Data mining is a term that is widely used with varying meanings and purposes. For the scope of this document, data mining can be defined as the process of analyzing large quantities of data through automatic or semi-automatic tasks to extract previously unknown interesting patterns. Over the years, storage has grown at a faster rate than computing power. As a result, companies have stored enormous amounts of data and have become “data-rich and knowledge poor”. The main purpose of data mining is to increase the value of these large datasets by extracting knowledge from them and making the data useful to the business.
In general, there are two types of data mining – predictive and descriptive. Predictive data mining will use variables or fields from a dataset to predict unknown or future values. The goal is to produce a model from a defined dataset that is used to perform classification, estimation, and other data mining tasks. On the other hand, descriptive data mining will focus on finding patterns that describe the data and can be interpreted by data analysts or business users. The goal is to gain understanding of the data by uncovering new relationships, patterns, and important information regarding the dataset.
Data mining is meant to replace the tedious and antiquated methods of formulating a hypothesis and then exploring the data through numerous queries and reports with hopes of finding a solution to the business question. Data mining is considered a collaborative process between users (humans) and computers where the users determine the problem and goals, while the data mining system will explore and search for possible patterns and answers.
Business Applications of Data Mining
Data mining can be valuable in virtually any industry and business scenario. The following are just a few examples of how data mining can improve decision making and give businesses a better return on investment with their Business Intelligence (BI) projects:
Recommendation Generation:
- What products/services should a company offer to its customers?
- E-Commerce Websites – analyze purchasing behaviors of customer population and recommend products based on items in a customer’s cart
Anomaly Detection:
- Analyze items that don’t fit a certain pattern – determining what is “good” data and what is “bad” data
- Credit card and insurance companies use this method to detect fraud
Churn Analysis:
- Which customers are most likely to switch to a competitor?
- Telecommunications, banking, and insurance companies identify which customers are most likely to leave and why
- Based on findings, companies can improve relationships and offer those customers discounts or loyalty incentives
Risk Management:
- Determine the risk of a loan or mortgage based on the customer profile and amount they are asking
- Companies can make decisions based on cost and risk of the loan by using historical customer data
Customer Segmentation:
- How well do companies know their customers?
- Determines behavioral and descriptive profiles for their customers in order to target marketing campaigns
Forecasting:
- Estimate how much sales and/or inventory for each week, month, and quarter of a specific year
- Data mining can perform time series analysis
Data Mining Tasks
Determining the correct task and algorithm to apply to your dataset is a crucial step to achieving an accurate and useful data mining model. In some cases, it will be quite obvious which task will be the most accurate to use depending on the nature of your data. More often than not, you will need to explore and combine multiple tasks before arriving at a single solution. The following section describes the seven basic data mining tasks (the names can vary depending on the technology or application you are using):
Classification: Can be used to identify loan applicants as low, medium, or high credit risks based on attributes such as income, credit score, employment history, home ownership, and amount of debt. In this case the target would be credit score, and the other attributes would be the predictors.
Clustering: By using attributes such as Income and Age, three clusters could be created (could be more than 3 depending on data) – 1. Younger population with low income, 2. Middle Age with higher income, and 3. Older Customers with lower income.
Association: (also called Market Basket Analysis) Perhaps most famously, Amazon uses these types of analyses to suggest additional items you may be interested in purchasing, based upon other items frequently bought together.
Regression: Can be used to predict a value of a house based on location, number of rooms, land size, and crime rates
Forecasting: Based on the sales from last year by month, how many cases of soda will the northeast store sell in January? The output would be the estimated number of cases of soda for January.
Sequence Analysis: Can be used to analyze the sequence of web clicks on a website. The results are probabilities of the next click in the sequence, i.e. if a user clicks ‘News’, there is a 20% chance the next click will be ‘Sports’ and a 30% chance it will be ‘Weather’.
Deviation Analysis: Used to find the rare cases that do not match their behavior to the ‘norm’; most commonly used in fraud detection – finds the transactions that don’t match the spending habits of the customer.
Data Mining Project Life Cycle
Until recent years, data mining was just a buzz word and met with heavy resistance within the business community. Most viewed it as being “cryptic, complex, and somewhat intimidating”, and many of the IT teams often lack the knowledge to begin with a comprehensive plan. For these reasons, business leaders often consider data mining to be a risky research activity and blamed failed projects on the overall technology performance. Fortunately, these views are often a misconception. While the science and mathematics behind data mining tasks are rather complex, the software available provides a user-friendly method to build accurate and intuitive models without advanced knowledge or training in the field.
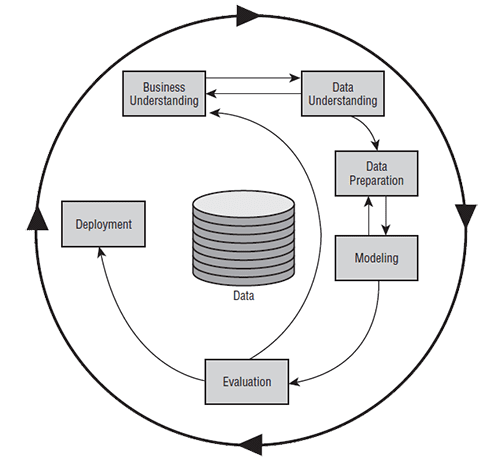
Most of the projects fail because the business implements an incorrect approach. They start by adopting and purchasing data mining software, utilizing available data from a data mart or warehouse, and expect the model’s results to be accurate, make sense, and ultimately be adopted. This approach fails because there are usually predetermined notions about the model’s outcome and answers the wrong questions, the business lacks the understanding of the underlying data, and the business fails to evaluate the success (and ROI) of the project. The following sections will introduce the data mining project life cycle and the industry standard process called CRISP-DM (Cross-Industry Standard Process for Data Mining).
The goal of CRISP-DM is to create a data mining standard process that is reliable and repeatable by individuals with little data mining background. CRISP-DM is a non-proprietary, tool neutral process that is designed to aid in project planning, management, and implementation. CRISP-DM is a non-rigid process with six phases that requires movement forward and backward between the different stages in order to achieve project success.
Learn more about advanced analytics today.