
David Eldersveld recently wrote a blog post showing how to leverage a subset of Microsoft Cognitive Services in Power BI, via AI Insights. AI Insights allows you to detect the language and sentiment of text, extract key phrases from text, and tag images. As David pointed out, enhancing Power BI data models with AI Insights can be beneficial, but you must have Power BI Premium to take advantage of this added functionality.
Fortunately, you can still perform sentiment analysis for free without Power BI Premium if your organization is using SQL Server 2017 or higher. To do this, you will need to use a special stored procedure that leverages R or Python to access a pre-trained model to score your data. Like any stored procedure that returns a data set, it can then be used as a data source for your Power BI data model.
Benefits of the Pre-Built Sentiment Model
Sentiment analysis can be extremely useful across multiple verticals. Some possible scenarios for using the pre-built sentiment machine learning model to enhance Power BI data models include:
- Retail: Add an attribute to the customer dimension table that shows the sentiment score for each customer, based on their reviews.
- Insurance: Add an attribute to the insured dimension table that shows the sentiment score for each insured person, based on historical call logs associated with them.
- Retail: Add an attribute to the product dimension table for each product, based on the reviews for that product.
While not by any means an exhaustive list, the above gives you an idea of how this feature could be applied. There are also some technical benefits associated with SQL Server Machine Learning Services that your IT team might love, including:
- Secure data scoring environment: Security can be a concern when performing data science. Data is often moved from a secure database to a less secure area when data science tasks are performed. With the addition of Machine Learning Services in SQL Server, security is no longer an issue – it allows you to perform data science tasks in one of the most secure locations in the enterprise: the database.
- Easily add ML scoring to your ETL process: Since scoring is done inside a stored procedure, it can be accessed in the same way that you traditionally accessed stored procedures during ETL – via SQL Server Integration Services (SSIS), Azure Data Factory, or, as we illustrated in this example, Power BI.
- Operationalized data scoring: SQL Server Machine Learning Services gives you the option to store your models in a SQL Server table, making them more easily accessible to your R or Python stored procedures. This makes operationalizing your models much easier than historical methods.
- Efficiently score big data sets: One of the historical pitfalls of data science was not being able to score data because it was too big to fit into memory. SQL Server Machine Learning Services gives you access to functions that enable you to overcome that problem. With SQL Server Machine Learning Services, you can score data in chunks, enabling you to score data too big to fit into memory.
Ready to see how it works? Let’s dive in with an example.
The Required Steps
1. Verify that SQL Server Machine Learning Services is installed.
This example requires several installations on your instance of SQL server:
- SQL Server Machine Learning Services
- Pre-trained models
As of this writing, there are two pre-trained models available: one for sentiment analysis and another for image classification. This example focuses on sentiment analysis.
Both of these installations are freely available to the on-prem version of SQL Server 2017 and later. For more information on how to install these on your instance, reference this article for SQL Server Machine Learning Services and this article for pre-trained models.
2. Start defining the special stored procedure.
For this example, we have used a data set of simulated comments that are warehoused in this GitHub repo.
Let’s start by creating an R stored procedure that will use the pre-trained model built by Microsoft to score the comments. We will name the stored procedure [dbo].[getSentiments_R].
We need to declare four variables for this stored procedure: @RScript, @Query, @InputDFName, and @OutputDFName. Here is the T-SQL used to define the variables:
DECLARE @RScript nvarchar(max);
DECLARE @Query nvarchar(max);
DECLARE @InputDFName nvarchar(128) = ‘dfInput’;
DECLARE @OutputDFName nvarchar(128) = ‘dfOutput’;
The @RScript variable will hold the R script that will do the scoring. The @Query variable holds the SQL statement representing the input data to be passed to the R script for scoring. The @InputDFName and @OutputDFName hold the names we will use for the input and output data frames, respectively in the R script. If we don’t specify names, the default names will be InputDataSet and OutputDataSet.
3. Set the values of the @Query and @RScript variables.
Next, we need to set the @Query variable with the string that represents the T-SQL for our input dataset. We also need to set the @RScript variable to hold the R code that will be used to perform the sentiment analysis. The T-SQL script for the @Query variable in this example is as follows:
SET @Query = 'SELECT [id], [text] ' +
'FROM [dbo].[SentimentData]'
It is a simple SELECT statement that grabs the data from the [dbo].[ SentimentData] table needed for the R script. Next, we define the R code needed to score the data. Here is the code:
SET @RScript = '
dfInput$text = as.character(dfInput$text)
sentimentScores <-
rxFeaturize(
data = dfInput,
mlTransforms = getSentiment(
vars = list(SentimentScore = “text”)
)
)
sentimentScores$text <- NULL
dfOutput <- cbind(dfInput, sentimentScores)
'
The script is only four lines long because the pre-trained model does the heavy lifting. In the above R script, the first line changes the text field in the dfInput data frame to a character data type. By default, R converts any character-based fields into a data type called a factor when creating data frames. Factor fields are used for categorical data.
Underneath the hood, the data is stored using a method similar to the dictionary encoding used in Microsoft’s tabular engine. Each unique element in the field is replaced with an integer that serves as an index, and a map is created that maps the index to the unique element it replaces. This technique is beneficial because integers are more efficient to work with and have a lower memory footprint than long strings.
Factors are good for data analysis, but not for the sentiment analysis we are doing. We need access to the actual text in the text field, and that is not easily done when the text field is stored as a factor. Converting the text field to a character data type alleviates this problem.
The next line (actually the next four, due to formatting) performs the sentiment analysis. The workhorse functions are the rxFeaturize() and getSentiment() RevoScaleR functions. RevoScaleR is a R package of R functions built to overcome many of the challenges of working with big data sets.
The rxFeaturize() function enables us to access data that has undergone a machine learning data transformation via MicrosoftML. It specifies the machine learning transformation that is being performed in the mlTransforms argument; which, in this example, is a getSentiment() transformation. The vars argument in getSentiment() is used to specify the fields in the dataset that we want to score. If you specify a named list, as we did in this example, then the name of each element in your list represents the name of the column that will hold the sentiment score, and the value represents the field you want to perform the sentiment on. Note: You can perform sentiment analysis on multiple fields at once. You just need to add an element to your named list using the method previously described.
The getSentiment() function will return a numeric value between 0 and 1 for each sentiment analysis it performs. The closer to 0 the value is, the more negative the sentiment, and the closer to 1 the value is, the more positive the sentiment.
4. Use the sp_execute_external_script special stored procedure to execute the R script.
EXEC sp_execute_external_script
@language = N’R’
,@input_data_1 = @Query
,@input_data_1_name = @InputDFName
,@output_data_1_name = @OutputDFName
,@script = @RScript
A special stored procedure named sp_execute_external_script will execute our R code. This stored procedure is used to execute code written in languages other than T-SQL inside SQL Server. This stored procedure supports three languages as of this writing: R, Python, and Java.
The parameters you need to supply depends on the R script. In our case, we need to supply five parameters.
@language is used to specify the language we are using
@input_data_1 represents the T-SQL code needed to create the input dataset.
(@input_data_1_name represent the names that the R script will use to refer to the input data frames
@output_data_1_name) represents the names that the R script will use to refer to the output data frames
@script will hold the R script that does the sentiment analysis
5. Use WITH RESULT SETS to define the output returned by the sp_execute_external_script.
We add the T-SQL code below to the end of our sp_execute_external_script:
WITH RESULT SETS (
(
[id] [bigint],
[text] [varchar](8000),
[score] [float]
)
)
This code is used to add data types and names to the output. Without this code, the resulting dataset will not have column names, and SQL Server will determine the data types. This can cause problems when fetching data from this stored procedure in Power BI. The WITH RESULTS SETS clause prevents this issue by allowing us to explicitly define the name and data type of each column.
6. Call the stored procedure from Power BI.
Below is the entire T-SQL script needed to create the stored procedure:
CREATE PROCEDURE [dbo].[getSentiments]
AS
BEGIN
DECLARE @RScript nvarchar(max);
DECLARE @Query nvarchar(max);
DECLARE @InputDFName nvarchar(128) = ‘dfInput’;
DECLARE @OutputDFName nvarchar(128) = ‘dfOutput’;
SET @Query = ‘SELECT [id], [text], [likes] ‘ +
‘FROM [dbo].[SentimentData]’
SET @RScript = ‘
dfInput$text = as.character(dfInput$text)
sentimentScores <-
rxFeaturize(
data = dfInput,
mlTransforms = getSentiment(
vars = list(SentimentScore = “text”)
)
)
sentimentScores$text <- NULL
dfOutput <- cbind(dfInput, sentimentScores)
‘
EXEC sp_execute_external_script
@language = N’R’
,@input_data_1 = @Query
,@input_data_1_name = @InputDFName
,@output_data_1_name = @OutputDFName
,@script = @RScript
WITH RESULT SETS (
(
[id] [bigint],
[text] [varchar](8000),
[score] [float]
)
)
END
After you execute the T-SQL script inside of SQL Server Management Studio, the [dbo].[getSentiments] stored procedure will be added to your data base. Open up Power BI then go to Get Data > SQL Server to get to the form that you will use to add the T-SQL code needed to execute the [dbo].[getSentiments] stored procedure. Below is a image of the form:
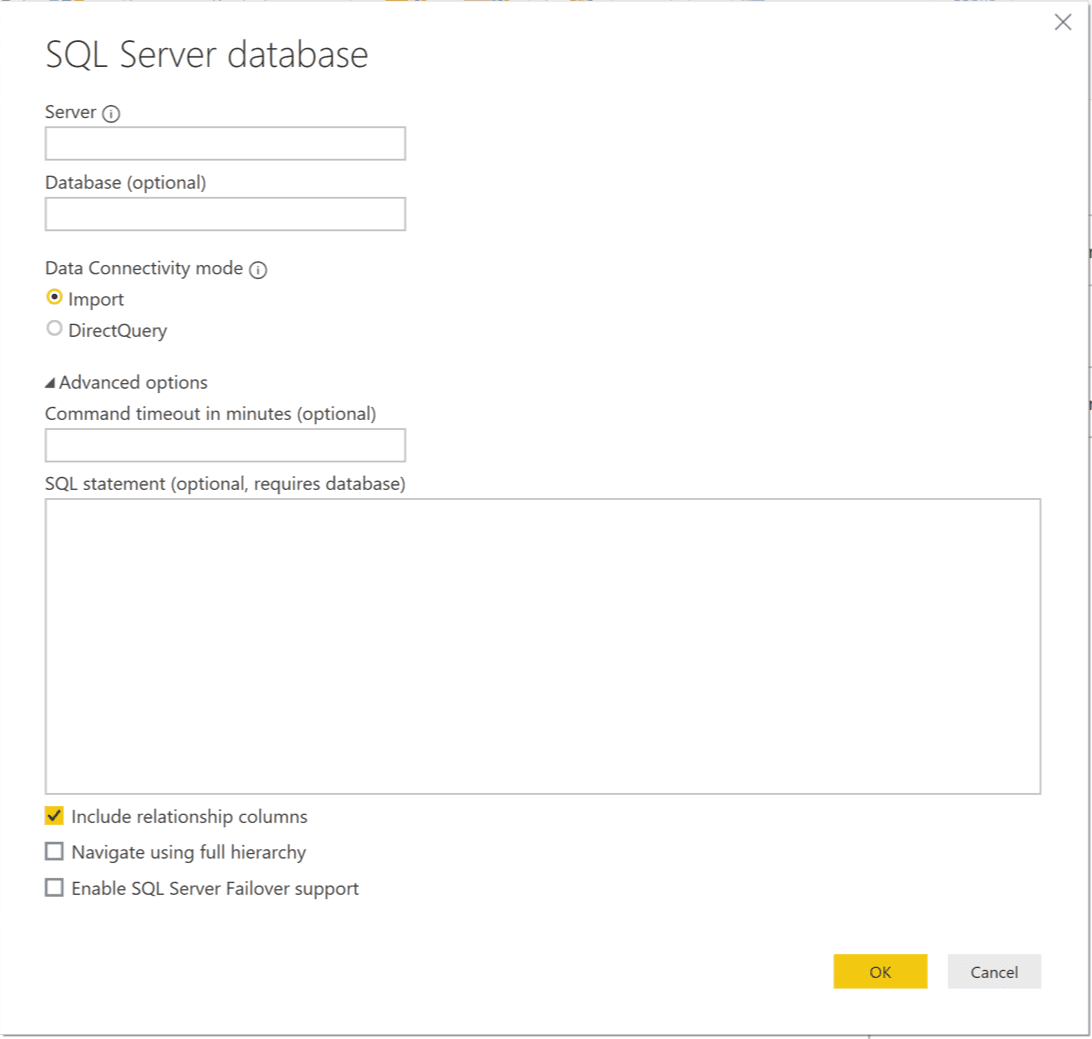
Configure the form by populating the Server text box with the server name, the Database text box with the database name, and be sure to expand the Advanced options to expose the SQL statement (optional, requires database) text box. Place the following T-SQL code in that textbox:
EXEC [dbo].[getSentiments_R]
Click the OK button to execute the stored procedure and expose the output to Power BI. Here is what the output looks like in our example:
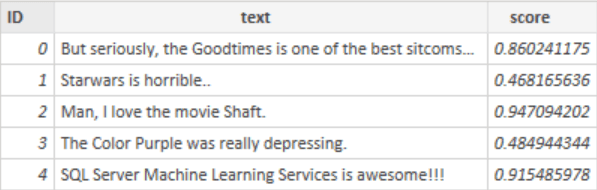
You can either add the resulting dataset to the data model as is, or you can make further transformations to the data using Power Query. In this example, an obvious transformation would be to create a categorical field based on the score field that labels each text as positive or negative. We can say that any score greater than or equal to 0.5 is positive, and any score less than 0.5 is negative. Feel free to use a different threshold as needed.
I hope you are half as excited as I am about leveraging SQL Server Machine Learning Services to enhance your Power BI data models. In this post we used R, but this GitHub Repo contains the information you need to do the same in Python.



