
Keeping up with the latest tools and trends is a necessity to reap quality insights from your data, improve proactive decision making, and ensure your team is operating as efficiently as possible. With innovative thinking setting the pace, change is the only constant in technology. Unfortunately, diving into new platforms and methodologies to keep ahead of the curve typically entails navigating waters of mystifying buzzwords and unfamiliar jargon.
Latest on your radar of must-watch tools might be a platform called Databricks, powered by Apache Spark and capable of abstracting complex cluster management to scale out your machine learning and data engineering workloads, with intelligent optimizations to dynamically reallocate workers given computational demands.
Sounds cool, right? We think so too. But what’s it all mean? What’s behind all the buzz about Databricks and “scaling out” anyways?
Scaling Out Versus Scaling Up
Imagine this- you have a task to complete, and you’d like to figure out what sort of workers can complete this task for you as quickly as possible. Say, you’d like to scour a massive stack of takeout menus and compile all of your options for restaurants with tacos to-go (a respectable endeavor). Currently, you only have one member working on your team, who flips through these menus fairly slowly. To speed this up, one option is to hire an expert menu reader, very experienced and very keen on identifying tacos, who can work at a much quicker pace. They demand a high premium for their services and consistently work at the same pace at the same hourly rate.
Another option is to onboard an entire team of average menu readers, who do not demand a high rate but work quickly through sheer volume. Imagine also that these workers are flexible, and they can be individually relieved during a slump in work when you’re collecting more takeout menus, unlike the expert who is kept on retainer.
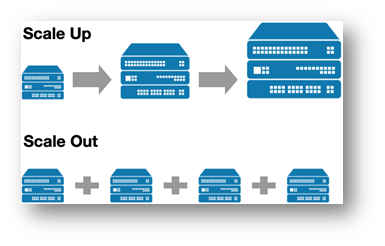
The move from a slow worker to an expert is an example of scaling up, where the solution to working with large amounts of data and speeding up workloads is beefing up your compute through something like spinning up a larger virtual machine or adding a GPU. The flexible team of workers is akin to scaling out, during which additional, nonpermanent compute resources (also called workers, per Spark lingo!), can spin up and down as part of a connected “cluster,” a team of connected workers.
The task is different, but the mechanics are the same – Databricks can automatically allocate the compute resources necessary for your job, providing a more cost effective, largely flexible alternative to scaling up. Fortunately, the complexities that make scaling out historically daunting are actually the strong suits of this platform; Databricks abstracts all of the complicated setup and overhead that can precede taking advantage of clusters. Databricks not only comes with the optimization capabilities to dynamically scale during the completion of a task, but also the ability to schedule jobs and automatically start and stop all necessary workers to perhaps load in your forecasting model and make predictions, or perform transformations and aggregations on your newest available data.
Given this wealth of features, gaining clarity around the buzz only positions Databricks further as an incredibly innovative tool, capable of simultaneously improving performance and cutting cost.
If you’d like to start letting compute clusters take care of your heavy lifting, begin taking advantage of cutting-edge scaling and scheduling tools, or simply automate your solution to takeout taco detection, Databricks and 3Cloud are here to help.



