
Kappa architecture proposes an immutable data stream as the primary source of record. Unlike lambda, kappa mitigates the need to replicate code in multiple services. In my last post, I introduced the lambda architecture tooling options available in Microsoft Azure, sample reference architectures, and some limitations. In this post, I’ll discuss an alternative Big Data workload pattern: kappa architecture.

Below, I’ll give an overview of what kappa is, discuss some of the benefits and tradeoffs of implementing kappa versus lambda in Azure, and review a sample reference architecture. Finally, I’ll offer some added considerations when implementing enterprise-scale Big Data architectures.
Kappa Architecture: the Immutable, Persisted Log
Kappa architecture, attributed to Jay Kreps, CEO of Confluent, Inc. and co-creator of Apache Kafka, proposes an immutable data stream as the primary source of record, rather than point-in-time representations of databases or files. In other words, if a data stream containing all organizational data can be persisted indefinitely (or for as long as use cases might require), then changes to code can be replayed for past events as needed. This allows for unit testing and revisions of streaming calculations that lambda does not support. Kappa architecture also eliminates the need for a batch-based ingress process, as all data are written as events to the persisted stream. Kappa architecture is a novel approach to distributed-systems architecture, and I personally enjoy the design philosophy behind it.
Apache Kafka
Kafka is a streaming platform purposefully designed for kappa, which supports time-to-live (TTL) of indefinite time periods. Utilizing log compaction on the cluster, the kafka event stream can grow as large as you can add storage. There are petabyte-sized (imagine the U.S. Library of Congress) kafka clusters in production today. This sets kafka uniquely apart from other streaming and messaging platforms because it can replace databases as the system of record. Here are a few fascinating write-ups on kafka’s capabilities:
- Questioning the Lambda Architecture, by Jay Kreps
- Kafka, Samza, and the Unix philosophy of distributed data, by Martin Kleppmann
- It’s Okay To Store Data In Apache Kafka, by Jay Kreps
- Publishing with Apache Kafka at The New York Times, by Boerge Svingen
Lambda vs. Kappa
Let’s go with kappa architecture. What are we waiting for, right? Well, there’s no free lunch. Kappa offers newer capabilities compared with lambda, but you do pay a price when implementing leading-edge technologies – specifically, as of today, you’re going to have to roll in some of your own infrastructure to make this work.
No Managed-Service Options
You can’t support kappa architecture using native cloud services. Cloud providers, including Azure, didn’t design streaming services with kappa in mind. The cost of running streams with TTL greater than 24 hours is more expensive, and generally, the max TTL tops out around 7 days. If you want to run kappa, you’re going to have to run Platform as a Service (PaaS) or Infrastructure as a Service (IaaS), which adds more administration to your architecture. So, what might this look like in Azure?
Reference Architecture for Kappa with HDInsight
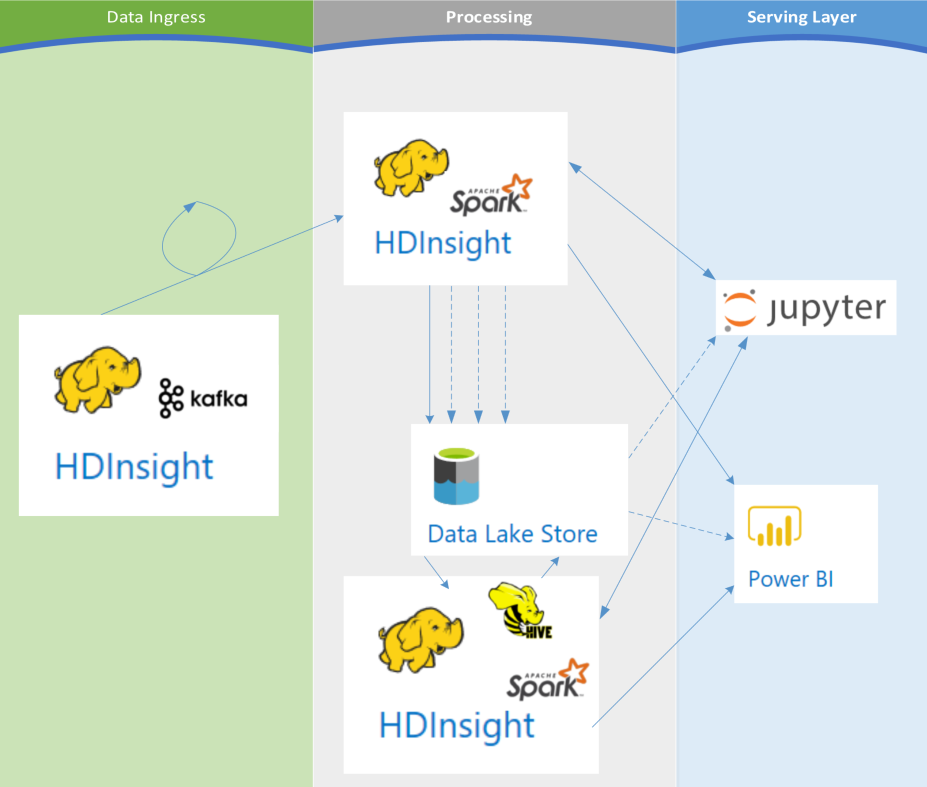
In this reference architecture, we are choosing to stream all organizational data into kafka. Applications can read and write directly to kafka as developed, and for existing event sources, listeners are used to stream writes directly from database logs (or datastore equivalents), eliminating the need for batch processing during ingress. In practice, a one-time historical load for existing batch data is required to initially populate the data lake.
Apache Spark is the sole processing engine for transforming and querying during stream ingestion. Further processing against the data lake store can be performed for machine learning or other analytics requiring historical representations of data. As requirements change, we can change code and “replay” the stream, writing to a new version of the existing time slice in the data lake (v2, v3, and so on). Since our lake no longer acts as an immutable datastore of record, we can simply replay and rebuild our time slices as needed.
With kappa in place, we can eliminate any potential swamp by repopulating our data lake as necessary. We also eliminate the requirement of lambda to reproduce code in both streaming and batch processing – all ingress events and transforms occur solely within stream processing.
Additional Considerations
Schemas and Governance
You still need a solid data governance program regardless of which architecture you choose. For lambda, services like Azure Data Catalog can auto-discover and document file and database systems. Kafka doesn’t align to this tooling, so supporting scaling to enterprise-sized environments strongly infers implementing confluent enterprise (available in the Azure Marketplace).
A key feature that confluent enterprise provides is schema registry. This allows for topics to be self-describing and provides compatibility warnings for applications publishing to specific topics, ensuring contracts with downstream applications are maintained. Running confluent enterprise brings in a third-party support relationship to your architecture and additional licensing cost, but is invaluable to successful enterprise-scale deployments.
Which Architecture is Right for my Organization?
There are a lot of considerations when developing Big Data solutions for enterprises, not the least of which is the experience and skills of your IT and development teams. Like most successful analytics projects, the key is to start small in scope with well-defined deliverables, then iterate. The primary goal is to minimize time to value – the reason for considering distributed systems architecture in the first place! Partnering with a trusted advisor, like BlueGranite, can help you avoid common pitfalls in implementing Big Data solutions and set your team and organization up for success.
Want to learn more about how BlueGranite can help implement Big Data solutions at your organization? Contact us!



