In my 17 years of database development, a few projects stand out from requirements so elaborate that I really had to stretch my imagination. One such assignment required the importation of comma separated value (CSV) files where the fields may not be in the same place and new fields may appear without warning. As you can imagine, this wouldn’t have been difficult if the source was a semi-structured format like JSON, but in this case, it was good old CSV.

Thanks to the new functions within SQL Server 2016, this once-daunting task becomes easily doable when you combine dynamic SQL statements and String_Split. String_Split is a unique function where you can take a list of strings and parse them into rows. See the example from MSDN below:
SELECT valueFROM STRING_SPLIT(‘Lorem ipsum dolor sit amet.’, ‘ ‘);
| value |
| Lorem |
| ipsum |
| dolor |
| sit |
| amet. |
If you are already thinking that this will provide you with a separate row for each field name of the CSV, you are headed in the right direction. String_Split can provide a glimpse into the format of any CSV file, and with the help of the Pivot operator and dynamic SQL statements, you can build a process to handle changing file structures or the addition of new fields without having to rewrite your code.
Technical Requirements
In this instance, sensor data is coming from a 3rd party vendor, and after it is processed by a proprietary tool, a CSV file is cut for the client to consume. Per the specifications, only the 1st field is consistent and will contain a date, but all other fields may be in a different order or include never-before-seen fields. Another important piece of information to make note of is that all fields, aside from the date, will be floats (large decimals).
| date | sensor1 | sensor2 | sensor3 | sensor4 |
| 19-06-2017 12:00:00.500 | 0.1 | 5.0 | 600.0 | 1700.0 |
File Example 1
| date | sensor5 | sensor1 | sensor3 | sensor17 |
| 20-06-2017 12:00:00.500 | 6.5 | 21.0 | 168.5 | 2.0 |
File Example 2
High-Level Approach
Let’s walk through each step of the process, using the file examples above as a guide. Below is a summary of the steps we will take with more details to follow further down.
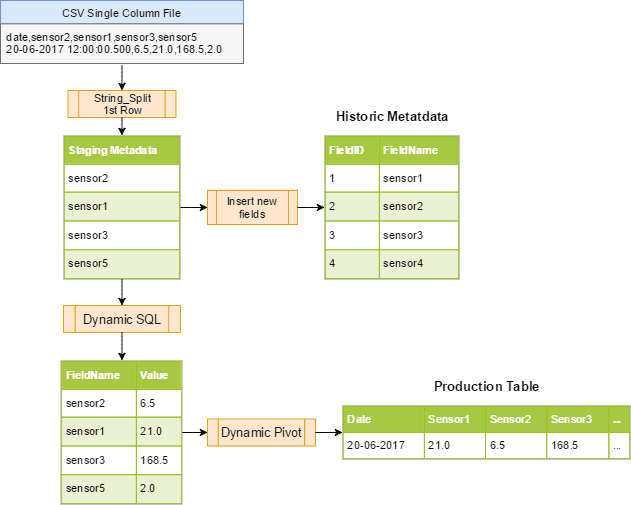
Step 1: Import CSV into a single-column staging table
Step 2: Parse 1st row into a staging metadata table (field names)
Step 3: Compare staging metadata to historic metadata and add new fields if necessary
Step 4: Assemble dynamic pivot query to parse and insert values into staging table
Step 5: Assemble dynamic query to insert into production table
Step 1:
Import the CSV into a staging table so that all the data is in 1 column. This can be done by using an obscure delimiter that doesn’t appear in the file like ‘|’ or ‘~’. The point is to keep all the data together so that String_Split can be used on the entire row of data.
Step 2:
Capture the first row of data into a variable and use the String_Split function to capture the Fields into a staging metadata table (example code below). The staging metadata table is very important when creating the dynamic Insert / Select statements to persist the correct order of the fields since they can vary.
DECLARE @Header VARCHAR(5000), @FieldName VARCHAR(5000);
SELECT @Header = DataTXT
FROM stage.sensor
WHERE RowID = 1
AND FileID = @FileID;
WHILE
(
SELECT CHARINDEX(‘,’, @Header, 1)
) > 1
BEGIN
SELECT @FieldName = LEFT(@Header, CHARINDEX(‘,’, @Header, 1)-1);
INSERT INTO stage.metadata
(FileID,
FieldName
)
VALUES
(@FileID,
@FieldName
);
SET @Header = SUBSTRING(@Header, CHARINDEX(‘,’, @Header, 1)+1, 5000);
END;
INSERT INTO stage.metadata
(FileID,
FieldName
)
VALUES
(@FileID,
@Header
);
Step 3:
After capturing the fields from the incoming file, you should compare them to the existing metadata fields expected in the resulting table that the data will be inserted into. The following code creates dynamic SQL statements that can be executed against the production table to add additional fields. Since it’s a given that the fields are all floats except ‘date’, then you don’t have to worry about conversion issues. However, we worked out a solution that added an additional field to the metadata table indicating the data type for future flexibility.
DECLARE cur_fields CURSOR FORWARD_ONLY
FOR SELECT
s.FieldName,
‘Alter Table dbo.sensor ADD [‘+s.FieldName+‘] FLOAT’ AS Remediation
FROM stage.metadata AS s
WHERE NOT EXISTS
(
SELECT
*
FROM dbo.metadata AS m
WHERE s.FieldName = m.FieldName
)
AND s.FileID = @FileID
DECLARE @FieldName VARCHAR(500),
@sqlAlter NVARCHAR(1000);
OPEN cur_fields;
FETCH NEXT FROM cur_fields INTO @FieldName,
@sqlAlter;
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO dbo.metadata_history
(
FileID,
FieldName
)
VALUES
(@FileID,
@FieldName
);
INSERT INTO dbo.metadata
(
FieldName
)
VALUES(@FieldName);
EXEC sp_executesql
@sqlAlter;
FETCH NEXT FROM cur_fields INTO @FieldName,
@sqlAlter;
END;
Steps 4 & 5:
The last 2 steps are accomplished using 1 procedure as shown in the code below. The first part will use the metadata tables to pull out the fields necessary for the Select and the Insert. A dynamic SQL statement is then created to parse the data within the CSV, skipping the header row. The final dynamic SQL statement creates a Merge based on some other client requirements, but a simple insert would also work depending on your situation.
DECLARE @sqlCMD NVARCHAR(MAX),
@sqlHeader NVARCHAR(MAX),
@sqlStage NVARCHAR(MAX),
@Fields NVARCHAR(MAX),
@SourceFields NVARCHAR(MAX),
@SetFields NVARCHAR(MAX);
SET @Fields = ”;
SET @SourceFields = ”;
SET @SetFields = ”;
SELECT
@Fields = @Fields+‘[‘+FieldName+‘], ‘,
@SourceFields = @SourceFields+‘source.[‘+FieldName+‘], ‘,
@SetFields = @SetFields+‘target.[‘+FieldName+‘] = source.[‘+FieldName+‘], ‘
FROM stage.metadata
WHERE FileID = @FileID
AND FieldID > 0;
SET @Fields = LEFT(@Fields, LEN(@Fields) – 1);
SET @SourceFields = LEFT(@SourceFields, LEN(@SourceFields) – 1);
SET @SetFields = LEFT(@SetFields, LEN(@SetFields) – 1);
TRUNCATE TABLE stage.sensor_parsed;
SET @sqlHeader = ‘WITH RawData(RowID, FieldID, Date, SensorValue) AS (SELECT RowID, ROW_NUMBER() OVER(PARTITION BY RowID ORDER BY RowID) AS FieldID, LEFT(DataTXT, CHARINDEX(‘+””+‘,’+””+‘, DataTXT, 1)-1) AS Date, value FROM stage.sensor s CROSS APPLY string_split (SUBSTRING(DataTXT, CHARINDEX(‘+””+‘,’+””+‘, DataTXT, 1)+1, 5000), ‘+””+‘,’+””+‘) WHERE FileID = ‘+CONVERT(VARCHAR(10), @FileID)+‘ AND RowID >= 1 and isnumeric(value) = 1), Result(RowID, Date, FieldID, FieldName, SensorValue) AS (SELECT r.RowID, Date, m.FieldID, m.FieldName, r.SensorValue FROM stage.metadata AS m JOIN RawData AS r ON m.FieldID = r.FieldID where m.FileID = ‘+CONVERT(VARCHAR(10), @FileID)+‘) ‘;
SET @sqlStage = ‘insert into stage.sensor_parsed (RowID, Date, EquipmentID, FieldID, FieldName, SensorValue) select RowID, Date, FieldID, FieldName, SensorValue from Result where SensorValue is not NULL’;
SET @sqlCMD = @sqlHeader + @sqlStage;
EXEC sp_executesql
@sqlCMD;
SET @sqlCMD = ”;
SELECT
@sqlCMD = ‘merge dbo.sensor as target using (SELECT ‘+CONVERT( VARCHAR(10), @FileID)+‘, [Date], ‘+@Fields+‘, getdate() as [CreateDT] from (select [RowID], [Date], [FieldName], [SensorValue] from stage.sensor_parsed ) as s Pivot(Max([SensorValue]) for [FieldName] in (‘+@Fields+‘)) as p) as source ([FileID], [Date], ‘+@Fields+‘, [CreateDT]) on (target.[Date] = source.[Date] and target.[FileID] = source.[FileID]) when matched then update set ‘+@SetFields+‘ when not matched then insert([FileID], [Date], ‘+@Fields+‘, [CreateDT]) values (source.[FileID], source.[Date], ‘+@SourceFields+‘, source.[CreateDT]);’;
EXEC sp_executesql
@sqlCMD;
Summary
These project requirements really drove the direction of this process, resulting in a SQL table that can expand horizontally as new fields come in through the CSV. However, there are endless scenarios making for an even simpler process, assuming requirements differ from the above-mentioned project, and you have the freedom to consider other storage methods, such as JSON.
String_Split is a fantastic new tool for dealing with edge cases and in this engagement, it provided a fairly elegant solution which would have been next to impossible in prior versions of SQL Server.
Have questions about SQL? Our team of experts would love to chat with you!