
The big data and AI world can be a complex one for companies to navigate alone. This has led to the perception of a high entry barrier among many organizations. Some of the early comments and questions we hear from companies we partner with include:
- Wow, there’s a lot of tools and services out there! Which one do I need? Do I need more than one?
- Do I currently have the necessary skills in my organization?
- Do I have the money to invest in a new solution, its infrastructure, and the new hires or training it will require?
- With all this configuration, administration, training and hiring, etc., how long will it take me to realize any value from such a platform?
Often, individual big data tools and services satisfy very specific use cases. This means that if a solution requires streaming, batch processing, and machine learning, companies must invest in multiple tools and services for each of those individual functions. An example of this can be seen in the Azure ecosystem where clients might string together multiple services like Azure Data Lake Analytics for batch processing, Azure Stream Analytics for stream processing, and Azure Machine Learning for machine learning and data science. Each of those services includes, and caters to, its own interfaces, languages and syntaxes, and users. This means that companies will likely need to invest to hire or train employees in unfamiliar, highly specialized skillsets.
With a flood of tools and methodologies, the machine learning and data science space carries similar complexities. We find many companies asking questions like: “Do I use R or Python?” “What framework do I invest in for deep learning?” and “Will it even still be relevant in 6 months?”

Azure Databricks simplifies the big data and AI conversation and removes many of the barriers to entry. The service provides a platform that unifies many of the disparate use cases in the big data space, supports many of the skillsets and languages that most clients already have in house, and is super easy and fast to administer – meaning a quicker time to value. Let’s look more closely at why many of our clients are realizing major value in Azure Databricks.
Single, Unified Platform
First, Azure Databricks brings together most of the common big data use cases under a single platform. This means that if a solution requires the use of scheduled batch processing, near-real-time stream processing, interactive querying and data analysis, or just about any other common big data use case, we don’t have to string together several disparate services. The same goes for machine learning and data science. Azure Databricks, built on Apache Spark, includes many of its own machine learning libraries but also supports easy interaction with many other popular machine learning frameworks like XGBoost, scikit-learn, TensorFlow, Keras, and Horovod.
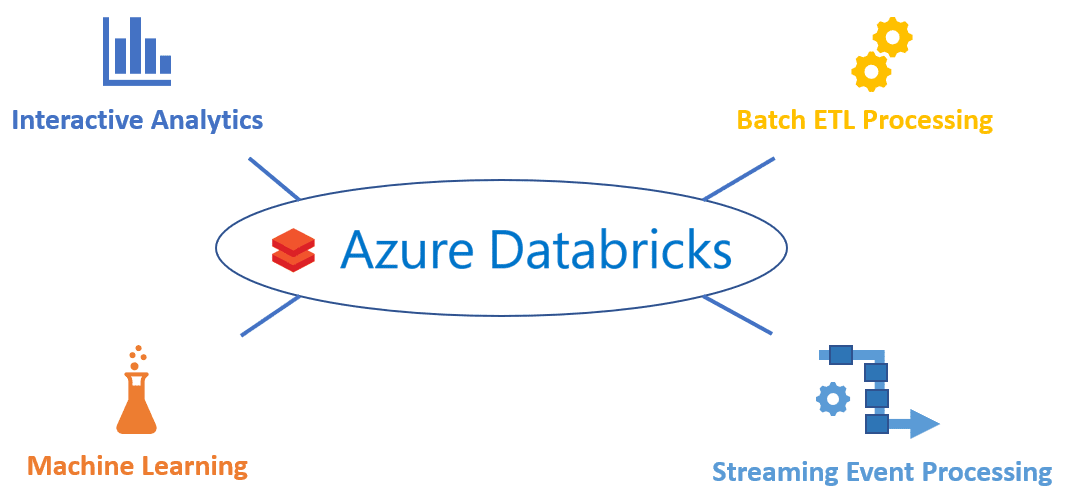
Unifying all these different use cases also means uniting all data users under a single platform. As discussed in a recent blog, Azure Databricks brings together data engineers, data scientists, and business analysts into a single collaborative workspace. This again eliminates the need to try to make multiple disparate tools and services work together to satisfy different users.
Familiar Skillset and Tools
Our clients also appreciate the familiar skillsets and tooling the platform provides. Azure Databricks allows for querying, analyzing, and processing data in SQL, Python, R, and Scala.
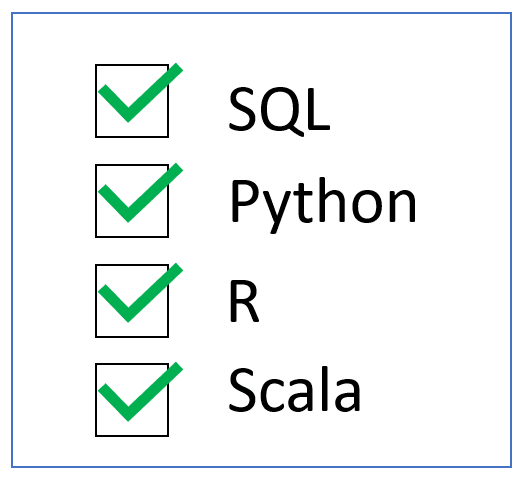
Organizations can begin working and developing in Apache Spark on Azure Databricks with a very small learning curve. In many cases, that means existing teams can transfer their current skills and knowledge straight into Azure Databricks, and expensive new hires or extensive training is unnecessary.
Among the users who will quickly acclimate to Databricks’ environment are:
- ETL developers and business analysts who are already using SQL in their day-to-day work
- data scientists that are already using R or Python for data science and machine learning
- and even application developers who are familiar with Python or Java
Easy and Fast Administration
Finally, clients find that administering Azure Databricks is easy. As soon as the service is turned on, it is connected to a client’s Azure Active Directory. From there, adding users, creating clusters, and managing the workspace is intuitive, and can be performed through a very simple UI. Almost everything an organization would typically need to configure can be done through this UI, but there is also a REST API and CLI that can be used for more advanced configuration and automation. These are all functions that a typical systems admin is already comfortable doing. This simple experience typically leads to much faster time to value, as companies can spend less time laying the pipes and configuring the system, and more time working with their data.
So many of our clients are discovering Azure Databricks’ appeal – it’s proving to be a service that allows us at BlueGranite to simplify the message around big data and AI development, and it is removing many of the questions and concerns that clients previously perceived in those spaces.
If you are interested in seeing for yourself how Azure Databricks can simplify big data and AI in your organization, please contact us. Whether you’re looking for more information, or are interested in an Azure Databricks proof of concept.



