
The intuitive Mapping Data Flows (MDF) in Microsoft’s Azure Data Factory (ADF) hit general availability in October. The easy-to-use Mapping Data Flows tool empowers users to quickly design ETL processes that transform data in the cloud, at scale.
Under the hood, Mapping Data Flows uses Spark-powered Databricks clusters. Spark is a cluster-computing framework used to process large amounts of data. Don’t know how to code in Spark? Don’t worry; while it’s helpful to know some of the internals of Spark when doing more advanced data flow optimizations, you don’t have to write any code to create your Mapping Data Flows. On execution, Azure Data Factory Mapping Data Flows are compiled to Spark code for you.
Mapping Data Flows is similar in look and feel to SQL Server Integration Services (SSIS). If you’re coming from an SSIS development background, Mapping Data Flows is a lot like the Data Flow tab. ADF Pipelines are a lot like the Control Flow tab. An ADF Pipeline allows you to orchestrate and manage dependencies for all the components involved in the data loading process. ADF Mapping Data Flows allow you to perform data row transformations as your data is being processed, from source to target.
Users can maintain Mapping Data Flows source control from right within the Azure Data Factory user interface. You can also integrate with GitHub and Azure DevOps Git repositories. Once you link your repository to your ADF project, you’re able to create and switch between branches from right within the ADF interface. This fosters easy collaboration among your data engineering team.
Side-by-Side View: MDF vs. SSIS
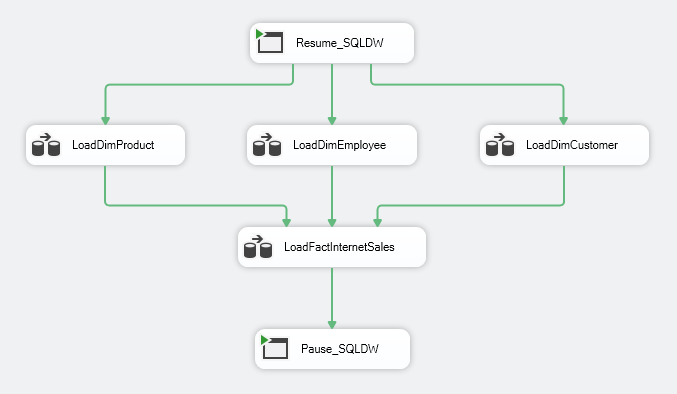
Below are side-by-side comparisons of ADF Mapping Data Flows and SQL Server Integration Services. The functionality is exactly the same between the two. First we’ll compare SSIS Control Flow to the ADF Pipeline. Our use case is a standard scenario – we’re loading a flat file from Blob storage into a table in Azure SQL Data Warehouse (now Azure Synapse Analytics). Walking through the SSIS Control Flow/ADF Pipeline:
- First, resume the Azure SQL DW instance. Here, the instance is paused during non-loading times, so we don’t incur additional costs.
- We then execute Mapping Data Flows to load the dimension tables.
- After all the dimension tables have loaded, we execute Mapping Data Flows to load our fact table.
- Lastly, once all the data has loaded, we pause our Azure SQL DW instance.
Example of the SSIS Control Flow tab for loading our data mart tables:
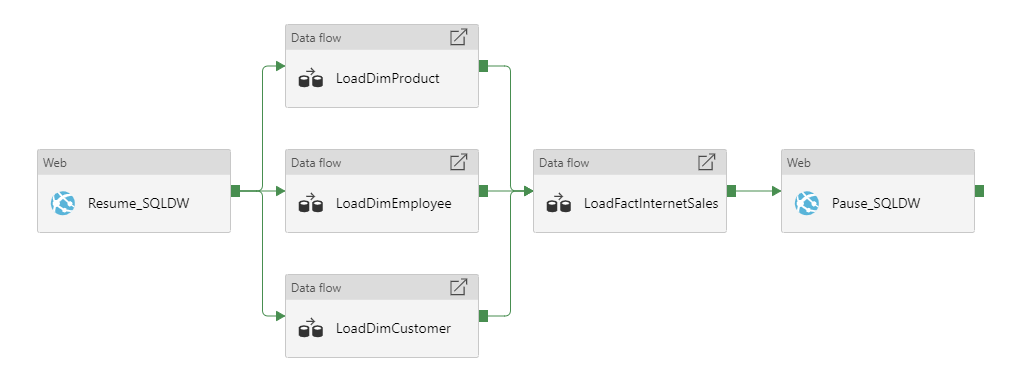
Example of the ADF Pipeline for loading our data mart tables:
Now let’s look at one of the Mapping Data Flows “LoadFactInternetSales”. Again, this is a very common scenario where we’re loading a flat file that contains our internet sales data. We do a simple transformation on the data and load the records into our data mart.
- First, we’ll read in a CSV file from Blob storage that contains internet sales data from Microsoft’s AdventureWorks sample database.
- Then we’ll do a transformation on the product code column, where we’ll cleanse and parse out the product code.
- After that, we’ll join the cleansed product code column to our dimension product code column to get the product surrogate key from our product dimension.
- Lastly, we’ll insert the records into our FactInternetSales table.
Example of SSIS Data Flow tab for loading the FactInternetSales table:
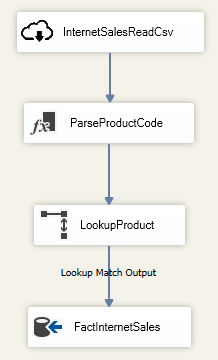
Example of ADF Mapping Data Flows for loading the FactInternetSales table:
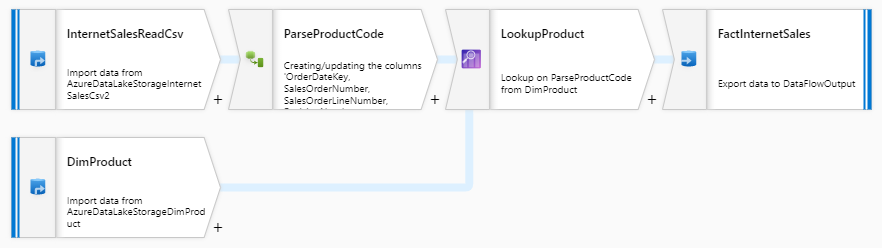
As you can see, both the SSIS Control Flow and Data Flow look very similar to the ADF Pipeline and Mapping Data Flows.
What Sets Mapping Data Flows Apart
While there are a lot of similarities between SSIS and ADF Mapping Data Flows, the latter brings exciting new features that don’t exists in SSIS.
Schema Drift – This creates the ability to ingest data when the source schema is unknown or changes. Do this by checking the Allow schema drift box at the source, then adding a derived column pattern afterwards to search for a specific column or perform any cleansing of columns as they process. If your source schema changed in SSIS, it would error out, creating a waterfall of changes that needed to be addressed.
Derived Column Patterns – This feature allows you to specify a pattern to be used on the data as it’s being processed. One such pattern could be something like “replace all NULL values with an empty string if the value is a string data type”. Previously, you would have had to define that logic for every single column, which is tedious and time consuming, especially when you’re dealing with many columns.
Upsert – You can perform an “upsert” operation in ADF Mapping Data Flows. An upsert will update records that already exist in the destination and insert records that are new. This simplifies the process and is very handy when loading your data mart tables.
Debug Mode – Allows you to view your data as you develop your pipeline. This is especially useful when working with some of the more complex transformations to ensure the results of those transformations meet your expectations. Turning on debug mode starts up a cluster that it uses for your ADF Mapping Data Flows. It takes a couple of minutes for the cluster to spin up, but once it’s running you can keep using that same cluster from data flow to data flow. An important thing to note is that when running in debug mode, the default row limit is set to 1000 for each source. That means that you are only getting a sample of the data. This can cause confusion when trying to troubleshoot an inner join when the sampling of the two sources happen to not have any of the same values for the join. Luckily, you can change the default row limit to match the size of your data if needed.
Should You Use It?
If you’re looking for a rich user interface that allows a drag-and-drop ETL experience for your modern data platform solution in Azure, then Mapping Data Flows is a great option. There isn’t much of a learning curve if you’re coming from an SSIS background. It’s a code-free experience, so you don’t need a heavy coding skill set to get started.



