
Conceptually, data virtualization has been around since 1982 when computer scientist Edgar Codd proposed his “data independence objective,” separating the logical and physical aspects of database management. Given its age, data virtualization should be as ubiquitous as computer viruses, which also found their start in 1982. Instead, the programming world adopted the concept, bringing us object-oriented programming, but data virtualization languished in the enterprise data model.

Over the past decade, data virtualization has struggled from an implementation standpoint due to its early lackluster performance and functionality. But for industry analysts such as Gartner and Forrester, and experts such as R20/Consultancy Managing Director Rick van der Lans (in a 2017 presentation for The Data Warehouse Institute), the recent evolution of commercial data virtualization products counters the previous stigmas. As of July 2017, Gartner’s Hype Cycle for Data Management shows data virtualization in the Plateau of Productivity along with database Platform as a Service and data quality tools. As mature as this technology sounds, most of our clients have yet to consider software data virtualization, and sometimes confuse it with data federation.
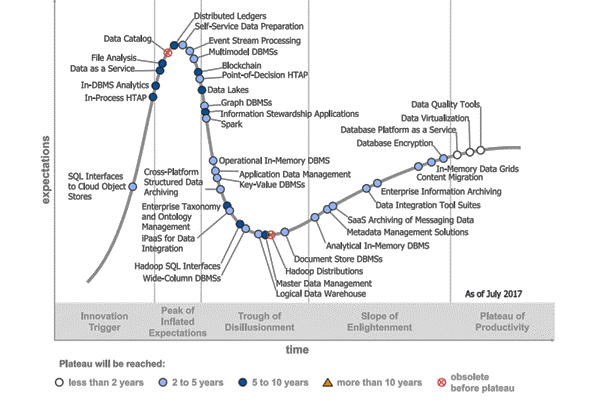 Image credit: Gartner Reveals the 2017 Hype Cycle for Data Management. Retrieved from https://www.gartner.com/newsroom/id/3809163
Image credit: Gartner Reveals the 2017 Hype Cycle for Data Management. Retrieved from https://www.gartner.com/newsroom/id/3809163
Data federation is one function of data virtualization, but it is limited to only consolidating heterogeneous data sets of source systems. According to a van der Lans whitepaper for Quant ICT Group, data virtualization platforms should provide integration, transformation, abstraction, and encapsulation. Whereas federation provides heterogeneous integration and light transformation, but a very limited abstraction. Today’s data virtualization tools provide additional management of query optimization, metadata management, data quality, distributed transactions, and, through encapsulation, the ability to present multiple interfaces for data service-oriented architectures or third-party integrations.
Performance
Performance continues to draw skepticism around data virtualization platforms, but there are numerous innovations around query optimization, query pushdown, caching, and distributed architectures. Most of the top data virtualization platforms accommodate multiple methods of performance enhancement to ensure a positive user experience.
Functionality
Data virtualization takes a lot of integration pain points away by avoiding multiple copies of the logical data and providing complete access to data lineage, from the source to the presentation layer for business intelligence. Additional data points can be added without having to change transformation packages or staging tables. All data presented through the data virtualization software is available through a common SQL interface regardless of the source – whether flat file, Excel, mainframe, relational database management system (RDBMS), online analytical processing (OLAP), big data, or other.
Beyond the Hype
Gartner says data virtualization is well beyond the hype cycle and Forrester, in The Forrester Wave™: Enterprise Data Virtualization , Q4 2017, agrees, calling it “…critical to every organization in overcoming growing data challenges.”
In an earlier role, one of my former CEO’s directives was to make data available and easily accessible. Many of BlueGranite’s clients have developed data strategies around similar philosophies and, from a strategy perspective, data virtualization is a great fit.
If you have evaluated data virtualization in the past, it may be time to re-evaluate. Currently one of the top platforms, Denodo, is available on Microsoft Azure for a free 30-day trial. If you would like to know more about data virtualization, or how to leverage the free trial in Microsoft Azure, we’d love to help. Contact us today!



