
Data science brings the prospect of solving complex business problems with math. Along with that comes more advanced application development that blends rules-based decision patterns with intelligence like machine learning. This is no easy task, as it requires the confluence of the right data, the business will, and varied skill sets like developer, statistician, business analyst, data engineer/architect, and project manager. Further, no one’s happy unless this can be done at scale and speed, and applied to many areas of the business. No wonder global tech consultant Capgemini finds that only 27% of organizations describe their Big Data initiatives as “successful“.
Lots has been said about ways to organize data science teams to maximize effectiveness. I’ll put the bottom line up front: Research giant Gartner finds there is “no overall best practice”. Rather, they contend that the important components of “sharing best practices, procuring management buy-in, and launching and managing cross-functional analytics projects” can be achieved using a variety of structures. Although there’s no definitive answer on organization, it’s worthwhile to explore some advantages and disadvantages of different options. Additionally, an excellent data science process can help overcome some of the biggest organizational hurdles. And because organizational structure can and should change as analytic capability matures, establishing process as a main concern can offer a foundation of consistency along the journey.
There are many excellent articles (see references below) on how to organize data science/business intelligence teams, and it’s worth reading the details. But for the most part, it boils down to a decision about how centralized (aligned with IT) or de-centralized (aligned with business or functional units) the teams are. Advanced analytics activities, both historically and currently, most commonly take place close to focused challenges like marketing mix or manufacturing optimization, where smart math/science folks work closely with business managers to develop ad hoc or custom solutions. This close association has the advantage of business intimacy and responsiveness, but often lacks scalability to operational systems, the means for knowledge sharing with other groups, and consistency between projects. Some of you might know this as “the Wild West” model, where data governance and documentation is on the outside looking in and everyone is doing their best to get things done with whatever tools they have.
The more IT-aligned model advocates a centralized, shared-services model for data science projects. Teams with this organization often realize benefits from closer proximity to operational systems and data stores, and can provide more cross-functional and consistent assets from working on a variety of problems. The disadvantage with this more top-down approach is the distance from day-to-day contact with business challenges, longer wait times (usually), and trying to deliver solutions that may have disparate requirements for modeling and reporting in each department or functional area. Other hybrid approaches include creating a separate Advanced Analytics group outside of IT and lines of business (LOBs), or a mix of groups both in IT and in LOBs. Guidance for choosing which organization fits best include whether an analytics center of gravity (i.e. Chief Analytics Officer, Analytics Center of Excellence, etc.) currently exists, how projects or groups are funded, the urgency for analytics innovation, and the quality of existing data science assets. This last element about current asset condition can be quite broad, but we’ll focus on issues like collaboration between groups and consistent delivery as we discuss process considerations.
As advanced analytics becomes more operationalized through intelligence in applications, data science practitioners need to learn and adopt better project and knowledge management processes that are standard in traditional IT development. Data science has well-known methodologies like CRISP-DM that provide solid guidance on major project life-cycle elements like modeling and evaluation. But they lack details on artifacts that should be produced, such as project templates and utility code, that can greatly increase productivity. Microsoft, with established tools like Visual Studio Team Services for software development, has developed an attractive, integrated process for advanced analytics called the Team Data Science Process (TDSP) that I believe can be a tremendous asset. Here’s a slide from Microsoft’s recent (recorded) presentation about TDSP at their Data Science Summit:
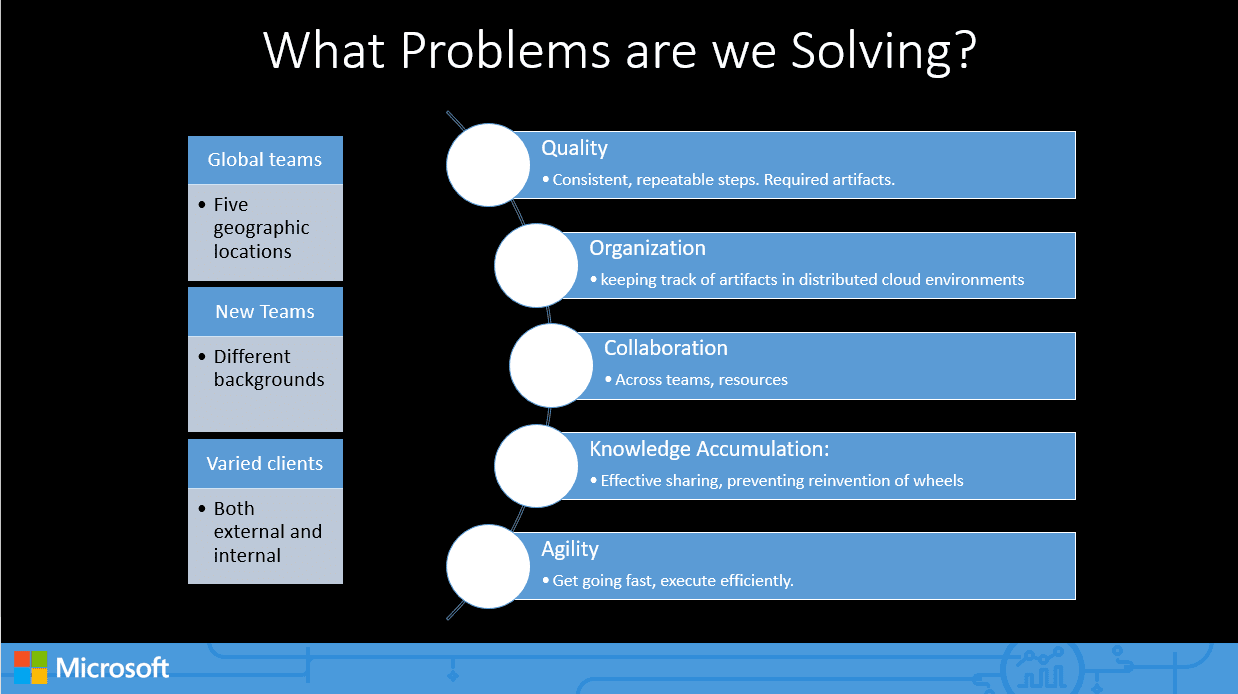
In Microsoft’s own words about TDSP, “The key feature is a set of (free) git-based repositories with templates providing a central archive with a standardized project structure, document templates, and utility scripts for all projects, independent of the execution environment, to allow scientists to use multiple cloud resources as needs dictate. We use Visual Studio Team Services (VSTS) to manage team tasks and execution cadence, control access, and maintain repositories containing work items.” Learning the git system for source control is probably the biggest productivity boost I’ve acquired in the last year; I think all analytics professionals can benefit. Here’s a look at the git repositories structure in TDSP:
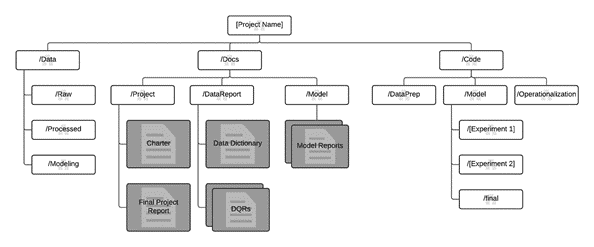
Not only has Microsoft provided the structure and templates for project management artifacts in the repositories, it’s thrown in lots of valuable data science and cloud provisioning utilities as well: a data report script in R for interactive exploratory data analysis, a script for automatically exploring different models, and scripts for automatically connecting to Azure data sources and standing up virtual machines. A final important point is that tasks assigned to individuals in VSTS can be linked to git branches so that project management items, code, and versioning are all tracked together – pretty cool!
This article has attempted to go broad, not deep, on the topics of analytics team organization and process. I’d encourage interested readers to follow the links to learn more. We are in the early days of understanding the optimal way to organize powerful predictive analytics capabilities; if you feel like it’s a bit out of control, you’re not alone. Hopefully this discussion provides some useful ways to get even more out of your analytics teams!
Links:
Capgemini: Cracking the Data Conundrum: How Successful Companies Make Big Data Operational
Gartner: Organizational Principles for Placing Advanced Analytics and Data Science Teams
Gartner: Create a Centralized and Decentralized Organizational Model for Business Intelligence
PWC: Data and Analytics: Creating or destroying shareholder value?
Microsoft TDSP documentation



