
This technology is no longer the recommended approach. For a flexible computing platform, consider Azure Databricks.
Azure Data Lake Analytics is a distributed, cloud-based data processing architecture offered by Microsoft in the Azure cloud. It is used to help quantify Azure Data Lake which is an ever-evolving set of technologies that currently looks somewhat like this:
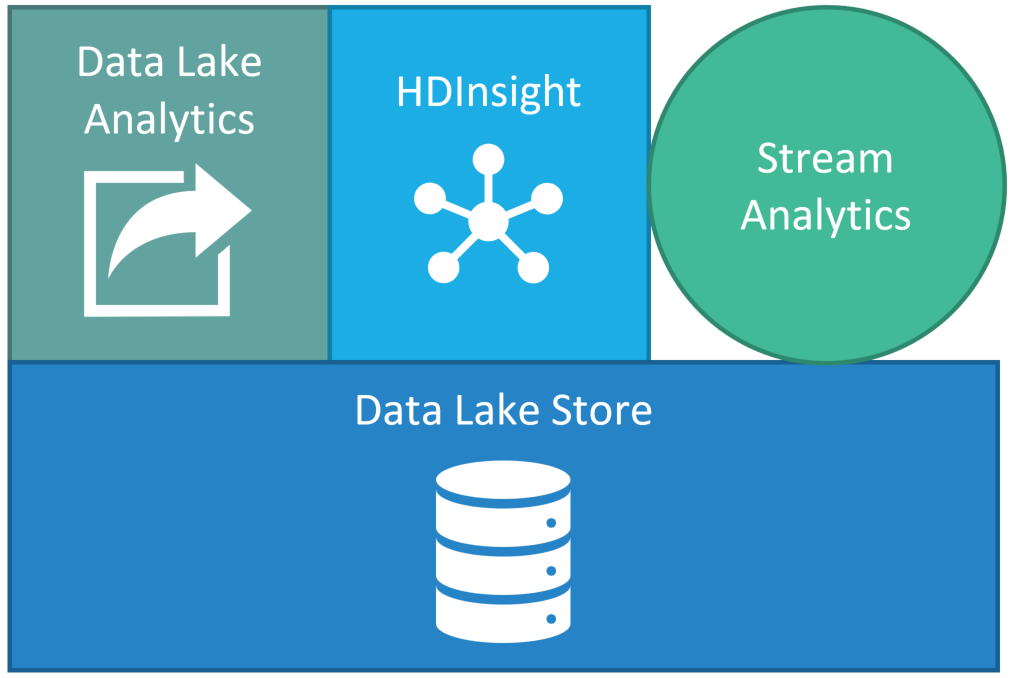
With Azure Data Lake Store (ADLS) serving as the hyper-scale storage layer and HDInsight serving as the Hadoop-based compute engine services, I’ve been confused as to where Data Lake Analytics fits. On the surface, it appears to provide the same services as HDInsight — Big Data batch processing — and it does. But it takes a unique approach.
In late April 2017, BlueGranite was invited to a partner-only Microsoft training event where I learned an awful lot about Azure Data Lake Analytics (ADLA), and got to spend time with the product team that’s developing it. We learned about the ADLA product roadmap, most of which can’t be shared publicly yet, but I’ll give you a teaser; AWESOME STUFF IS COMING OUT IN THE FUTURE! STAY TUNED!
More importantly, however, I learned how ADLA fits into a larger data management strategy and why you might want to use it in your next project.
In this article, I’d like to explain this approach to you in hopes that it might demystify where ADLA fits in with your Big Data solution.
So, what is Azure Data Lake Analytics anyway?
Azure Data Lake Analytics is a distributed, cloud-based data processing architecture offered by Microsoft in the Azure cloud. It is based on YARN, the same as the open-source Hadoop platform. It pairs with Azure Data Lake Store, a cloud-based storage platform designed for Big Data analytics.
Aside from the technical specs, ADLA is a platform that enables processing of extremely large data sets, integration with existing Data Warehousing, and true parallel processing of structured and unstructured data. It’s relatively easy to learn, builds on technical skills found in almost every enterprise, and has a very low entry cost and an easy-to-manage (and understand!) pricing structure.
ADLA is a direct descendent of Microsoft’s homegrown Big Data solution, Cosmos. While details for Cosmos are scarce due to its internal-only nature within Microsoft, we do know that Cosmos is built to handle “exabyte-scale” and “hundreds of thousands of jobs daily” from this article announcing Azure Data Lake as a new service. Cosmos, and its corresponding data language SCOPE (an ancestor of U-SQL), has been heralded within the Microsoft employee community as being easy to use and extremely scalable — two great features enterprise is looking for in a Big Data solution.
What can I do with Azure Data Lake Analytics?
Right now, ADLA is focused on batch processing, which is great for many Big Data workloads. Some example uses for Azure Data Lake Analytics include, but are not limited to:
- Prepping large amounts of data for insertion into a Data Warehouse
- Processing scraped web data for science and analysis
- Churning through text, and quickly tokenizing to enable context and sentiment analysis
- Using image processing intelligence to quickly process unstructured image data
- Replacing long-running monthly batch processing with shorter running distributed processes
ADLA is well equipped to handle many of the types of processing we do in the T portion of ETL; that is, transforming data. If you’ve found that your data volumes have increased, changed shape, or you are generally not happy with your ETL performance, Azure Data Lake Analytics might serve as a good replacement for your traditional approach to prepping data for analysis.
What makes it different?
It’s hard to not compare ADLA to Hadoop, and rightfully so. ADLA provides much of the same functionality that Hadoop provides with Hive and Spark. However, Azure Data Lake Analytics does take a different approach in a number of areas:
Only one language to learn
OK, this is kind of tricky, because, although there is only one language to learn, U-SQL, it’s really an amalgam of SQL and C# – so if you’re familiar with either or both of those languages then you’ll be ready to tackle U-SQL. If you’re not familiar with either, then it’s OK, you don’t have to be a SQL or C# master to understand U-SQL.
With Hadoop, you’ll have a few more languages to learn – I’d say at least six (Hive, Pig, Java, Scala, Python, Bash; yup, six).
Only offered as a platform service
Hadoop comes in many different flavors, some running on-premises, others running in the cloud. Some are managed BY you, others are managed FOR you.
ADLA, however, is offered ONLY as a platform service in the Microsoft Azure Cloud. It’s managed by Microsoft — you’ll never have to troubleshoot a cluster problem with ADLA (only your own code). It’s also integrated with Azure Active Directory, so you don’t have to manage security separately.
Really, all you have to worry about when you set up an Azure Data Lake Analytics account is building your application.
Pricing per job; not per hour
Most Big Data cloud offerings that are available are priced per hour based on how long you keep your cluster up and running. ADLA takes a different approach to pricing.
With ADLA, you pay for each individual job that is run. Each job run through ADLA is assigned a number of Analytic Units (AUs). Each job is billed based on how many AUs were used and how many hours the job ran. So a simple job that used 10 AUs for one hour would be billed for 10 processing hours.
As a matter of fact, just owning an Azure Data Lake Analytics account doesn’t cost anything. You aren’t even billed for the account until you run a job. That’s pretty unique in the Big Data space.
Any killer features to look out for?
While Azure Data Lake Analytics are relatively new (to the public) technology, it does already have some great uses that cause it to stand out from the traditional Big Data offerings.
When the U-SQL team released their first product, they had the foresight to include a rich set of Intelligent libraries. These libraries allow for deep machine intelligence to be embedded in day-to-day processing, and make it very simple to implement.
This feature, above all others, stands out to me. As these libraries mature, and the U-SQL language gains more functionality, the ability to wring even more valuable data out of the myriad information we are creating daily will be possible.
U-SQL, when paired with Visual Studio as a development environment, also makes the development and optimization process a pleasant one. Trolling through MapReduce or Spark logs is not high on the fun-scale for anyone that I know. The ADLA team recognized this and built a great set of debugging and analysis tools into Visual Studio that make it possible to squeeze every last bit of performance out of your U-SQL application.
How do I get started?
You might be thinking “Oh great, this is where the catch is,” but you’re wrong! Getting started with Azure Data Lake Analytics is really easy! No, really, I mean it! Here’s what you’ll need:
- An Azure subscription — grab a free trial if you don’t have one
- An Azure Data Lake Analytics account — create one in your Azure subscription
- You’ll also create an Azure Data Lake Store account during this step
- Some data to play with — start with some text, or maybe some images
You don’t even need to install anything on your personal computer to use it. You can write and submit jobs in your favorite browser.
If you’d like a hands-on tour of Azure Data Lake Analytics, why not check out the free BlueGranite labs? We wrote these labs in partnership with Microsoft, and they are a great way to get to know ADLA and U-SQL.



