
A typical pattern in retail scenarios involving multiple sales locations is that each periodically uploads its respective transaction summary information to a central entity (e.g., corporate headquarters) where total sales can be aggregated and analyzed. For our purposes, let’s assume that these sales locations each submit daily summary files detailing every sales transaction that occurred throughout the day. Let’s further assume that these locations exist in multiple time zones, with varying hours of operation, and that these summary files, possibly also requiring some human action to be performed before being finalized, will be sent at different times.

For data processing purposes, the process above can be imagined as a streaming scenario, which is easily implemented in Spark on Azure Databricks. But practically speaking, it is common for uploads of this nature to fail, arrive late, or even to be resubmitted with additions or corrections, thereby introducing redundancy that requires reconciliation. We therefore require a streaming destination that is robust enough to accommodate the dynamic nature of the business process.
Fortunately, Delta Lake is perfectly suited for this situation. And, in a scenario that routinely comingles both inserts and updates, what we really want is a “merge” pattern, also called an “upsert.”
In our example, files are being uploaded via an external process to a date-specific folder in Azure Data Lake and are distinguished from one another by a naming convention which consists of the Date and Time and StoreId (e.g., 201906210916_1000.json). But for our purposes, we will never look at nor query individual files. (Note that discussion of a robust data lake partitioning strategy is beyond the scope of this article. For further reading about data lake best practices, see BlueGranite’s eBook, “Data Lakes in a Modern Data Architecture”.)
Given sample file content such as the following, in JSON format, we see that it includes a store identifier, date, and an array of transactions. (Note that multi-line JSON is discouraged for performance reasons, but is intentionally used here as a more likely reflection of a real-word scenario.)

We start by defining the schema of our sales document.

Then we create a streaming dataframe over the folder(s) into which our sales summary files are being uploaded. In this step we also explode sales transactions onto rows, which will help later with sales aggregation. We also derive a date key, which will help both with aggregation, and in construction of our merge statement to handle resubmissions.

Next, we need to create a Delta table as a destination.

Ideally, we want to stream directly to the Delta table, as opposed to performing a batch upsert. At this time, such an operation requires Scala (more about this here). Meanwhile, the MERGE statement itself should be familiar to anyone who has prior experience working with merges in SQL.
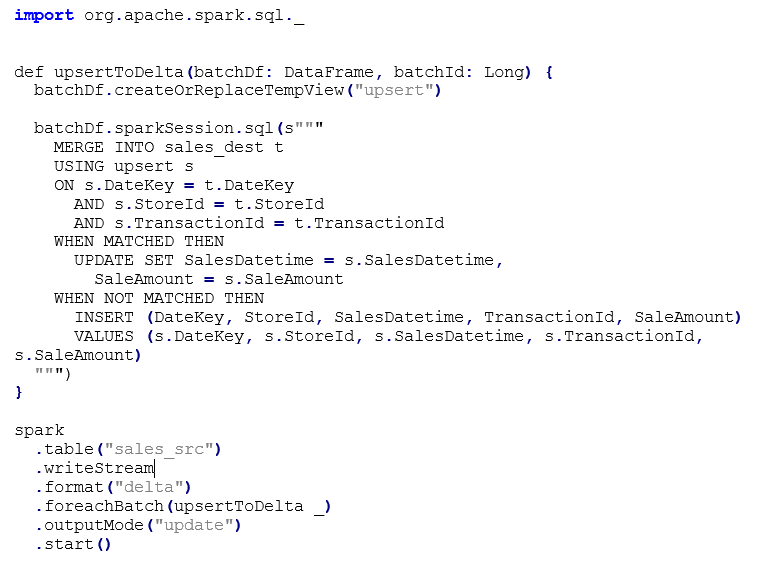
Finally, we query our Delta Lake table and review the aggregated sales totals for three stores.
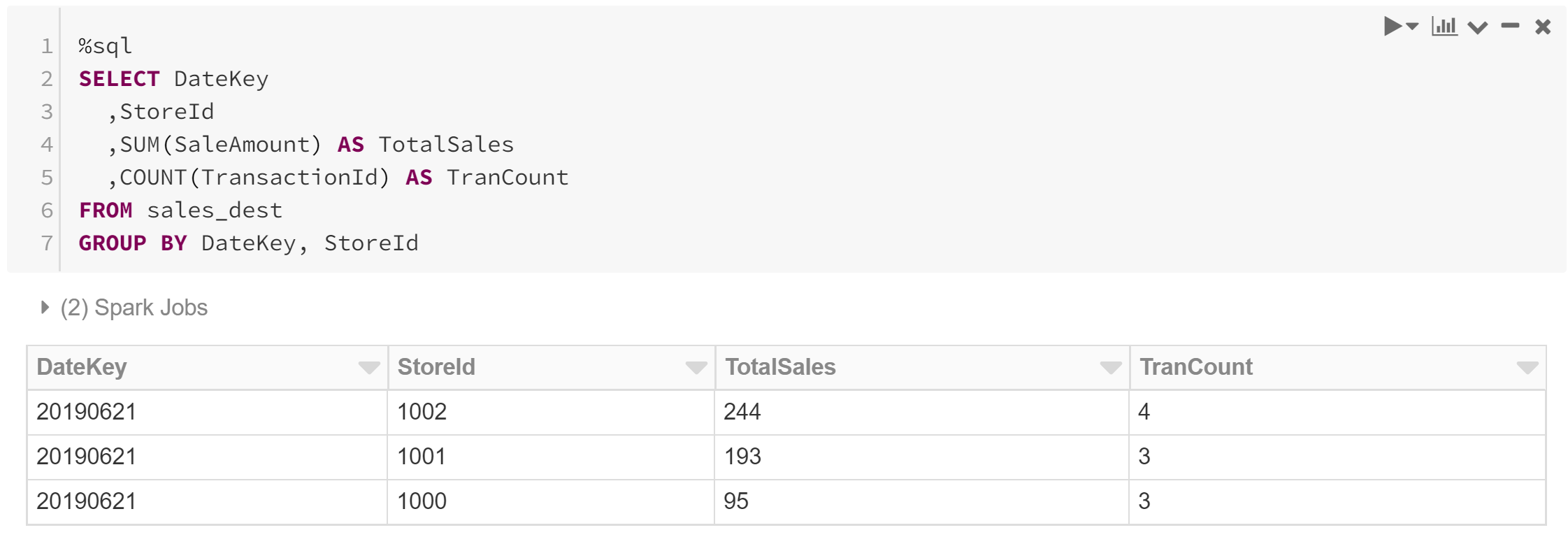
Later, we find that our first store has resubmitted its daily sales summary, although the file that was previously submitted remains unmodified and is neither overwritten nor removed. In addition, a fourth store has now submitted its summary file.

The revised sales summary for store 1000 contains an additional transaction, as well as a change to an existing transaction.

But observe that no further effort is required to process or retrieve the results of these updates. We simply execute the exact same query as before, but now we receive the updated results. Our streaming merge has seamlessly and transparently reconciled the data changes!
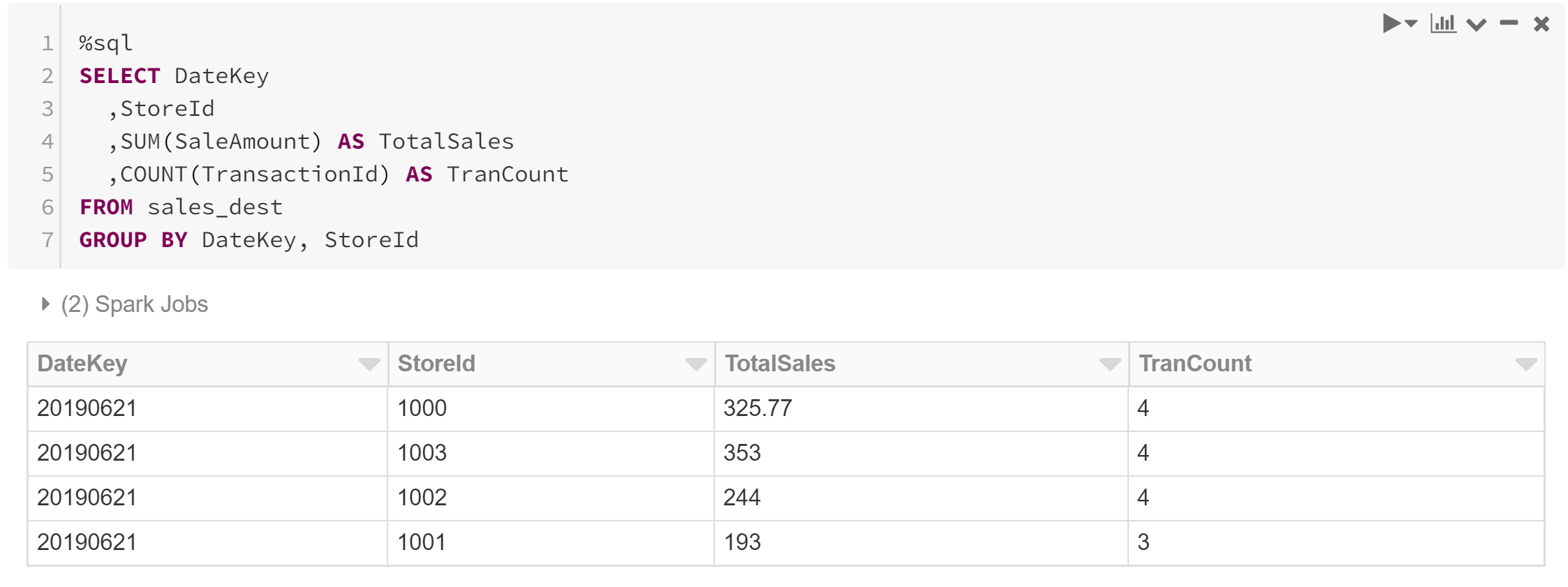
The key takeaway here is that once our process is in place, thanks to Delta Lake, no further action is required to update or reconcile the incoming data.
If you have questions or are interested in more Delta Lake information, contact BlueGranite. We’d love to help steer your project in the right direction!



