In this article we will demonstrate how to featurize text in tabular data using Google’s state-of-the-art T5 Text to Text Transformer. You can follow along using the Jupyter Notebook from this repository.
When trying to leverage real-world data in a machine learning pipeline, it is common to come across written text — for example, when predicting real estate valuations there are many numerical features, such as:
- “number of bedrooms”
- “number of bathrooms”
- “area in sqft”
- “latitude”
- “longitude”
- &etc…
But also, there are large blobs of written text, such as found in real estate listing descriptions on sites like Zillow. This text data can include a lot of valuable information which is not otherwise accounted for in the tabular data, for example:
- mentions of an open kitchen/floor-plan
- mentions of granite counters
- mentions of hardwood floors
- mentions of stainless steel appliances
- mentions of recent renovations
- &etc…
Yet, surprisingly, many AutoML tools entirely disregard this information because written text cannot be directly consumed by popular tabular algorithms, such as XGBoost.
This is where Featuretools primitive functions come in. Featuretools aims to automatically create features for different types of data, including text, which can then be consumed by tabular machine learning models.
In this article we show how to extend the nlp-primitives library for use with Google’s state-of-the-art T5 Text to Text Transformer model, and in doing so, we create the most important NLP primitive feature, which in turn improves upon the accuracy demonstrated in the Alteryx blog Natural Language Processing for Automated Feature Engineering.

For any readers unfamiliar with T5 — the T5 model was presented in Google’s paper titled Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer by Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. Here is the abstract:
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a diversity of approaches, methodology, and practice. In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks. By combining the insights from our exploration with scale and our new “Colossal Clean Crawled Corpus”, we achieve state-of-the-art results on many benchmarks covering summarization, question answering, text classification, and more. To facilitate future work on transfer learning for NLP, we release our dataset, pre-trained models, and code.
A Machine Learning Demo Featurizing Text using Hugging Face T5

Image/logo by Hugging Face Transformers library — Transformers is a natural language processing library and a hub is now open to all ML models, with support from libraries like Flair, Asteroid, ESPnet, Pyannote, and more.
In order to extend the NLP primitives library for use with T5, we will build two customTransformPrimitive classes. For experimental purposes we test two approaches:
- Fine-tuning the Hugging Face T5-base
- An off-the-shelf Hugging Face T5 model pre-tuned for sentiment analysis
First, let’s load the base model.
from simpletransformers.t5 import T5Modelmodel_args = { "max_seq_length": 196, "train_batch_size": 8, "eval_batch_size": 8, "num_train_epochs": 1, "evaluate_during_training": True, "evaluate_during_training_steps": 15000, "evaluate_during_training_verbose": True, "use_multiprocessing": False, "fp16": False, "save_steps": -1, "save_eval_checkpoints": False, "save_model_every_epoch": False, "reprocess_input_data": True, "overwrite_output_dir": True, "wandb_project": None, }model = T5Model("t5", "t5-base", args=model_args) |
Second, let’s load the pre-tuned model.
| model_pretuned_sentiment = T5Model(‘t5’, ‘mrm8488/t5-base-finetuned-imdb- sentiment’, use_cuda=True) model_pretuned_sentiment.args |
In order to fine-tune thet5-basemodel, we need to reorganize and format the data for training.

From the Kaggle dataset, we will map thereview_textcolumn to a new column calledinput_text, and we will map thereview_ratingcolumn to a new column called target_text, meaning thereview_rating is what we’re trying to predict. These changes conform to the Simpletransformers library interface for fine-tuning t5, whereby the main additional requirement is to specify a “prefix”, which is meant to assist with multi-task training (NOTE: in this example, we are focusing on a single task, so the prefix is not necessary, but nonetheless we will define it anyway for ease of use).
dft5 = df[['review_text','review_rating'] ].rename({ 'review_text':'input_text', 'review_rating':'target_text' },axis=1)dft5['prefix'] = ['t5-encode' for x in range(len(dft5))]dft5['target_text'] = dft5['target_text'].astype(str)dft5 |
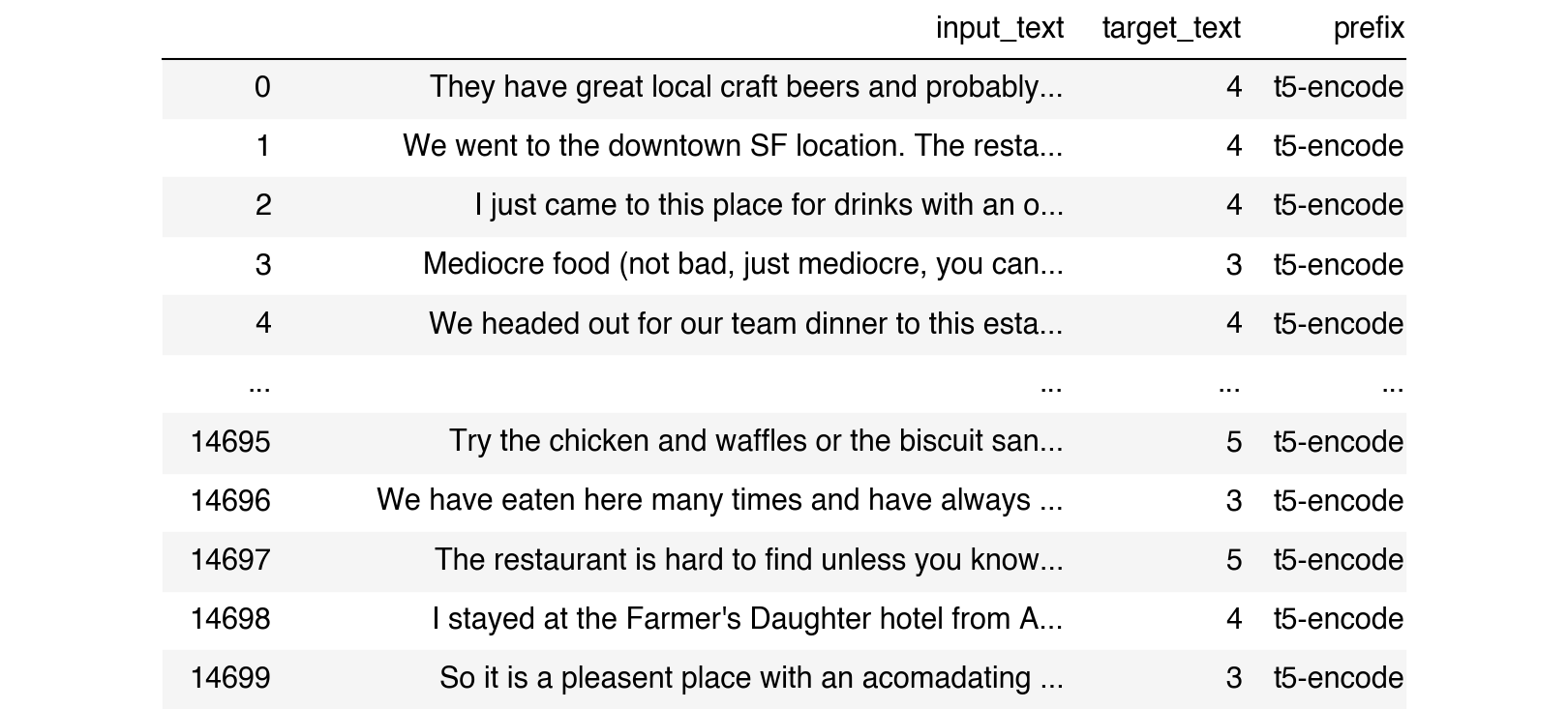
The target text in this example is the ratings consumers gave to a given resteraunt. We can easily fine-tune the T5 model for this task by the following:
from sklearn.model_selection import train_test_splittrain_df, eval_df = train_test_split(dft5)model.train_model(train_df, eval_data=eval_df) |
Next, we load the pre-tuned Hugging Face model.
| model_pretuned_sentiment = T5Model(‘t5’, ‘mrm8488/t5-base-finetuned-imdb-sentiment’, use_cuda=True) |
Let’s test both models to better understand what they will predict.
test = ['Great drinks and food', 'Good food & beer', 'Pretty good beers']list(np.array(model.predict(test)).astype(float)) Generating outputs: 0%| | 0/1 [00:00<?, ?it/s] Generating outputs: 100%|██████████| 1/1 [00:00<00:00, 3.17it/s] Generating outputs: 100%|██████████| 1/1 [00:00<00:00, 3.16it/s] Decoding outputs: 0%| | 0/3 [00:00<?, ?it/s] Decoding outputs: 33%|███▎ | 1/3 [00:00<00:01, 1.14it/s] Decoding outputs: 100%|██████████| 3/3 [00:00<00:00, 3.43it/s] Out[14]: [4.0, 4.0, 4.0] |
We can see that the fine-tuned model outputs a list of review_rankings[4.0, 4.0, 4.0] which is an attempt to predict the final answer to our problem.
Next, let’s do a test prediction using the pre-tuned Hugging Face model.
test = ['Great drinks and food', 'Good food & beer', 'Pretty good beers']list(np.where(np.array(model_pretuned_sentiment.predict(test))=='positive', 1.0, 0.0)) Generating outputs: 0%| | 0/1 [00:00<?, ?it/s] Generating outputs: 100%|██████████| 1/1 [00:00<00:00, 7.57it/s] Generating outputs: 100%|██████████| 1/1 [00:00<00:00, 7.56it/s] Decoding outputs: 0%| | 0/3 [00:00<?, ?it/s] Decoding outputs: 33%|███▎ | 1/3 [00:00<00:01, 1.17it/s] Decoding outputs: 100%|██████████| 3/3 [00:00<00:00, 3.50it/s] Out[15]: [1.0, 1.0, 1.0] |
Note that the pre-tuned model outputs a list of boolean True/False values which indicate whether a statement was positiveornegative— we convert these into float values for better integration with tabular modeling. In this case, all values are true, so the output becomes [1.0, 1.0, 1.0].
Now that we’ve loaded our two versions of T5 we can buildTransformPrimitive classes which will integrate with the NLP Primitives and Featuretools libraries.
| from featuretools.primitives.base import TransformPrimitive from featuretools.variable_types import Numeric, Text class T5Encoder(TransformPrimitive): name = “t5_encoder” def __init__(self, model=model): def get_function(self): def t5_encoder(x): |
The above code creates a new class calledT5Encoder which will use the fine-tuned T5 model, and the below code creates a new class called T5SentimentEncoderwhich will use the pre-tuned T5 model.
| class T5SentimentEncoder(TransformPrimitive):
name = “t5_sentiment_encoder” def __init__(self, model=model_pretuned_sentiment): def get_function(self): def t5_sentiment_encoder(x): |
Featuretools will now know how to use T5 to featurize text columns, and it will even calculate aggregates using the T5 output, or perform operations with it, such as subtracting the value from other features. Having defined these new classes, we simply roll them up in the required Featuretools format along with the default classes, which will make them available for use with automated feature engineering.
| trans = [ T5Encoder, T5SentimentEncoder, DiversityScore, LSA, MeanCharactersPerWord, PartOfSpeechCount, PolarityScore, PunctuationCount, StopwordCount, TitleWordCount, UniversalSentenceEncoder, UpperCaseCount ] ignore = {‘restaurants’: [‘rating’], drop_contains = [‘(reviews.UNIVERSAL’] features = ft.dfs(entityset=es, |
As you can see in the output below, the Featuretools library is very powerful! In fact, in addition to the T5 features shown here, it also created hundreds more using all of the other NLP primitives specified, pretty cool!
feature_matrix = ft.calculate_feature_matrix(features=features,
entityset=es,
verbose=True)features
|
Out[20]:
- <Feature: T5_ENCODER(review_title)>
- <Feature: T5_SENTIMENT_ENCODER(review_title)>
- <Feature: restaurants.MAX(reviews.T5_ENCODER(review_title))>
- <Feature: restaurants.MAX(reviews.T5_SENTIMENT_ENCODER(review_title))>
- <Feature: restaurants.MEAN(reviews.T5_ENCODER(review_title))>
- <Feature: restaurants.MEAN(reviews.T5_SENTIMENT_ENCODER(review_title))>
- <Feature: restaurants.MIN(reviews.T5_ENCODER(review_title))>
- <Feature: restaurants.MIN(reviews.T5_SENTIMENT_ENCODER(review_title))>
- <Feature: restaurants.SKEW(reviews.T5_ENCODER(review_title))>
- <Feature: restaurants.SKEW(reviews.T5_SENTIMENT_ENCODER(review_title))>
- <Feature: restaurants.STD(reviews.T5_ENCODER(review_title))>
- <Feature: restaurants.STD(reviews.T5_SENTIMENT_ENCODER(review_title))>
- <Feature: restaurants.SUM(reviews.T5_ENCODER(review_title))>
- <Feature: restaurants.SUM(reviews.T5_SENTIMENT_ENCODER(review_title))>