
There is no shortage of choices when it comes to designing an architecture for HDInsight projects. There are multiple cluster types, multiple operating systems, multiple storage options, deployable applications — it’s a maze of choices that can often be overwhelming. In this article, I’ll provide clarity into the decisions that go into designing the appropriate HDInsight architecture.
First, let’s cover some HDInsight basics.
Is HDInsight that much different from designing an on-premises cluster?
Whether your Hadoop cluster is on-premises or in the cloud, it contains two main resources: compute resources to process jobs, and storage resources to hold data. In an on-premises cluster, the storage and compute resources are combined into the same hardware tying them together. With HDInsight the storage is wholly separated from the compute resource. This is a very important distinction of HDInsight. It means that I can completely turn off the compute portion of the cluster and the data will remain accessible.
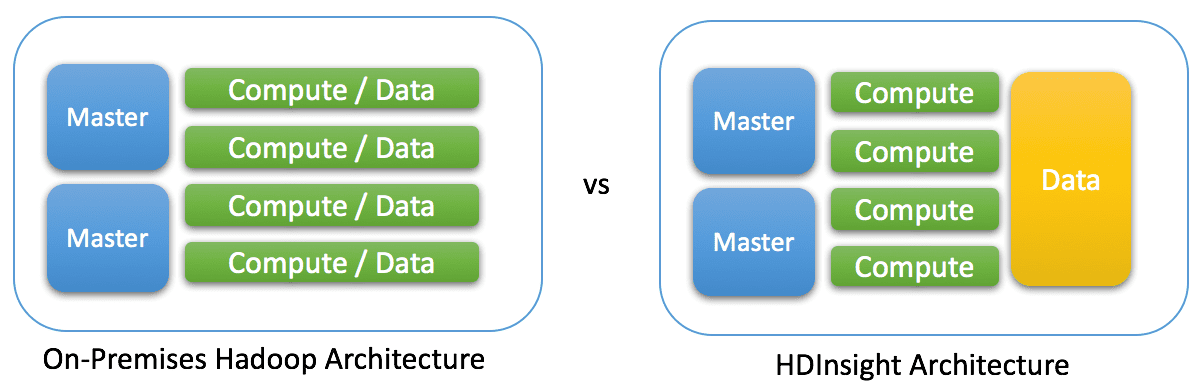
Because of this major distinction, it allows me to architect HDInsight solutions much differently than those designed with traditional on-premises Hadoop clusters. With on-premises clusters, I have to design them based on the amount of data that is planned to be stored, processed, and consumed during normal usage. With HDInsight, however, I design the environment based on the usage of the cluster. Additionally, I can schedule the HDInsight cluster compute resource to only be available during the time that scheduled jobs need to execute.
Since HDInsight clusters are primarily designed for the type of compute usage that is needed, it’s common practice to create multiple compute clusters to meet the needs of different jobs. The next decision point is knowing what type of cluster to create. With multiple clusters, I can cater the architecture and design to match the exact requirements of the jobs that are going to be run.
What is the right type of HDInsight cluster to create?
HDInsight supports 4 main types of workloads:
| Workload | HDInsight Cluster Type |
| ETL/ELT | Hadoop |
| Data in Motion / IoT | Storm |
| Transactional Processing | HBase |
| Data Science / Advanced Analytics | Spark -or- R Server with Spark |
Because HDInsight is a platform-as-a-service offering, and the compute is segregated from the data, I can modify the choice for the cluster type at any time. Multiple clusters connected to the same data source is also a supported configuration.
A typical project has the following sample processing requirements:
- Several hours of processing each night to prepare data for daily reporting
- Additional hours of processing either weekly or monthly to close fiscal cycles
- Development environments for analysts to build / test statistical models
An on-premises cluster would have to grow pretty large in order to encompass all of these use cases, but with HDInsight I can create multiple transient clusters to meet the business requirements. Here is a visual example of how HDInsight clusters can be managed to control the compute costs incurred by the platform.

When I design HDInsight projects, I don’t worry about building a single cluster that meets every need. I take a look at what’s needed by the job requirements, how long the jobs will run, and then design a right-sized compute cluster that will complete that job. Other jobs may have different requirements, and therefore may require a different cluster type and compute size.
What about data storage?
Above, I explained how data and compute are physically separated in HDInsight, and that wasn’t an exaggeration. When I create an HDInsight cluster, I also specify one or more Azure Blob Storage accounts to store data that the cluster will access. Azure Storage accounts are the default storage location for data processed by HDInsight.
Azure Data Lake Store (ADLS) is a new storage offering from Microsoft that is another option for storing data. ADLS is fully distributed, and like Azure Storage, ADLS keeps your data separated from compute, and allows for data access whether the cluster is running or not. Major benefits that ADLS has over Azure Storage Blobs include:
- True distributed file system optimized for parallel processing jobs
- Security model integrated with Azure Active Directory
- No file size or account storage limits
In both cases, multiple clusters can reference the same storage, so data can easily be shared between processing units and business teams. Right now, ADLS is a preview technology. This means that you’ll need to use Azure Blob Storage for your default cluster storage.
At 3Cloud, we’ve done significant testing with ADLS and are excited about its performance and security model. When it graduates to General Availability (GA) it will be our recommended storage platform of choice for Big Data projects with HDInsight.
Now for the big question, Windows or Linux?
Linux.
Snarky answers aside, at 3Cloud we support the idea of deploying Hadoop on Linux, especially for HDInsight. Linux is more widely supported in the Hadoop community and since HDInsight is based directly on Hortonworks HDP, it makes sense to deploy clusters on the most widely supported operating systems. Other benefits of running HDInsight on Linux include:
- Full support of Hadoop user interfaces including Ambari and Jupyter
- Direct remote access into cluster nodes via SSH — Windows-based HDInsight clusters are limited to pre-scheduled Remote Desktop into the master head node only
- Access to advanced features of HDInsight including Spark and R Server
Updates to HDInsight are also delivered first to Linux, followed several weeks later by updates to Windows-based clusters. With a faster update cycle, clusters running on Linux will be more secure, and more current with the latest patches, and features.
So, how do I pick the right HDInsight cluster?
Designing an HDInsight environment is very different from designing an on-premises Hadoop environment. The best cluster configuration may very well be multiple compute clusters, running at different times, designed to handle different workloads. The separation of compute and data is key to this architecture functioning as well as it does. Keeping the data in a separate location from the compute cluster opens up a number of possibilities not available with on-premises hardware.
When choosing the cluster type, keep in mind the targeted workloads for each configuration, and remember to strongly consider Linux as your choice of OS, even if your team doesn’t have Linux support. HDInsight is a platform-based offering, so it doesn’t have heavy-handed operating system administration requirements.
While you’ll have to store your data in Azure Storage for now, keep a close eye on Azure Data Lake Storage. The POSIX-compatible filesystem and distributed nature will be very powerful in the future as it matures into general availability.
If you have questions or need assistance with an HDInsight or advanced analytics project, please reach out today.



