guidance? You’ve collected all this data; surely there’s a better way to use it. What if you got to work and had an updated, prioritized to-do list provided by a digital assistant? What if you could process paperwork quicker using computer vision? What if your systems could assess your strategy real time and suggest the best course of action?
It is possible to make your business as productive as your life, but it’s a big change and requires a balanced, holistic approach. In this post, we’ll provide concrete steps and recommendations to institutionalize data science by equipping your workforce, aligning the right processes, and supporting it with the right data and tools.
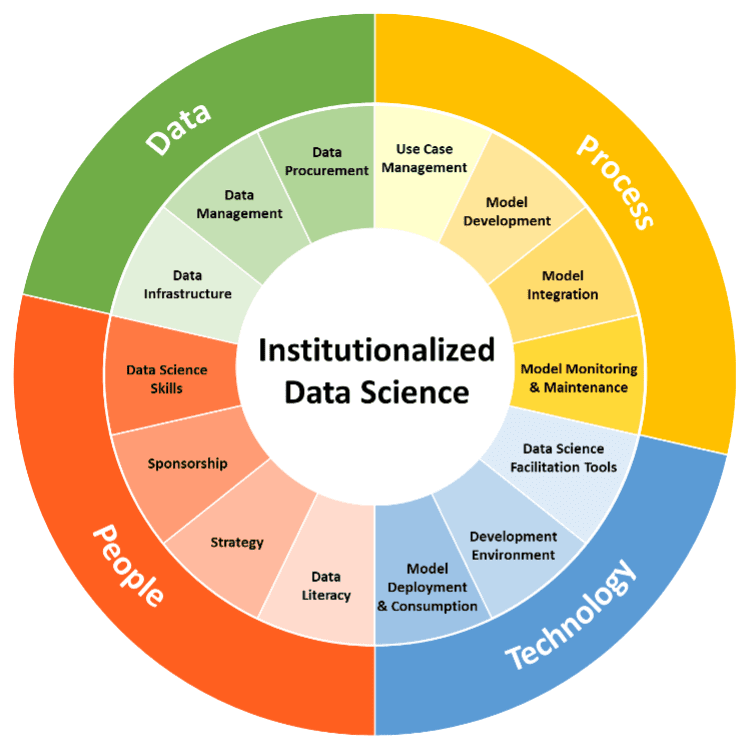
People: Equip Your Workforce
An analytics culture means a commitment to making fact-based decisions over gut feel across the organization. Employees must understand the need for data-driven decisions or they won’t use the wealth of information available. Even if you’ve hired the brightest data scientists out there, the value will be stifled if the culture does not support their research and effectively use their findings. How can you prepare your culture for a shift to a data-driven business?
Sponsorship
The message from the top must be clear: “In Data We Trust.” Identify a handful of executive sponsors to help the data science team develop and prioritize the most valuable use cases, secure the funding to complete projects, serve as the direct line of communication for the data scientists, and most importantly advocate for the adoption of the data science team’s solutions. As the results begin to show value, the sponsorship group can grow and permeate other areas of the organization.
Strategy
A large piece of sucessfully integrating data science into your business is the overarching roadmap detailing where this integration will begin, and how this will progress. A good data science strategy should be cohesive and cross-disciplined. It should account for all aspects of the business but give preference to areas that provide the best combination of business value and feasibility. It should result in a roadmap highlighting your biggest needs that looks for synergies across departments as you consider how data-driven decisions can impact your organization. The strategy will optimize how you organize your data science talent and the processes you use to direct their work.
Data Literacy
Everyone in your organization must trust the data, but especially your operational decision makers. They are your front-lines, advocating the value of data. Therefore, they need a baseline level of data literacy to articulate and advocate for data science. Inform them of the data science strategy, involve them in use case development and model development processes, and provide the basic training they need to trust the outputs of the data science process.
Data Scientist Skills
To get the most out of your data, you must acquire data scientists with the right skillset. The ideal data scientist has a balance of math knowledge, substantive expertise, and coding skills. This combination can be hard to find in a single person, so instead focus on building a team that works together to cover these areas, and make sure they have access to subject matter experts (SMEs) to fill gaps in industry or business knowledge. With the right training, these business SMEs can also play the role of “citizen data scientist” using the ever-improving set of user-friendly tools that are bringing data science to the masses.

- Math Knowledge: At its core, data science is applied statistics. In the past, a Ph.D. was a requirement for a data scientist. Today, there are abundant educational resources available online, so data scientists can acquire the math skills they need without spending the time and money on a terminal degree.
- Coding Skills: Data scientists need to get data from where it’s stored to where it can be processed. This can mean getting internal data from data warehouses or data lakes, or it could mean finding creative ways to collect external data. Having the skills to integrate data from multiple disparate data sources is very important. Once the data has been gathered and prepared a data scientist with programming and modeling skills can develop a solution to generate the outputs needed to address the use case.It’s worth mentioning that in the past several years, user-friendly tools like Azure Machine Learning Studio, Alteryx, and Knime have been gaining steam. These tools reduce the programming requirements for citizen data scientists with the right math knowledge and substantive expertise, especially if they can work collaboratively with seasoned data scientists to review and interpret the outputs. Data scientists with programming skills may also use these tools to gain efficiency at times.
- Substantive Expertise: The more domain knowledge a data scientist possesses, the more effectively they are able to design solutions to help your business. This skill takes time to build, so while your data scientists familiarize themselves with your business it is critical that they have access to subject matter experts for guidance. Even as data scientists become experts in the business, it is critical to maintain open lines of communication with business decision makers to keep data science work focused on valuable use cases.
Process: Align the Right Processes
With the strategy and talent in place, the data science team can begin the core work of data science, which is generating statistical models that predict the future or prescribe the best possible action. Aligning to the right process leads to increased likelihood of adoption, organizational trust in model outputs, and clear & structured development process so that standards are clear and model can easily be revisited.
Use Case Management
Once the backlog is developed, the projects need to be prioritized. ROI is a function of the level of effort and the benefits gained, so make an estimate of both and order your use cases according to the associated value.
Model Development
There are some industry standard approaches you can use to drive model development, like Gartner’s Analytic Process, CRISP-DM, or Microsoft’s Team Data Science Process. For each model, the development and tuning process should be documented in detail. Documentation should include analysis of inputs, expected outputs, different models considered, and a history of how various model design decisions were made and adjusted over the course of development.
Building a predictive model often requires subjective decisions. Ensuring that the data scientist makes correct assumptions and includes all relevant data is critical to creating a useful and accurate model. Each model should be independently reviewed to make sure the documentation standards are met, and the model is well-designed. Some industries, like banking, even have regulatory requirements governing the independent validation of models. If you have a large data science practice, you may dedicate a team to model validation. If your practice is smaller, institute a peer review system so all models are scrutinized before they are considered for business use.
Following the independent validation, models should be approved by a governing board that includes executive sponsors. An inventory of active and retired models should be maintained to reflect the board’s decisions. Internal audit should regularly review the full validation and approval process to ensure it functions appropriately.
Model Integration
When the model is ready, users will want predictions to blend simply into their current reporting and operations. Where possible, levels of confidence should be reported alongside predictions to help users evaluate the accuracy of the predictions they receive and to increase adoption.
Model Monitoring & Maintenance
Models may degrade over time as new influencing factors come into play or as data shifts. They need to be reviewed periodically to help them maintain their predictive power. In addition to scheduled reviews, thresholds may be established to trigger an alert if the model inputs or outputs are abnormal. As machine learning becomes more common, well-built models can continually self-adjust over time, but these models should still be subject to monitoring to ensure they continue to provide value. The review board should retire models that no longer serve their purpose and record those changes on the model inventory.
TECHNOLOGY: Support Data Science with the Right Tools
Your data scientists need the right tools to carry out the model development and operationalization processes. A skilled carpenter may be able to frame a house with a hammer, but they can do it faster and drive the nails deeper if they have a nail gun at their disposal. A complete toolset includes development environments and tools for building models, a robust and ample computing architecture to support that development, and infrastructure for deploying the models and making outputs readily accessible.
Development Environment
Languages
Programming languages such as R or Python and the tools used to employ them are at the core of most professional data science work. With these tools, data scientists can leverage a broad array of techniques and capabilities to create flexible and customizable models. Because these languages are open source, there is a rich ecosystem of packages available and an active community of users to provide the support required for building complex data science pipelines.
Language-Based Accelerators
Vendors also offer products that can be utilized through R or Python packages, such as pretrained models for image recognition or natural language processing. These pretrained models can be easily adapted to fit a specific business use case. Other products include tools for automatically generating and evaluating many models with a range of model types and hyperparameters, determining the best option for a particular case. These offerings act as accelerators that can cut down on the development time required to get data science projects up and running.
Graphic-Based Tools
As mentioned earlier, there are also now several graphical tools on the market that guide users through model development. These tools do not require advanced programming skills but may allow custom code to be incorporated. Tools like Azure Machine Learning Studio, Alteryx, and KNIME have easy-to-configure data connectivity both for sourcing data and consuming the results of the model.
Collaboration
While some platforms, such as Databricks and many of the graphical tools, have collaborative workspaces baked in, data scientists can always use filesharing tools, like GitHub, to give shared access to their work and collaborate on projects.
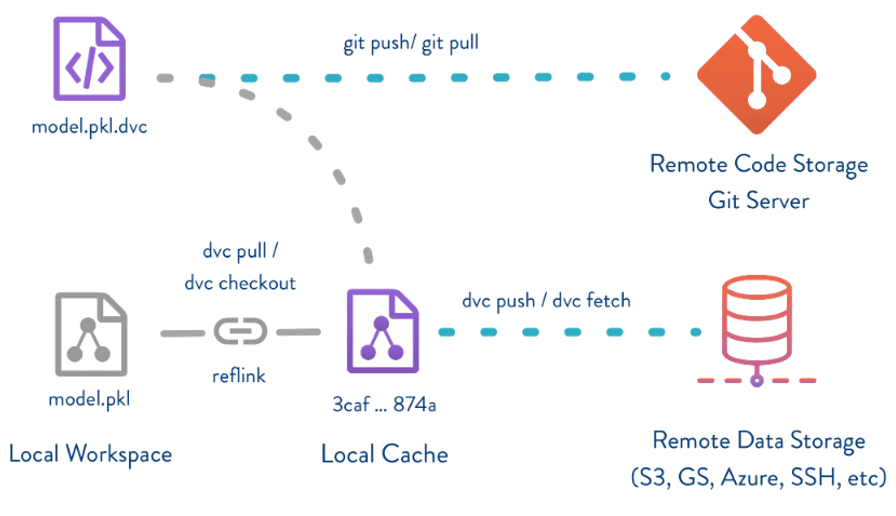
(dvc.org)
Computational Requirements
Training models tends to be rather computationally intensive, particularly when dealing with complex models and large datasets. While some models can easily and quickly be trained on a simple laptop, many others will require more powerful hardware if the task is to be completed in a reasonable time or at all. This can be a significant consideration when selecting the tools and environment for model development. There are many options for powerful on-prem machines as well as virtual-machines provisioned through a cloud provider. The most computationally expensive tasks may require a distributed workload, in which case tools like Databricks, which use Spark, are a convenient option.
Model Deployment and Consumption
Output/Consumption
In many use cases, a model simply needs to make predictions on a scheduled basis for a batch of data at a time. In these instances, it is often appropriate to just have the model write its results into a SQL database or to a CSV in a designated area such as Azure Blob Storage. This makes the predictions readily available to anyone to use for traditional analytics or decision making and is also how the output is often handled for models that are scheduled to automatically run batch jobs. However, in many cases, it is necessary to integrate your model into your business processes so that predictions are being made and consumed on-demand. To achieve this integration and rapid delivery of predictions, some tools make models available through REST APIs. This is ideal when the business calls for streaming analytics, where the model is run on a continual basis and the results are being consumed in real time.

These approaches to model output and consumption can be pursued through either graphical- or language-based platforms, though graphical tools like Azure Machine Learning Studio typically make it more intuitive by sacrificing some room for customization.
Deployment
For some simple use cases, deployment could simply mean an individual running a particular model using their personal laptop on a scheduled basis, though even for the simplest models, this is not preferable. The technology used for deploying your models largely depends on the specific use case, and similarly as with training models, the amount of computational power necessary for making predictions in a timely manner can vary depending on the model and the data.
Many products have made scheduling batch jobs rather simple these days, with it often taking just a few clicks to schedule a script to run on a timely basis. There are many options as to the architecture used for running the script. These options can include, among many others, a Spark cluster, cloud-provisioned VM, on-prem machine, or even utilizing one of the “serverless” computing options on the market.
Similar options are available for on-demand models that are always active, though additional web-facing configurations are required that allow users to call the model with something like a REST API. Other considerations might also need to be made, such as how many users may be reaching out to the model at any given time, which could require hosting multiple instances of the model.
Regardless of the specific technology used to run your model, it is important that you are able to monitor the model to ensure that it is running correctly, as well as keep track of its performance over time. While some platforms have built-in tools for these purposes, there are also other products on the market that handle these things for you.
Data Science Facilitation Tools
Recently, there has been a widespread effort in the data science industry to modularize the different parts of the machine learning lifecycle using pipelines. Pipelines allow for the isolation of tasks such as feature engineering, model training, model testing, and model deployment, so that a data scientist can run them individually and reuse certain components for multiple purposes. Isolating these tasks also enables a more granular approach to version control. Organizing the data science process into pipelines allowed for the creation of several products that lubricate the entire process and simplify the coordination and development of the different pipeline components.
As the machine learning lifecycle has become more solidified, tools have been created that act as a wrapper around the entire process, allowing a data scientist to monitor and keep track of every part of the pipeline. Products such as Azure Machine Learning Service and MLflow facilitate the data science process by tracking experiments conducted by the data scientist and creating a registry of models, with all their previous versions, that can easily be deployed or pulled into a workspace to be called. These tools also allow a data scientist to keep track of a model’s performance over time and to automate model retraining.
Another new and powerful tool to help automate the machine learning lifecycle is Azure MLOps. MLOps allows you to easily monitor and manage your machine learning pipelines with version control, containerized models, and end-to-end auditing.
DATA: Fuel Your Analytics
The greatest hindrance to institutionalized data science is the lack of data. Training machine learning models requires large amounts of quality data and many organizations find themselves searching for ways to incorporate machine learning before having the necessary data to do so. To get the most value out of your data scientists, you must ensure that ample and trustworthy data is readily available for them in whatever form it may take.
Data Procurement
Being prepared for any potential machine learning use case within your organization means collecting data at every possible point. This is rather idealistic and there are constraints on when and how much data can be collected. However, collecting data across the entire organization and its various applications should be a priority when considering how to enable data science within the organization.
Sometimes, though, the necessary data falls outside of the data that your organization has been collecting. In these instances, an organization must be flexible and able to procure more or new data in order to tackle the business problem at hand. This data can frequently come from existing applications within the business but will often have to be gathered from outside sources. Data can be purchased from 3rd party vendors, scraped from the web, or even collected through conducting scientific research trials. Your ability to institutionalize data science within your organization is strongly tied to your ability to supply that data science practice with abundant fuel in the form of extensive and reliable data.
Data Infrastructure
Data can come in many forms, which will influence the infrastructure used to store it. Regardless of the infrastructure used the goal should be to centralize data from across your organization’s different applications and source systems to make it easily accessible. The are two main categories that data can fall into: structured and unstructured.
Structured data is akin to what can be seen in a database table or an excel sheet. Structured data is easy to work with and manipulate. It is often stored in databases and accessed using SQL queries. A common infrastructure approach for structured data is a data warehouse, which is a collection of SQL tables with data that has been collected and standardized from across multiple source systems. This approach allows data scientists to easily find and query the data they need, regardless of where the data originated within the business.
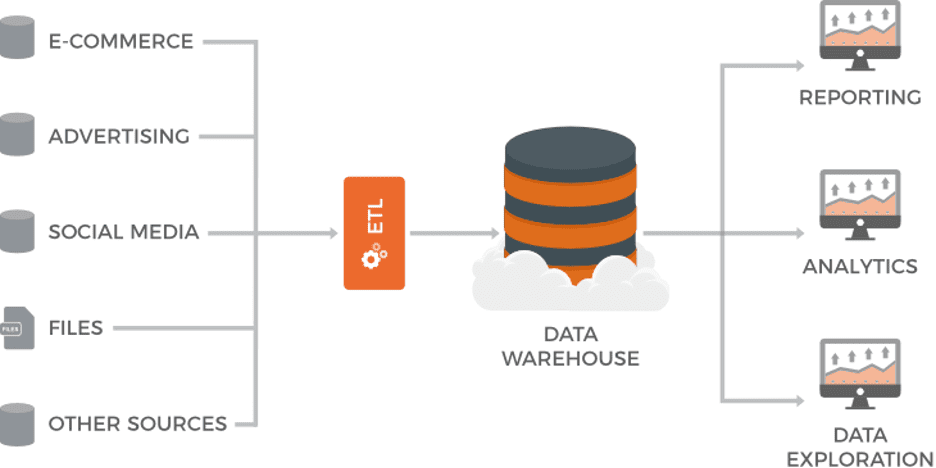
(Mina Nacheva )
Unstructured data is more varied, and can take the form of pictures, video, documents, audio, and others. These types of data cannot be easily stored within a SQL table, making a data warehouse a less-than-ideal solution for storage. Cloud providers have developed several infrastructure solutions for storing unstructured data, including blob storage and data lakes. These offerings allow for data of any type to be stored and accessed within file structures of varying degrees of organization and rigidity.
As the amount of data being collected has drastically increased over recent years, the concept of “big data” has arisen along with infrastructure solutions to accommodate it. Distributed file systems such as HDFS allow for massive amounts of data to be stored across multiple locations, which can then be processed using frameworks such as MapReduce or Spark.
Data Management
Simply centralizing your data and infrastructure is often not enough to maximize your data’s potential. It is important to enforce standards on the data originating from across the business. This standardization allows for a data scientist to know exactly what to expect when retrieving data for use in modeling. Data quality is a key component of this standardization and ensuring that the values in your data are valid and reliable is essential for effective data science. Enforcing these standards also acts as an accelerator to data science because much of a typical data scientist’s energy is devoted to cleaning and prepping data before modeling can begin. Providing data scientists with data that is already clean and reliable will allow you to maximize the value of their time. Want to learn more about data science and data management? Reach out to us today.



