
In nearly every meeting I’ve had with customers to talk about building a Data Lake, a single question has been asked: “How do I prevent my Data Lake from becoming a Data Swamp?”
The answer is organization. Hard work, governance, and organization.

Data Lakes Aren’t Inherently Organized
It’s true that Data Lakes are, in some ways, nothing more than a big block of storage. There is nothing preventing a Data Lake from becoming a mess of disorganized files. This is why, when you first implement a Data Lake, you will need to design some basic organizational structures up front.
Before you even begin loading data, you should divide your Data Lake into the following four main areas.
Staging
The Staging area of your Data Lake is a place for data to rest as it’s moving from a source system to another area. It is primarily used by data ingestion systems as a landing zone for new data. It may also be used as a place for minor processing, such as merging many small files into in one larger file for storage in the Raw layer.
Raw or Persisted
The Raw or Persisted area of your Data Lake is where data is kept indefinitely in its raw format. It may have undergone some minor processing, such as combining many small files into a few larger files, but for the most part the data has remained untouched.
One of the biggest benefits of a Data Lake is the ability to keep a copy of stored data in its original, raw format. Agility is a big selling point for the Data Lake – since we don’t always know every use case for the data, it’s often difficult to know exactly what shape it should be in for future solutions. By making a copy of the original data available at all times, we can be assured that we’ll be able to apply new formatting, processing, and cleansing should the need arise.
Analytic or Curated
In this section of the Data Lake, the data has been heavily processed. Sometimes it is aggregated and stored in a star schema-like format to conform with different reporting and analysis tools.
The Curated area of your Data Lake should be one of your most governed locations. Since the data living here has been heavily processed, it will also be under a high level of scrutiny. It should be protected just as much as your Data Warehouse, because this is the area that most users will have access to and will use to read appropriate data assets.
The Curated area will also serve as the home for your online Data Warehouse archive. By storing a copy of your star schema in the Curated area, you can easily run queries similar to what we would ask of the Data Warehouse. Additionally, we can use technology such as SQL Server PolyBase to merge the results of live Data Warehouse data and online archived data in the Data Lake with a single query.
Sandbox
The Sandbox is designed to be used by deep analysts and scientists as an unmanaged area. Data can be added here by any user, and doesn’t require a governance process, although we suggest that users self-govern their own data. This area is not designed to be used by the general populace for reporting, but rather by a much smaller user group focused on experimenting and exploring new data concepts and solutions.
The sandbox is unique to the Data Lake. It is uncommon for a user community to have unfettered access to a database server and be allowed to store any data in any shape. But with a Data Lake, that access is happily granted. Because we can granularly apply security to a Data Lake, this ensures the Sandbox users won’t be able to adversely affect other sections of the Data Lake.
Here is a review of the four main areas of the Data Lake and how each area relates to User Access, Governance, and what level of Data Processing the data undergoes:
| Staging | Raw | Analytic | Sandbox | |
| User Access | None | Limited | Full Read (by Role) |
Read / Write |
| Governance | None | Basic | Full | Minimal but User Managed |
| Data Processing | None | Minimal | Heavy | Minimal based on use |
Further Organization
Beyond the high-level organization patterns mentioned above, it’s also important to keep each section of the Data Lake organized. The organization pattern chosen will vary based on the needs of your business case, but I’d like to propose the following template. This template will not only ensure continued organization and easier governance, but it will also provide a level of self-documentation. By looking at the folder structure, it will be easy to understand what area of the business this data applies to, where it came from, and its general use.
Most data in the Data Lake can be organized into its use case, and all data comes from a source system. Beyond that, there will be specific formats for each data source. Therefore, following a directory structure that looks similar to the following example is a good starting point.
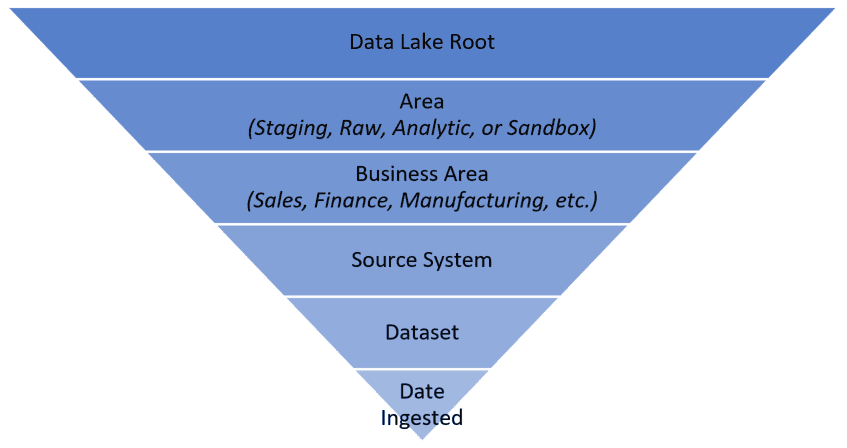 Nearly all compute engines that work with a Data Lake are designed to read data per folder, so it is important to ensure that data in a single folder is all similarly shaped. With this assurance, it is possible for the data transformation process to fail due to incorrectly defined data structures.
Nearly all compute engines that work with a Data Lake are designed to read data per folder, so it is important to ensure that data in a single folder is all similarly shaped. With this assurance, it is possible for the data transformation process to fail due to incorrectly defined data structures.
For example, it is possible to create a Hive table that is pointed at a single file, but it is much more common to set the location of a Hive table to be an entire directory of files. If we define a table that describes a 4-column pipe-separated file, and one of the files in the directory has 9 columns, we’ll get unexpected data returned from user queries and data transformation routines.
Ensure Successful Implementation
When implementing your first Data Lake, planning your organization pattern should be one of the first tasks you complete. I’ve suggested in this article that you should segregate your Data Lake into four main areas:
- Staging – for data ingestion and movement
- Raw – for storing original copies of data in its raw format indefinitely
- Curated – for data storage that is heavily transformed, perhaps into a star schema for analysis
- Sandbox – to enable analysts and scientists the opportunity to work with, collect, and transform new data without the need for heavy controls
Within each of the separate areas, it is important to apply logical organization by Business Area, Source System, and dataset format. Individual considerations for each dataset can be reviewed and integrated as needed.
Continued success with a Data Lake will rely on reviews of the organizational format and continued governance of the data stored in the Data Lake. If you still have questions or are looking for more information on Data Lakes, contact us, and we will be happy to help get your project going in the right direction!



