
In part 3 of our “Better Together” blog series, I will recap my presentation from a series of BlueGranite Tech and Career Talks conducted in partnership with BDPA (formerly known as ‘Black Data Processing Associates’), in which I, along with my fellow Data Scientist Dr. Tom Weinandy, talked about “A Day in the Life of a Data Engineer and Data Scientist”. Since both of our backgrounds are as data scientists, I focused my section on how data engineering is not only intertwined with data science, but is in fact an essential prerequisite.

Data Engineering Overview
The key roles of data engineers are to build and maintain an organization’s data pipeline as well as clean and wrangle the data into usable sets for analytical purposes. Real world data is normally messy, unstructured, and derived from multiple sources without a clearing understanding of associations. A data engineers’ job is to take this web of data and weave it into a sustainable process that produces a data set that data scientists can not only work with, but that the company can understand. As the saying goes, garbage in equals garbage out; a statistical model can only perform as well as the input data it receives.
While some companies rely on data scientists to perform these essential steps, as the data and technology expands, the person building the algorithm should not be the same as the person building the data pipeline. Both pursuits require in-depth knowledge of specific technologies and domains that, while overlapping, require differing degrees of comprehension. Furthermore, a data scientist would design and clean data with the bias of data for data modeling purposes, even if the pipeline needs to be designed with multiple use cases as the goal.
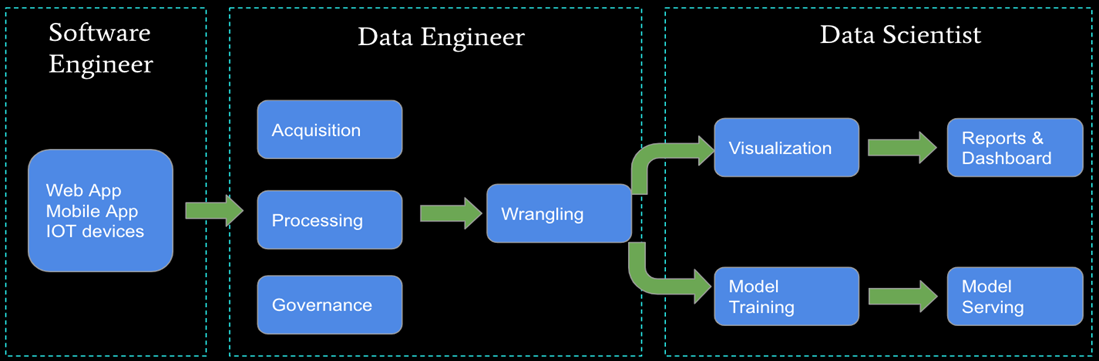
Types of Data
Adding further to the challenge of data engineering, real world data comes in a variety of formats. These formats can be classified into two main categories: Structured and Unstructured. Structured data refers to data saved in a fixed field or record. It is generally easier to work with this type of data. Unstructured data is essentially every other piece of data; it tends to be more complex and lacking a data model. The chart below highlights some of the key differences between structured and unstructured data.
| Structured | Unstructured |
| Clearly defined data types | No predefined data model |
| Stored in rows/columns | Stored in native format (i.e., audio file) |
| Usually quantitative | Qualitative |
| Ease of analysis | Requires preprocessing (i.e., data mining blogs/social media) |
A data engineer must be able to process both types of data, as well as discover meaningful relationships between the data.
Tools of the Trade
To accomplish these feats of data magic, data engineers rely on several tools on both the transformation and storage side. The most basic data engineering pipeline involves accessing data in its raw format, performing data wrangling/cleaning tasks, and then saving the cleaned data to a centralized location. Python, SQL, and Java are coding languages commonly used to perform all steps of this pipeline. Enabling Apache Spark with these coding languages allows for high performance with large-scale data. For a less code intensive solution, Azure Data Factory allows data engineers to construct pipelines with built in features or through making calls to code-based notebooks.
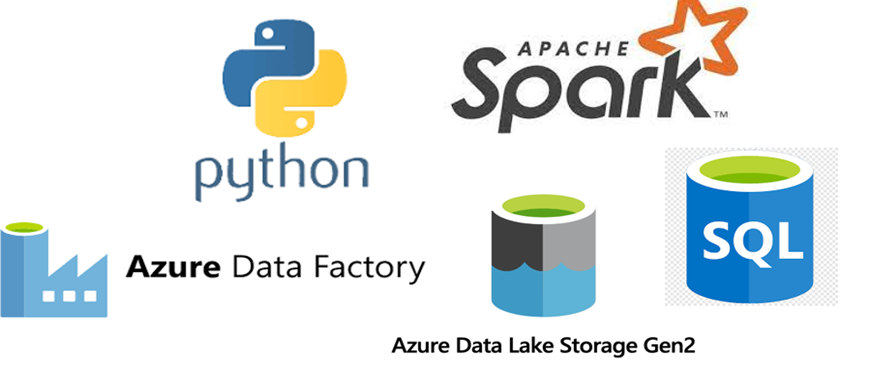
On the storage side, many options are also at a data engineer’s disposal. The challenge is selecting the correct format based not only on the type and amount of data, but on the stakeholder’s intended usage and budget. Common storage platforms include Azure Data Lake and SQL Database. Data can also be stored On-Prem or in a Cloud-Based solution.
In Summary
Overall, a data engineer’s role is complex and involves multiple factors. However, without data engineers, data scientists would struggle to optimally perform their role. To get a more in depth understanding of data engineering, as well as see real case study examples, watch the BDPA video recording below.
This final workshop that we presented will be split into two posts to allow coverage for “A Day in the Life of a Data Scientist”, presented by my colleague, Dr. Tom Weinandy.
Read our first two posts covering our partnership with BDPA here:
- Better Together Blog Series – BlueGranite and BDPA
- Better Together Blog Series – Principles of Data Visualization
We can help!
Discover a variety of resources to help you learn how you can leverage Modern Data Analytics. Please contact us directly to see how we can help you explore your about modern data analytics options.



