
Looking for faster query performance? Azure SQL Data Warehouse Gen2 has five times the compute capacity, as well as the huge benefit of providing faster query performance than the Gen1 offering.
Let me tell you how Gen2 achieves this faster query performance. Check out the diagram below which shows the architecture of the Azure SQL Data Warehouse platform.
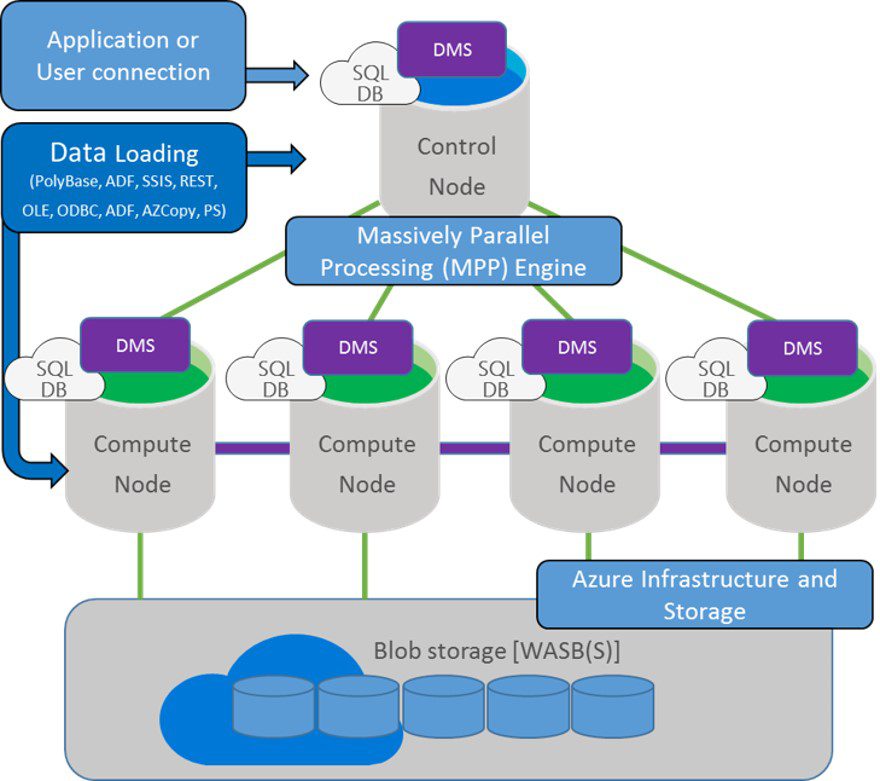
The key factor to understand is that this platform uses Massive Parallel Processing. The idea here is we would issue a query to one control node (as shown in the top). And that control node distributes that query across multiple compute nodes (as seen in the middle tier of this illustration). Those queries then run in parallel on those compute nodes to render a partial result that gets rolled up to that control node.
Now, let’s talk about the performance of Gen2 by focusing on the bottom of the diagram which is the storage. The data storage for Azure SQL Data Warehouse Gen1 is stored remotely in Azure Blob Storage. This is a key feature of the architecture as the compute power and the storage are managed independently and separately.
We still have the same fundamental architecture in Gen2 with our data still stored remotely in Blob Storage. But in this next diagram, I want to talk about what has changed in Gen2 to enable this faster query performance.
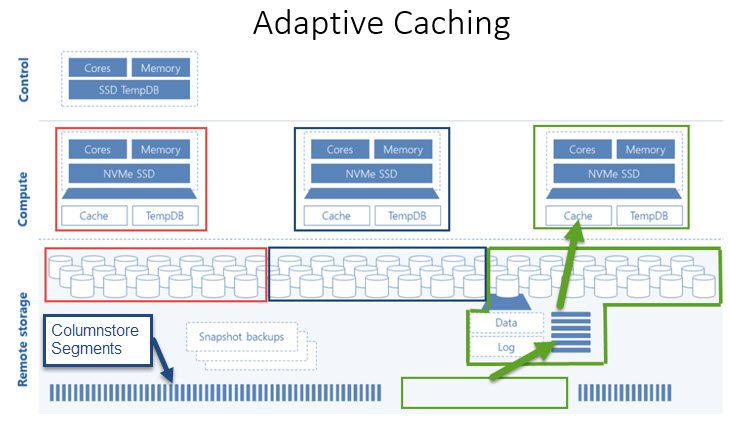
1. There was new hardware introduced to the Azure platform, so Gen2 is running on a new version and a new generation of hardware. Part of that includes SSDs on the compute nodes which is part of where we get the speed from.
2. But the real focus is on the introduction of adaptive caching as far as this faster query performance. The notion of adaptive caching means that when we use columnstore indexes, previously all of that data was stored remotely in blob storage.
What adaptive caching does is it brings certain columnstore segments into the compute node itself. So now depending on the query that I execute, if my query can be resolved by data that has been moved into the compute node, it reduces or eliminates the IO required to go out to that remote storage.
This adaptive caching is the real key of how Gen2 achieves that high query performance. I also want to point out about the word ‘adaptive’ is that columnstore indexes that are brought into the compute node will depend on past query execution, so it will understand the history of queries that you’ve run.
Using this history, it will decide to bring in those columns to our segments that might help you resolve a similar query in the future. It will also develop a pattern based on the thought of ‘if you’ve run that query, you may also run this query’, so it will bring those columns into our segments as well. The main idea here is to bring that data into the compute node and reduce or eliminate the need to read that data from the remote blob storage.
So, if you’re looking to get better, faster query performance, I’d advise you to check out Azure SQL Data Warehouse Gen2.
Need further help? Our expert team and solution offerings can help your business with any Azure product or service, including Managed Services offerings. Contact us at 888-8AZURE or [email protected].



