
At 3Cloud, we have observed some customer confusion around when Azure SQL Data Warehouse (SQL DW) is most appropriate to use. Therefore, this blog post is meant to help you answer the question: Is Azure SQL Data Warehouse the best technology choice for your implementation?
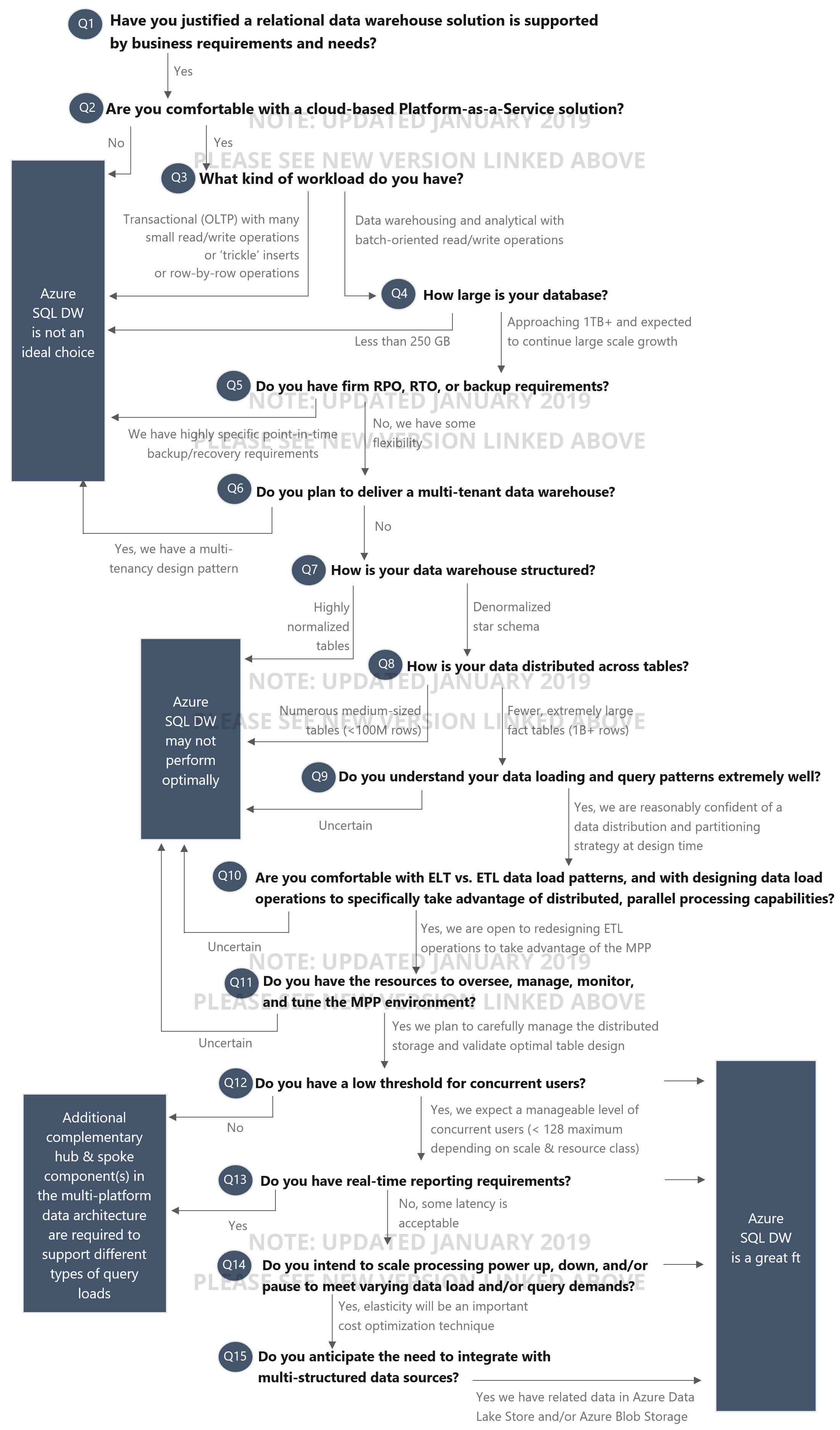
The following comments highlight each of the items in the decision tree above:
Q1: Have you justified that a relational data warehouse solution is supported by business requirements and needs?
The most common justifications for a data warehouse implementation include:
Consolidate and relate multiple disparate data sources. Data is inherently more valuable once it has been integrated together from multiple sources. A common example cited is the 360-degree view of a customer which could align customer master data, sales, open receivables, and support requests.
Centralize analytical data for user data access. A data warehouse can certainly support corporate BI efforts (typically thought of as standardized corporate reports and dashboards). It can also play a big role in self-service BI efforts by providing consistent, cleansed, governed data. Realistically, a “single version of the truth” can never be 100% met, but effective governance and master data management can increase the odds that the data warehouse provides consistent and accurate data.
Historical analysis. The data warehouse supports historical reporting and analysis via techniques such as periodic snapshots and slowly changing dimensions. A common scenario is a customer’s sales representative has changed this quarter, or a department rolls up to a different division now. The flexibility to report on either “the way it was” or “the way it is” can offer significant value – and is rarely available from standard source systems.
User-friendly data structure. It is valuable to structure the data into a user-friendly dimensional model which really helps the largest portion of the user base. Other techniques, such as friendly table and column names, and derived attributes and measures, contribute to ease of use. Time investments here should encourage data analysts to utilize the data warehouse, leading to consistent results and in turn saving time and effort.
Minimize silos. When a business-driven analytical solution (often referred to as shadow IT) becomes important to running the business, that is a signal that it’s time to promote it up to a centralized system so that it can be supported more fully, integrated with other data, and made available to a larger user base. The data warehouse can take advantage of business user efforts and continue gaining in maturity and value, as well as minimize silos and “one-off” solutions.
Multi-platform architecture which takes advantage of existing investment. If your existing data warehouse does bring value for certain use cases, it is not economically feasible to retire it or migrate everything to another architecture (ex: Hadoop or data lake). Instead, we recommend a multi-platform architecture in which the data warehouse is one, albeit important, component. For instance, using a data lake for data ingestion, exploratory analysis, staging for a data warehouse, and/or archival from the data warehouse, are all complementary to the DW, which can handle serving much of the curated, cleansed data.
Q2: Are you comfortable with a cloud-based Platform-as-a-Service solution?
Azure SQL DW is a cloud offering. It is a PaaS solution in which the customer has no responsibility or visibility to the underlying server architecture. The storage and compute are decoupled, which is an advantage of Azure SQL DW. Costs for processing power (compute) are based on a consumption model that is controlled by data warehouse units (DWUs), which can be scaled to meet demanding data loads and peak user volumes. The data must be stored on Azure premium storage, which performs better than standard storage and thus is more expensive. It is important to be aware that Azure SQL DW is part of the SQL Server family, but there are some limitations and feature differences between Azure SQL DW, Azure SQL DB, and SQL Server.
Q3: What kind of workload do you have?
Azure SQL DW is only appropriate for analytical workloads: batch-oriented, set-based read and write operations. Workloads which are transactional in nature (i.e., many small read and write operations), with ‘trickle’ inserts and/or many row-by-row operations are not suitable.
Q4: How large is your database?
It is difficult to pinpoint an exact number for the absolute minimum size recommended for Azure SQL DW. Many data professionals in the industry see the minimum “practical” data size for Azure SQL DW in the 1-4TB range. Microsoft documentation has recently stated as low as 250GB for a minimum size. Since Azure SQL DW is an MPP (massively parallel processing) system, you experience a significant performance penalty with small data sizes because of the overhead incurred to distribute and consolidate across the nodes (which are distributions in a “shared-nothing” architecture). We recommend Azure SQL DW for a data warehouse which is starting to approach 1TB and expected to continue growing.
Q5: Do you have firm RPO, RTO, or backup requirements?
Being a PaaS offering, Azure SQL DW currently handles snapshots and backups each day, and supports an 8-hour recovery point objective (RPO) for local backups, and a 24-hour recovery point objective for geo-redundant backups, over the prior 7 days. Azure SQL DW does not currently support manually-generated backups at a specific point in time, nor does it support piecemeal restores. Backups are not taken when the compute power (DWUs) are paused. You can query to find when backups occur, but in this PaaS offering you cannot currently control when backups are taken.
Q6: Do you plan to deliver a multi-tenant data warehouse?
A multi-tenancy database design pattern is discouraged for Azure SQL DW. Features, such as row-level security, to support individual tenants are not available in Azure SQL DW.
Q7: How is your data warehouse structured?
A highly normalized data warehouse structure does not completely preclude you from using Azure SQL DW. However, since Azure SQL DW takes significant advantage of clustered columnstore indexes, it performs substantially better with denormalized data structures. Therefore, following sound dimensional design principles are strongly advised.
Q8: How is your data distributed across tables?
Even if you have a large database (1TB+), table distribution is another consideration. An MPP system such as Azure SQL DW performs better with fewer, larger tables versus many small to medium-size tables.
Q9: Do you understand your data loading and query patterns extremely well?
Being a relational database, Azure SQL DW is considered “schema on write.” Since it is also a distributed system, a distribution key needs to be defined for each table when it is initially defined so that the SQL DW knows how to distribute the data across the nodes. The selection of a good distribution key is critical for performance. Additionally, partitioning strategies are different in SQL DW vs. standard SQL Server. It is extremely important for the database developers to deeply understand data load patterns and query patterns in order to maximize parallelization, avoid data skew, and minimize data movement operations within the MPP platform.
Q10: Are you comfortable with ELT vs. ETL data load patterns, and with designing data load operations to specifically take advantage of distributed, parallel-processing capabilities?
The principles for loading a distributed system (MPP) are very different from a traditional system (SMP). To utilize parallelization across the compute nodes, PolyBase and ELT (extract>load>transform) techniques are recommended for SQL DW data load processes. This means that migration to Azure SQL DW often involves redesigning existing ETL operations to maximize performance, and/or utilize supported features (for example, merge statements are not currently supported in SQL DW).
Q11: Do you have the resources to oversee, manage, monitor, and tune the MPP environment?
Although Azure SQL DW is a PaaS platform, it should not be thought of as a hands-free environment. It requires monitoring of data loads and query demands to determine if distribution keys, partitions, indexes, and statistics are configured the best way. Unlike Azure SQL DB which has some auto-tuning capabilities, Azure SQL DW does need “care and feeding” on a regular basis.
Q12: Do you have a low threshold for concurrent users?
Queries are queued up if the number of concurrent users or concurrent queries are exceeded, and are resolved on a first-in-first-out basis. The concurrent user limit can be as high as 128 depending on the service level and based on resource class usage. Because of concurrent user considerations, Azure SQL DW frequently has complementary solutions in a multi-platform architecture for handling different types of query demands. We often see Azure Analysis Services, which also has the benefit of a semantic layer, and/or Azure SQL Database as the spokes in a hub and spoke design.
Q13: Do you have real-time reporting requirements?
Because of its distributed nature, Azure SQL DW is not an ideal solution for displaying real-time data. SQL DW cannot handle high volumes of singleton inserts (i.e., a “hot path” destination in a Lambda architecture), nor is it expected to return data in sub-second response times. Additionally, DirectQuery mode from Power BI generally will not provide query response times that are acceptable to users, so we recommend you test that approach thoroughly.
Q14: Do you intend to scale processing power up, down, and/or pause to meet varying data load and/or query demands?
One of the best features of a cloud offering like Azure SQL DW is its elasticity of compute power. For instance, you could scale up on a schedule to support a demanding data load, then scale back down to the normal level when the load is complete. The SQL DW can even be paused during times when no queries are sent to the data warehouse at all, during which the storage of data is safe yet there’s no compute charges at all. This avoids over-provisioning of resources which is an excellent cost optimization technique.
Q15: Do you anticipate the need to integrate with multi-structured data sources?
These days, it is very common for a data warehouse to be complementary to a data lake which contains multi-structured data from sources such as web logs, social media, IoT devices, and so forth. Although Azure SQL DW does not support data types such as JSON or XML, it can work in conjunction with Azure Blob Storage and/or Azure Data Lake Store for data integration scenarios and very selective data virtualization and federation scenarios.
If you’re exploring the best data analytics architecture for your firm’s needs, BlueGranite would love to help. Contact us today to discover how our team designs solutions that fit your company and your budget.



