
Microsoft recently announced the general availability of its Compute Optimized Gen2 tier for Azure SQL Data Warehouse (Azure SQL DW). This new tier brings with it more compute, concurrency, and availability for the cloud data warehousing service.

The Azure Databricks team also recently released the Azure SQL Data Warehouse connector (SQL DW connector) for Apache Spark. This connector enables even deeper integration between Azure SQL DW and the unified Apache Spark platform. These improvements in the two Azure services make them even better together for modern big data and AI platforms in Azure.
Azure SQL DW Compute Optimized Gen2
The announcement of the Gen2 tier for Azure SQL DW came with three major highlights:
- More processing power: Gen2 offers as much as a 5X performance improvement over Gen1 by caching more frequently used data closer to the compute resources. This is done without sacrificing the separation of compute and storage, which is a key differentiator for Azure SQL DW allowing the service to be “paused” and “resumed” as needed.
- More concurrent users: Gen1 provides just over 30 concurrent connections to the database. This means that for organizations with many BI and reporting users, the number of active connections must be strictly monitored and mitigated. With Gen2, 128 concurrent users are supported. This 4X improvement takes a ton of pressure off administering active sessions.
- More availability: With the announcement of Gen2, Azure SQL DW is now available in 33 different Azure regions, making it the most widely available cloud data warehouse platform to date.
Azure SQL DW Connector for Apache Spark
The Azure SQL DW connector for Apache Spark allows services like Azure Databricks to interact much more effectively with Azure SQL. With this new connector, Azure Databricks can both query massive amounts of data from and load massive amounts of data to Azure SQL DW using PolyBase. After loading data, it can also fire off additional processing in Azure SQL DW directly from Azure Databricks. This functionality allows for end-to-end, secure, big data ETL processing scenarios using Apache Spark in Azure Databricks to load data into Azure SQL DW.
Better Together
With the recent updates to Azure SQL DW and Azure Databricks, these two services are even better together in a modern big data analytics and AI platform than they previously were. More seamless and efficient integration and the ability to operate at previously unavailable compute scales make for even more solid combined-service use cases. Below are just a few of the use cases for using Azure Databricks and Azure SQL DW together.
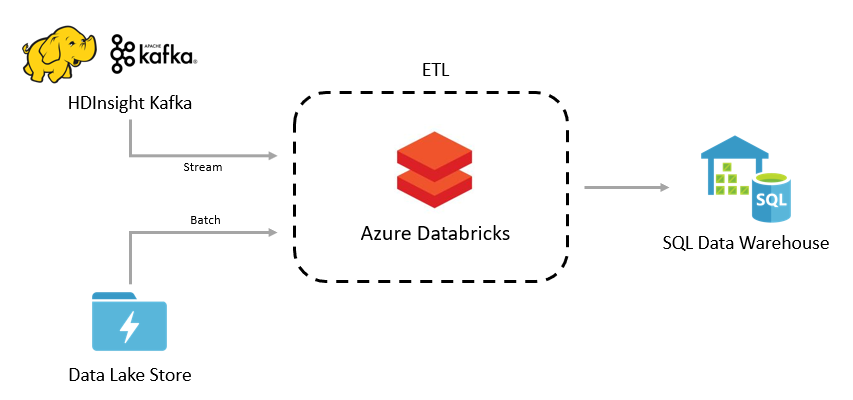
Batch or Streaming ETL
Use Azure Databricks for processing batch and streaming data before loading it into Azure SQL DW for further processing and analysis.
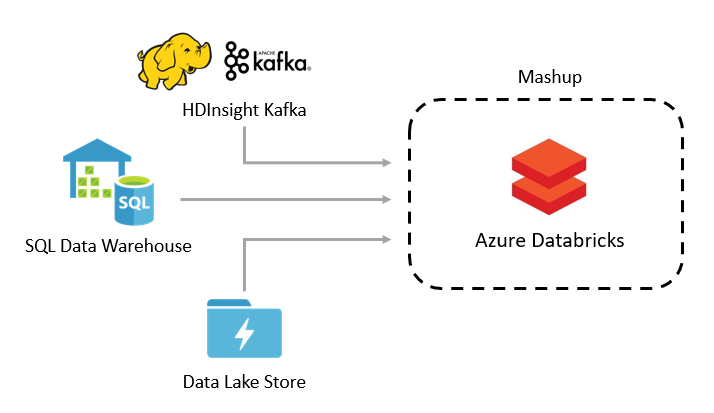
Reference Data Lookup
Use Azure Databricks to mashup data from Azure SQL DW with other data sources.
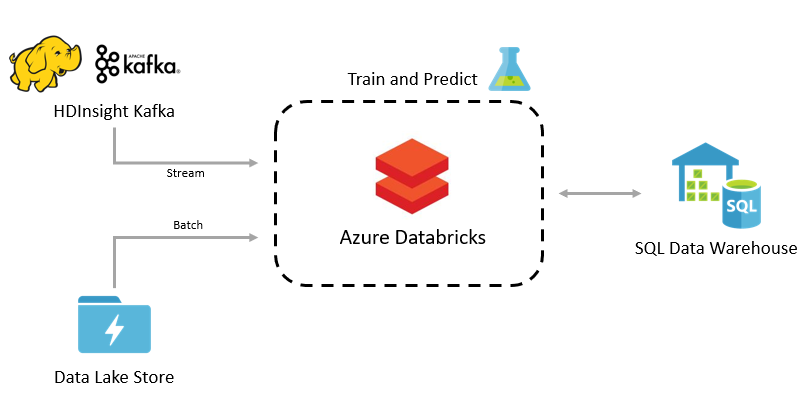
Machine Learning
Train machine learning models in Azure Databricks and send predictions into Azure SQL DW for further processing and analysis.
If you have any questions about the recent announcements for the Azure SQL DW Compute Optimized Gen2 tier, about Azure Databricks, or how these services can help you do more with your data, please reach out today.



