
Since the introduction of Azure Databricks in 2018, there has been a lot of excitement around the potential of this Unified Analytics Platform and how it can simplify the complexities of deploying cloud-based analytics solutions.
One of the primary benefits of Azure Databricks is its ability to integrate with many other data environments to pull data through an ETL or ELT process. Let’s examine each of the E, L, and T to learn how Azure Databricks can help ease us into a cloud solution.
Connecting to Source Data – (E)xtract
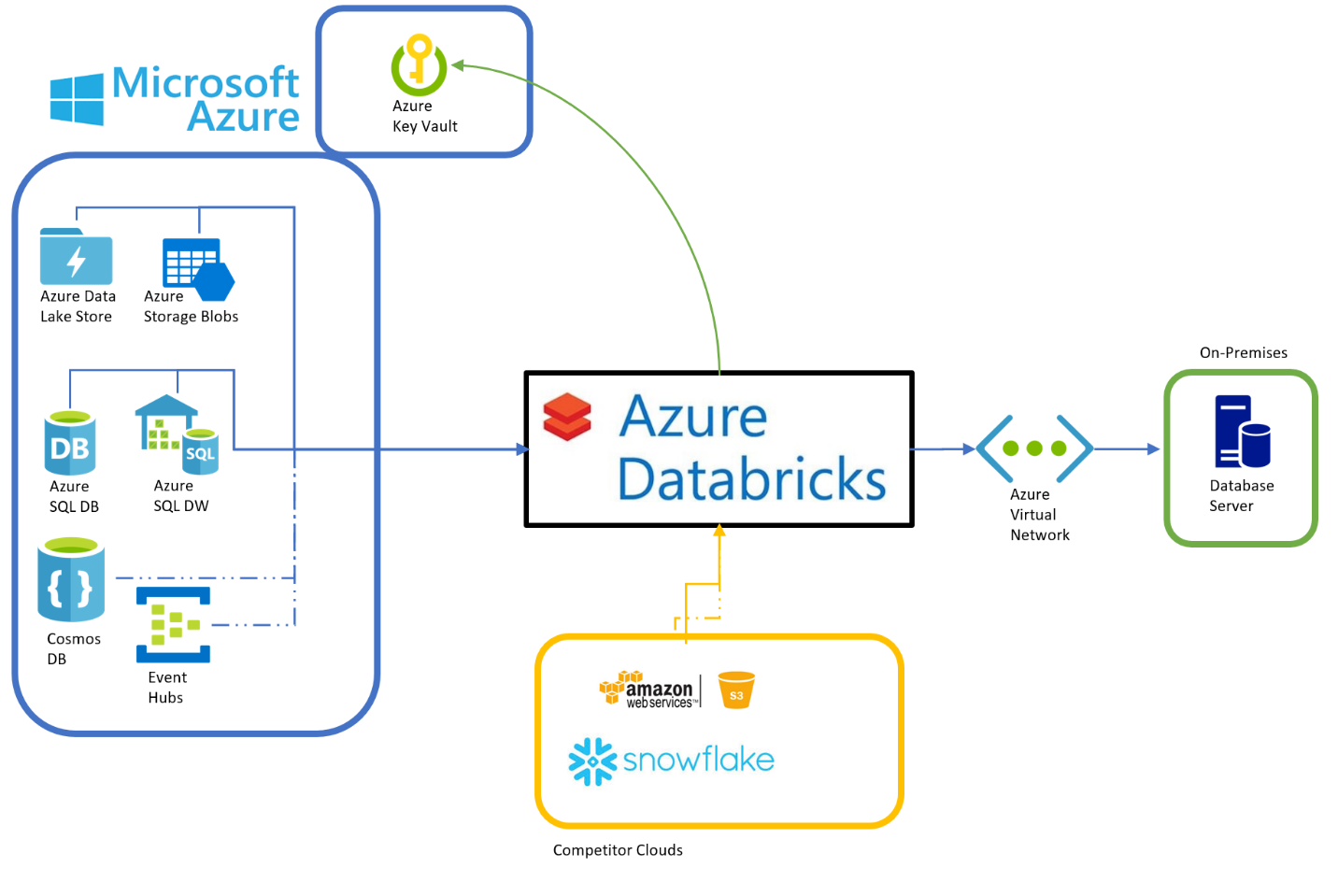
Azure Databricks, with Spark as its underlying processing engine, is a distributed-processing platform designed to connect to a distributed file system. When deployed on-premises, data is typically read from the Hadoop Distributed File System (HDFS). In the Azure cloud, there are several storage options that can be utilized.
Azure Databricks is equipped right out of the box to connect to Azure Blob Storage, Azure Data Lake Store Gen1, and Azure Data Lake Store Gen2. As a matter of fact, an Azure Storage account is created for you automatically when you create an Azure Databricks workspace, and is mapped to the root of dfbs://
Additional Azure Storage and/or Data Lake accounts can be connected using mount points, or by directly accessing them using wasb://, adls://, or abfs:// syntax
In addition to connecting to cloud storage provided in Azure, Azure Databricks can also extract data from competitive cloud storage environments, such as Amazon S3 buckets.
If the solution is using an Azure-based database provider, Azure Databricks includes connectivity options for Azure SQL Database (DB) using the Java Database Connectivity (JDBC) driver, Azure SQL Data Warehouse (again using JDBC) and Azure Cosmos DB using a specially designed adapter. In the competitor landscape, connections to Snowflake, Cassandra, MongoDB, Neo4j, and more are possible using libraries provided by Databricks.
If your data is stored on-premises in a database, you can also connect directly to it using Azure Databricks configured with an Azure Virtual Network (VNet). This is a great option, as there is no need to first copy your on-premises database data to a storage platform.
Not all data is sitting still. Ingesting data in motion is also supported with direct connections to Azure Event Hubs and Azure Event Hubs for Apache Kafka using libraries provided by Microsoft and Databricks. External or on-premises Kafka connections are also supported, and may require additional Azure VNet configuration.
One important consideration when connected to source systems of data is security of authentication credentials. Azure Databricks has built-in connectivity with Azure Key Vault when using a Premium workspace.
Data Engineering – (T)ransform
Azure Databricks’ key feature is its ability to munge data at scale. Several application programming interfaces (APIs) are available with Spark to help data engineers and data scientists transform data from its raw format into a more meaningful shape for analysis.
DataFrames is the primary API used in Azure Databricks. A DataFrame is an abstraction of source data resembling a table format. The DataFrames API is available in Scala, Python, R, or SQL – meaning a developer can choose the language that best suits their experience.
Writing DataFrame transformations is similar to writing SQL statements. Common operations that most data engineers need to complete include:
- Column projection
- Data cleansing
- Joining/merging
- Aggregation/calculations
Even without deep knowledge of Spark, the DataFrames API is easy to understand. Most operations are defined using a syntax that resembles declarative SQL statements.

For streaming data, the DataFrames API has been extended with structured streaming capabilities that allow nearly identical code to be used for data at rest and data in motion. This means that adding real-time capabilities to an existing Azure Databricks application can be as easy as adding a few lines of configuration code. Common functions, such as data cleansing and aggregation, are written with equivalent code in a streaming DataFrame, as in a static one. This is a huge benefit that means that Azure Databricks developers do not have to relearn a new API to convert an application from a batch-load system to a real-time solution.

When data doesn’t fit the mold of traditional structured format (e.g., rows and columns), such as parent-child hierarchies, social network relationships, or clickstream analysis, a graph processing API has also been bolted onto the DataFrames API. GraphFrames, as the graph API is known, includes several key graph processing algorithms that can be used in a very similar manner to working with a traditional DataFrame.
To setup a new graph for processing, begin with two DataFrames: one defining the vertices (objects or points along a graph) and a second defining the edges (relationship between two vertices). The two DataFrames are combined into a GraphFrame which can then be processed using common graph algorithms to calculate results including page rank, mean distance, number of stops between two points, parent/child, and many more.
Here’s an example of calculating a page rank in just four lines of code!
![]()
Using a common set of APIs offers many benefits, not the least of which is performance optimization. Since advanced operations are based on the DataFrames API, those operations can take advantage of all of the optimizations included with Spark 2.0’s Catalyst engine. There are benefits for developers and engineers, as well. Having a common set of APIs reduces the amount of training a developer needs to become proficient. It also reduces the amount of development time to build an enterprise-ready solution versus implementing a solution across multiple platforms in a traditional n-tier application.
Providing Data to Wider Audience – (L)oad
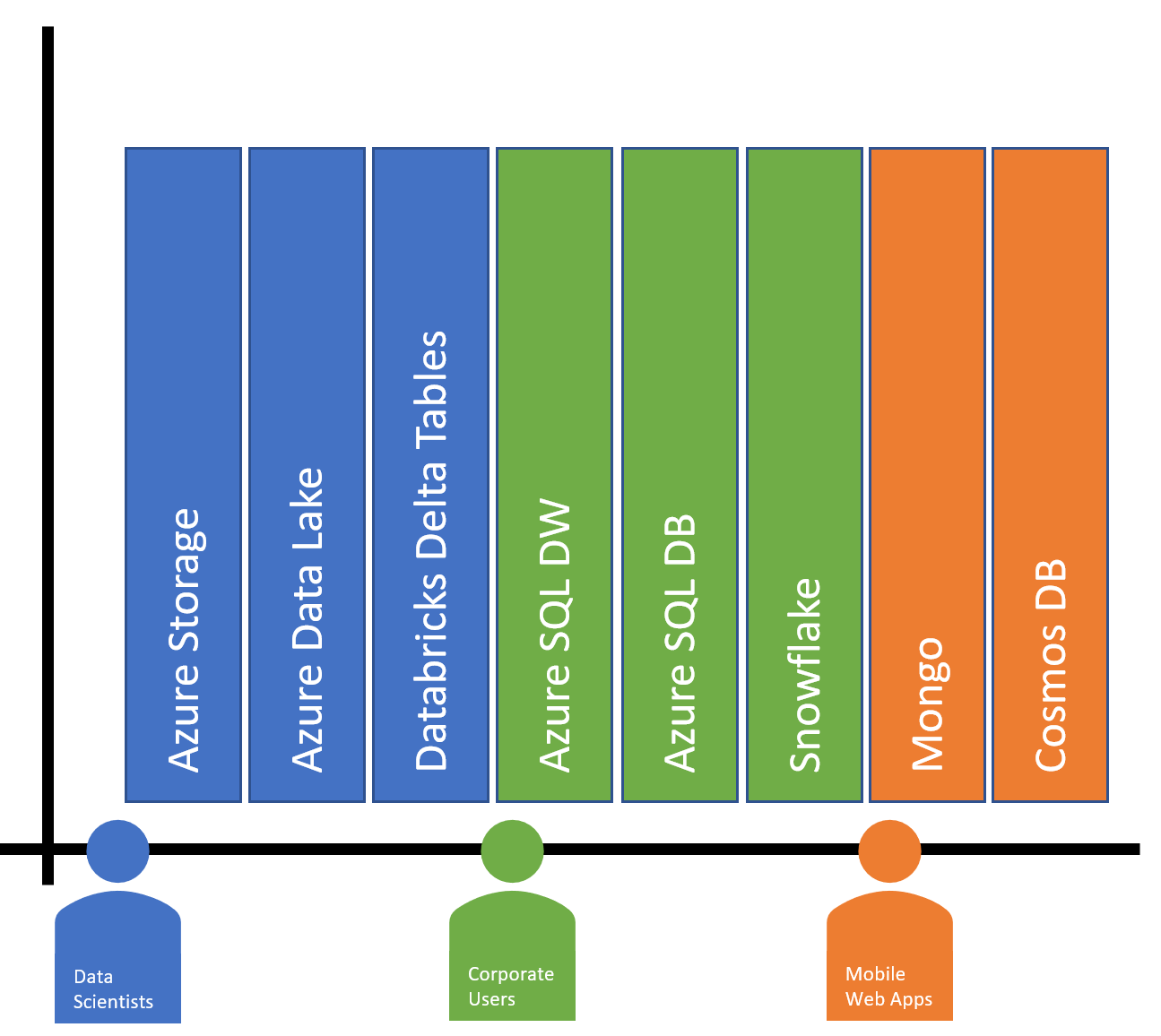
Once raw data has been transformed, the final step is to make it available to data scientists, business analysts, and other users for consumption. As above, there are many options available to provide data for later consumption.
First and foremost, Azure Databricks supports analytic sandboxes by providing a database-like environment of tables and views that describe the Data Lake. Data scientists and analysts can query data stored in the Data Lake using common SQL code. A premium Azure Databricks workspace also provides JDBC/ODBC (Open Database Connectivity) access, so many enterprise BI tools, like Microsoft Power BI, can directly connect to retrieve data for ad-hoc dashboards and reports.
Tables in Azure Databricks can be based on data in many formats; CSV, JSON, Parquet – but an attractive modern option is to use Databricks Delta. Delta in as extension of Parquet that is unique to Databricks. It provides a layer of data management and performance optimizations most often seen in dedicated Data Warehousing platforms like Azure SQL Data Warehouse (DW).
When structured analytics for a broader corporate user base is the highest priority, Azure Databricks can efficiently load the common Azure database platforms Azure SQL DW and Azure SQL Database (DB). These platforms are used to build dimensional models for analytics that are used in BI solutions. Relational database management systems (RDBMS) provide a structured environment to store data, which is a common need for end users of BI systems. These platforms are also designed from the ground up for interactive queries, so the reports developed will be highly responsive.
If you are hosting a data warehouse in a competitive environment, such as Snowflake on Amazon Web Services (AWS), Azure Databricks can also efficiently load transformed data in that environment. Many libraries are available in Databricks that allow data to be loaded to any cloud.
Often, the results of AI are used in operational applications. Azure Databricks has a unique ability to use the Azure backbone to load model results into Cosmos DB – a polyglot database used by many web and mobile applications. Storing results of advanced models that predict product recommendations, form suggestions, or security check results couldn’t be easier with Azure Databricks.
No matter who the data audience is, Azure Databricks provides a method to store, update, and manage data so that it’s always available at the right time and in the right format.
Conclusion
Azure Databricks is a unique offering in that it combines the ability to connect to many different data sources, uses a variety of commonly designed APIs, and loads data from any data store, in an easy-to-manage platform. Since it’s based on a highly scalable distributed platform, Azure Databricks has the capability to be used in scenarios that involve petabytes of data – but is also designed to work well with smaller, more manageable terabyte-level solutions.
The developer API is unified in that most of the common operations are based on DataFrames – so whether you’re working with data at rest, data in motion, structured data, unstructured data, graph processing, or traditional “rectangular” processing; there will only be one base API to learn – all operations are based on that API. Many different platforms do not need to be integrated to build an enterprise-level analytics and AI solution.
Finally, Azure Databricks supports loading transformed and cleansed data to many different data sources so users can consume data in the most appropriate way possible. Be it analytic sandboxes for data scientists, corporate BI portals, or web and mobile applications – cloud scale analytics is now in reach for your entire user base.
If your organization wants to explore a secure workspace where data scientists, engineers, and analysts collaborate, contact us today. 3Cloud’s experts offer an in-depth, 1- to 2-week Azure Databricks proof of concept, giving groups a chance to dive in to the unified analytics platform’s vast potential
At 3Cloud, we know there are lots of options. If Azure Databricks doesn’t seem like the right fit for your data management solution, perhaps you might like to review Azure Data Factory. Data Factory is an easy-to-use, GUI-based, data engineering tool that allows complex data pipelines and transformations to be built to move data between on-premises and cloud locations. It even uses Azure Databricks behind the scenes to perform its most complex tasks.



