
Modern times are proving again and again that for companies to both profit and stay afloat, we must be extremely adaptable to changes in the supply chain as well as with general logistics of business operations. Each year, countries push closer to fully digital footprints and Data and Analytics (or D&A) solutions are often playing catch-up instead of acting as the driver for the change. This industry pattern became extremely visible with the recent COVID-19 pandemic, but it had existed before in a lesser fashion and has continued to surface at an increased rate after the initial reactions from the pandemic settled. Companies who could not embrace solution overhauls during the pandemic are now looking for ways to modernize their solutions to avoid any future issues that follow from similar world events, and this blog will offer an innovative and cutting-edge approach to addressing this via the power of Azure services and metadata principles.
This blog dives into detail on a solution framework proposed as a modern data platform that should be considered in conversation as an efficient, scalable, and modular approach to handling data and analytics in the cloud. Built on proven techniques and concepts outlined in the Data Warehousing Toolkit by Ralph Kimball to model data, combined with best-in-class infrastructure and platform services provided by Azure to enable scalability and high-value monitoring, this solution consolidates best practice techniques and powerful infrastructure required for an all-inclusive and future-proof Data Platform.
This blog will achieve detail by honing in on a solution proposal for an imaginary manufacturing company’s business problem. Arbitrarily named EZ-Fence, this company has a desire for a more efficient and reliable approach to their data estate than what they currently have. More detailed information as to why EZ-Fence is looking for an upgrade will be explained below. After understanding that – we will outline which Azure technologies can be leveraged for the various pieces that make up our solution proposal while also explaining how these technologies can be driven by metadata to deliver consistently reliable results in an efficient manner. By the end, readers should have a general understanding of problems that this framework aims to solve via understanding a typical use case and will also be able to drive conversation about how to implement the solution within the reader’s own team and environment. Let’s begin exploring the imaginary case study to set our stage.
Case Study
EZ-Fence is a fencing company who upon founding decided to store their data in SAP ERP systems. Over time, EZ-Fence has purchased and migrated processes with various other businesses. Those businesses each had their own business practices, forcing EZ-Fence to resort to 3rd party applications to assist with data integration across disparate sources. Now, EZ-Fence finds themselves working with Data in Excel, SAP, and SQL Server. Although EZ-Fence is actively trying to migrate all of the Data from SQL Server into SAP, the migration has proven to be sluggish, as different departments leveraged different frameworks and data models to represent their information. On top of this, the SQL Server and Excel data had no considerations for SAP systems in mind, which has added extreme amounts of overhead in figuring out the best way to handle the consolidation of the company’s incremental data loading needs. This data platform roadmap has led to many employees voicing concerns about the amount of time it takes to gather data from the various sources to create reports and views, as well as the ability to trust the quality of the data being collected. Employees have stated how difficult it is to understand each department’s data definitions alongside their own, and often employees find themselves waiting for email responses and queries to execute in this slow environment.
EZ-Fence plans to continue to grow and wants to keep delays on growth to a minimum, so any solutions must be simple in implementation but also trustworthy and something that new developers could understand quickly. With this growth expectation, the business recognizes that scalability of a new platform should sit at the forefront of decision making, and the new platform must consider that new employees and existing ones need to be upskilled.
Case Study Takeaways
From the case study, for this blog, we will highlight the following takeaways:
- Multiple Data Sources make report authoring and view creation a headache
- Queries execute slowly in moments of high traffic
- Onboarding team members to the platform is difficult
- Teaching people how to add to tables and extend the framework capabilities is confusing
- Multiple Data Sources have led to distrust in Data Quality
- SAP has historically lacked support for these types of solution approaches
EZ-Fence is the victim of what seems to be the common pain points for companies who see a better future for their data platform. Too many unique sources, difficult knowledge transferring, burdensome ETL software, lack of trust, and low efficiency. These general issues are the motivation for this blog’s Metadata Lakehouse Framework approach. Let’s begin understanding more specifically how this type of framework works and how it will consistently succeed at solving the aforementioned problems.
The Framework
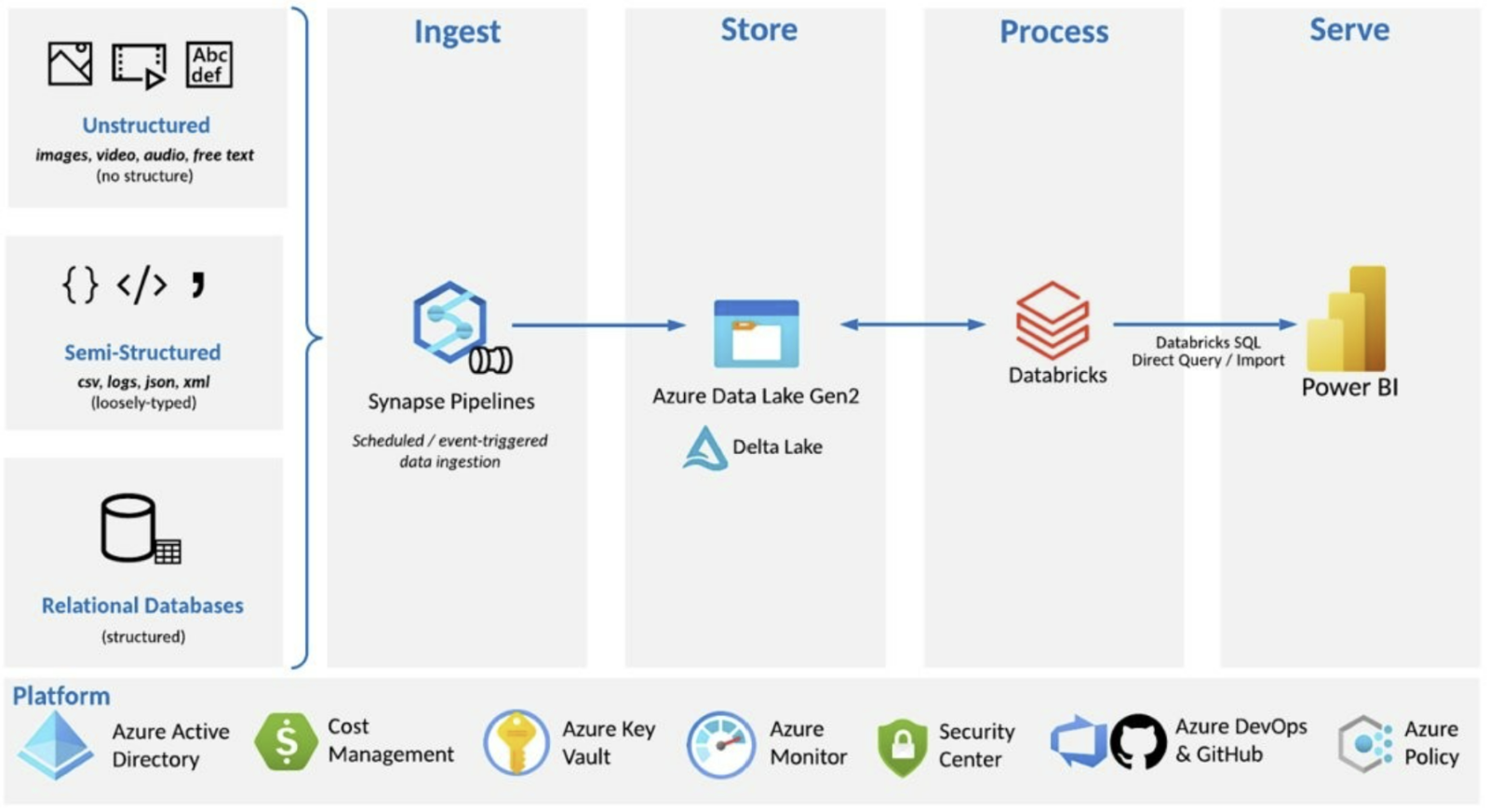
Figure 1: Framework Overview
Figure 1 captures the bare minimum Azure tools and where they sit within the Metadata Lakehouse infrastructure. The framework begins with the ingest process, where it leverages the power of hundreds of premade data source connectors in Azure Synapse to make establishing a pipeline between data sources and storage (in our case, a data lake) simple. Azure Data Factory and Synapse offer identical data pipeline experiences, but this framework chooses Synapse specifically because of its unique services for handling specific analytical workloads in the future. These connectors enable us to quickly ingest and store unstructured, semi-structured, and structured data sources without the need to establish messaging protocols or spend time understanding how it is formatted or existing in that source system. For this example, we will make use of and talk specifically on the new SAP CDC connector recently made available in Azure Synapse Pipelines which simplifies the process of incremental data ingestion from SAP sources, even more so when combined with tool advantages described later. So, Azure Synapse will pull in our data, it does this is via pipeline copy activities, and once those copy activities complete, our store phase begins.
The Store phase coming next signals that we are following an ELT pattern as opposed to the ETL approach. We “sink” our synapse pipeline copy activity data into a landing zone which is Azure Data Lake Storage (ADLS). This allows us to have all our various sources consolidated into one area without any compute occurring on data structures during transfer. This beats EZ-Fence’s original approach of using third party tools to both ingest and transform data over the wire to have it in a storable format with all other source system data. Explained in more detail later, Databricks Delta Lake will also be automatically combined with the ADLS implementation behind the scenes, and with that comes another set of enhancements. Faster data exploration, faster query results, and more trust can be put into this approach as we create a single source of truth with our Data Lake. Now that our data is consolidated, we can understand more about how Databricks will power our compute phases while simultaneously being tightly integrated with the framework’s serve phase.
Databricks provides a platform for unmatched capabilities in data processing and analytics. This power is achieved through Azure Databricks Delta Live Tables (DLT) as the compute engine of this lakehouse solution. DLT is a declarative framework that allows us to focus on defining our tables, and DLT handles the loading, dependency order, and optimization. Databricks Auto Loader is used to incrementally load bronze tables from files in the landing zone. With the SAP CDC connector and Databricks Auto Loader, we get incremental loading from the source system to the lakehouse, without having to track watermarks. This is a substantial step up for our fake company EZ-Fence, as without this connector, they became used to injecting watermarks into their data and manually developing scripts to update those data points as changes are detected. Then since DLT uses Spark Structured Streaming under the hood, we can move data incrementally to silver and gold tables as well. Once our Delta Lake tables are loaded, Databricks SQL is available for data exploration and high performance querying with the Photon query engine, which nearly doubles the querying speed of the next comparable query engine. Now we can see the elegance of the lakehouse architecture. All the data processing and analytics can be provided by the same platform, while all the ingestion and storage processes can exist in their own platforms. Finally, there is often a desire to serve data using a dedicated BI tool, so let’s talk finally about how this framework approaches the serve phase.
Databricks leverages a tool it calls partner connect, where all the data in the lakehouse can be shared securely and directly with partners from within the Databricks UI at the click of a button. One of these partners is PowerBI (PBI), where we can leverage exports of our data to PBI for persistent querying, or we can leverage direct query capabilities, where PBI will query our Delta Lake tables without taking time to import to PBI itself. Direct Query is typically reserved for scenarios where the data is too large or updated too frequently for import into PBI, and both options provide impressive capabilities.
Now that we have a general overview of the technology utilized in this framework, we can now explain how our metadata mindset will cooperate with each piece.
MetaData Driven Process Control
So far, we’ve covered the ingest, store, compute, and serve technologies, but have not discussed how metadata supports each stage. Our metadata approach aims to simplify the ingestion and compute phases to support a more reliable and efficient pipeline. The simplification starts by keeping metadata in a consolidated location to control each phase of our pipeline. From a couple tables that host only a handful of easy-to-understand fields we can control everything Synapse does, how data looks in the datalake, and how the bronze and silver layer of a dimensional model are created by databricks. It’s important to understand conceptually that, for this framework, while the bulk of work done in Azure is generally done via GUI’s, there are standardized JSON templates constantly being generated in the background to power these services. Understanding that these JSON templates are the main driver then allows us to think of ways we can recreate a template that synapse can use that is built from Metadata. Then we can identify the repeatable aspects of the template and just inject the unique, dynamic, use-case specific information into it that a specific environment requires. This blog provides a mockup of this type of database later on, but for now we are going to tie EZ-fence back in to conversation to understand specifically how synapse and the SAP source system can be leveraged.
We noted that EZ-Fence was leveraging an SAP ERP System, a SQL Server ERP System, and some flat file sources. The copy activities can talk to each of these services directly, but for the sake of this blog, we will describe the metadata approach specifically for the SAP ERP System. The Azure Synapse data source connector for SAP was recently released, and with that came a modern way to extract from SAP while quickly enabling complete history ingestion incrementally without the need for cumbersome watermarking. Combined with functionality from the Databricks Auto Loader that will be explained further along in the reading, this connector optimizes an incremental loading strategy with half the steps that we would normally have to do to get the increased efficiency and insight. Synapse combined with the proposed metadata structure abstracts much of the complexity inherent with Change Data Capture (CDC) – the process of ingesting strictly new and changed data – and with implementing reusable data pipelines. It is important to note though that this connector is not required to achieve all that is outlined in the blog, but rather the connector is highlighted as it is a huge step forward in simplifying SAP specific migrations, as those who chose SAP to start had specific needs they wanted to meet. Let us start looking in more detail at how Synapse operates to better visualize how metadata can affect it.
Figure 2 below is a picture of an SAP copy data activity living in the Azure Synapse GUI. We can see many parameterized fields that can have their entries manipulated.

Figure 2: Synapse Parameterization
As mentioned, while this GUI is what employees are treated to while working in Synapse, we do have access to the templated code powering this GUI. A snippet of what this GUI looks like in its JSON form is provided below:

Figure 3: Synapse JSON Backend
This is where a metadata approach can start to exist. By realizing that we can grab the JSON script that is the ultimate driver for any job execution in Synapse, we just need to find a way to manipulate the script remotely and trigger the pipeline to power consistent and easily extendable data ingestion. At that point, it is a matter of utilizing a foreach to iterate though all the metadata we create, thus enabling synapse to ingest each relevant table we identify in a source.

Figure 4: Synapse For Each Activity
Now that we understand a bit more of how Synapse plays into the framework, we should talk about what will be helping orchestrate Synapse to know what metadata we need to gather. As discussed in the technology section, Databricks can talk directly with our Data Lake and manipulate data within Azure SQL Databases from within its notebooks. A connection is made so that we can create and manually populate metadata tables. Then we will use Databricks to automate and enforce consistency on the creation of new tables that will be the source of template data for Synapse. This will enable Synapse to read the generated table to understand the desired pipeline configuration it should generate and use. Now that we see the need for a place to manipulate metadata, we expose the need to store it, thus justifying the need for an Azure SQL Database. Provided below is an example structure of how a metadata database could be designed.
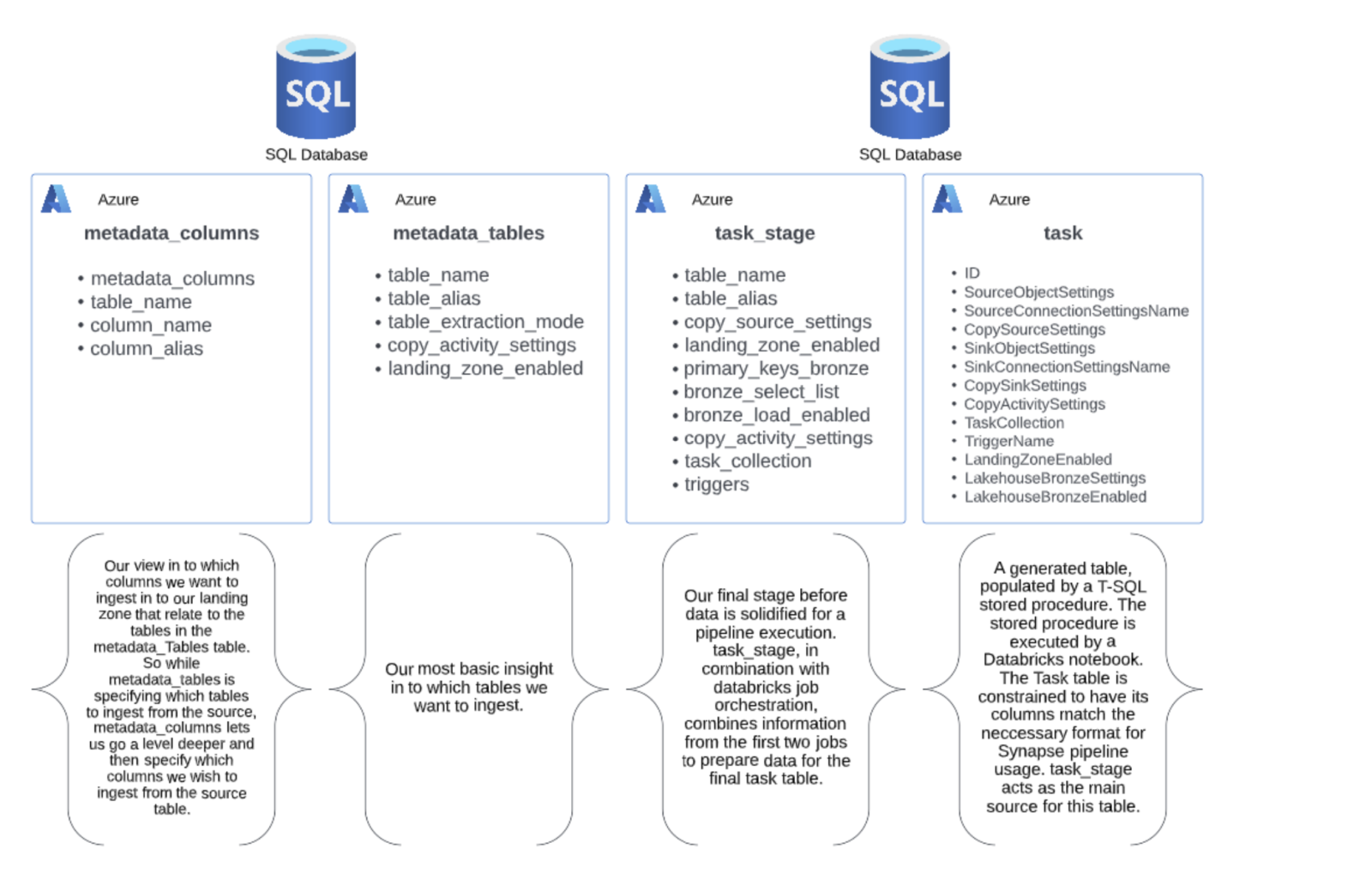
Figure 5: Metadata Structure Example
Four metadata tables are all that are required in this framework to achieve a concise point of control for our pipelines. Two tables require manual population as they are the source metadata information that only our user’s know, but then two tables are generated from scripts. We generate these tables to enforce consistency for what’s going into our development and production systems. Developers can be blocked from accessing these tables to prevent unwanted edits to the metadata that would break pipelines. Standard SQL constraints are placed on our two manual tables to provide an extra layer of consistency and trust throughout. By scripting the table generation in Databricks we ensure that each run will succeed, allowing us to focus more on business value and less on maintenance. In the task table, it may be noticed that most of the columns are from previous tables, but some are new. The new columns match the naming convention and formats expected by our synapse pipeline. This will help in adding an extra protective layer for preventing incorrect metadata edits. These fields will be iterated through and joined together to form one complete JSON template to create our synapse copy pipeline from. Users can be certain that this task table stays consistent in its behavior between releases not only by its programmatic nature but also by creating the task table through a triggered T-SQL stored procedure. It can be programmed in a manner that utilized upserts to avoid possibilities of duplicates while maintaining consistent task IDs for logging purposes. When all said and done, users of this framework have an extremely safe and resilient method for adding tables and columns to a data estate in a reliable and efficient manner by adding rows to these tables.
By now this blog has covered our main objective with the metadata lakehouse approach of simplifying and enforcing consistency on our ELT process but there is plenty of room scattered throughout the pipeline process that we can affect positively with metadata control, and there are additional call outs to be made on what’s possible with the framework given the chosen technologies. Each technology was chosen for a specific reason to enable various benefits and not all are hit on by covering just the ingestion phase as done above. Ultimately though, at this point, a reader should understand how to use metadata to drive a consistent, efficient, and simple to understand and repeat ELT architecture.
Summary
The result of this framework is direct. With the proposed technology stack, businesses can rest assured knowing that they are on highly scalable, future resistant tools that are backed by the top player in cloud service administration. As businesses grow, Azure services are ready to leverage more hardware and further optimized software to power a data estate. On top of this, we can expect constraint-guided, consistent, and straightforward additions of future tables and columns thanks to our metadata principles. Database users only need to edit two tables with limited columns and recognizable concepts. There is more trust in gathering future data and ensuring that it is incrementally brought in the same way to enforce a high rate of success with data ingestion. The task can be handed off to more employees with less experience managing critical data. The possibility of broken tables is reduced significantly. Data will also be brought in with much more detail than average implementations. By leveraging column alias and column description fields in the framework, users will always have full clarity into what they are working with on a more conversational level.
As a result, we have a scalable, resilient, and efficient framework for handling disparate data source workloads that have trouble with being disjointed, sluggish, uninformative, and complex. It can be extended in a repetitive manner and can be enhanced in countless fashions to meet the needs of most problem statements.
Further Deep Dives
Additional Reading: Metadata driven Medallion Architecture through Delta Live Tables
Up to this point we have focused on the optimal technology options for each phase of a revamped Data Platform pipeline as well as how metadata can drive the ingestion process towards a more consistent and formalized pattern. Now let us discuss how metadata can also influence how our data is cleaned and curated for eventual serving. Regarded in the industry as the best approach for dimensional modeling to deliver clear and concise curation of data that also works efficiently at scale, the metadata framework looks for ways to simplify implementation of the Medallion Architecture into the pipeline. Referring back to figure 5 about metadata table structure, there are columns labeled “bronze_select_list” and “bronze_load_enabled”. Named in reference to the 3 data layer concepts of the medallion framework, we can have Databricks pipelines search our database for these columns to dynamical generate CREATE TABLE statements for the medallion architecture based on what we have in our metadata. Columns for each layer, bronze, silver, and gold may be added as necessary and we can also utilize extra metadata columns for further data cleaning such as aliasing. The “bronze_load_enabled” column reflects a concept where we allow users to turn off the ingestion of larger tables or problematic tables at the click of a button. The result of all of this is a completely metadata driven ingestion and compute process that erases a ton of possibility for error and increases confidence in the quality of data at all stages. This will all be driven by Azure Databrick’s Delta Live Tables to leverage the optimizations that it provides. Delta Lives tables is a framework that uses structured streaming that scales based on data volumes and can be instructed to run on specific time schedules to meet the exact needs of its users. DLT (Delta Live Tables) is what orchestrates the creation of the medallion architecture that was just mentioned by automatically chaining the notebooks of commands we create together based on dependencies outlined in queries such as SELECT * FROM <table_name> statements. DLT provides automatic table vacuuming and optimizations to ensure ELT pipelines stay extremely lightweight and perform to the best of their ability with minimal user intervention. Stepping away from functionality that is specifically controlled by Metadata, we have one more feature to highlight that will add great value to your solution when utilized: Databricks SQL.
Additional Reading: Databricks SQL for Data Exploration
Databricks SQL is a Databricks tool for data exploration and insight gathering from within Databricks. As we create tables and views from our notebooks and through delta live tables, we can quickly and simply query this data through a friendly GUI. This lives within a “SQL” tab in the Databricks workspace in which all data created by Databricks can be viewed. Given that we have centralized all our compute processes to Databricks, we can always be assured that we are looking at our most complete and up to date data and do not have to worry about its manipulation from the outside. Databricks SQL only makes itself available as a compute service when a DBX cluster is running, so while our users are not querying data or doing maintenance, users can rest easy knowing they are not being charged for excess compute operations. Databricks SQL is fast, and has autoscaling capabilities to meet the needs of large organizations. Its multiple different prebuilt clusters ensure that many users can work in parallel while executing complex analytic queries. A separate system for a data warehouse is no longer required and thus combining Databricks with permission management, Databricks SQL offers the most user-friendly way to explore data and manipulate it in a tightly secured fashion.
Additional Reading: Leveraging SAP Standardization Concepts
Those familiar with SAP workloads have become acquainted with the predetermined and cryptic SAP database table and field names. For those unaware, there are endless amounts of uninformative naming conventions used to create table and column names such as KNVV or KNV1. Most relational databases avoid this sort of headache by allowing custom naming of fields and tables, but we can take advantage of this standardization to introduce extreme clarity in just a few steps.
When ingesting SAP tables, we gain the benefit of being able to look up and utilize free resources that put friendly names on the confusing SAP glossary of tables and columns. So, while populating our metadata tables and columns entries, we can utilize the internet for aliases and avoid database exploration that would then lead to governance discussions internally to agree on naming conventions. After populating a new column with this found information, incorporate a column lookup like previous techniques while authoring table CREATE statements in our compute process and watch the power of metadata do its magic. After this, users may go a step further and leverage the table and column descriptions these websites have to then create another column in the metadata tables that can be looked up to dynamically add table and column descriptors unique to departments or businesses for the deepest form of insight into data.



