
Computer vision is one area where AI has really shone in recent years. In this post we’ll be taking a look at the handwriting recognition available in Read within Microsoft Azure’s Cognitive Services.
I’ve found that in the work-from-home environment I make excessive use of my whiteboards. Yes, plural, whiteboards. I really enjoy them. What I don’t enjoy is wishing I hadn’t erased something after I have. It doesn’t happen terribly often but because it has I end up cramming notes into every nook and cranny of it before I start erasing the oldest stuff.

The simplest solution would be to snap a picture with my cell phone and call it good. Even better would be mounting a security camera pointed at my whiteboard so there’s a nice consistent angle to the shots. If I’m going this far with it I might as well throw some AI based handwriting OCR at it so I can generate a searchable database, right? It’s the natural thing to do.
Having recently had some excellent experience using text analytics within Cognitive Services I was eager to see what Read would give recognizing my whiteboard writing. I was expecting it be bamboozled by my sometimes-horrible handwriting or requiring some level of pre-processing to sharpen and clarify the input but the results from sending in the very first image were fantastic!
This blog post won’t be a code-level review. For that I recommend Microsoft’s Read’s QuickStart guide.
(I’ve linked to the Python version of the QuickStart for a reason. While we will not go into the code behind this I will mention I used OpenCV for the input, image manipulation, and output elements. OpenCV is a handy tool to have in your back pocket for computer vision projects and Python is a popular language to work with it. I doubt you will regret giving the combination a shot.)
What you will get back from Read is a JSON document giving you the coordinates around each block of text and the text within. With that I can (crudely) draw a white box over the original text and draw the text back on in a variable font size that is roughly the right size.
Here you can see a before and after of what the original board looked like and a visual representation of what Read told us about it.
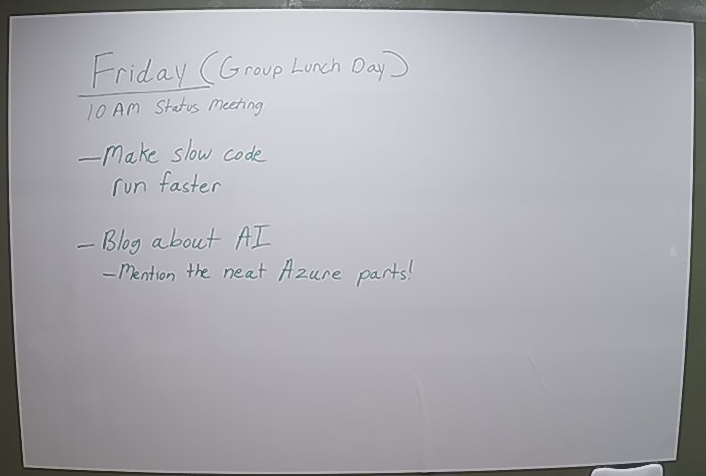
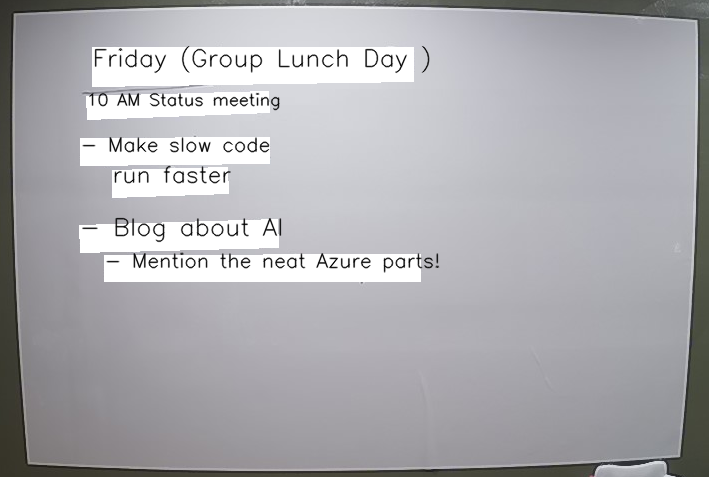
There is also some additional metadata about confidence levels regarding the text predictions returned from Read but I was not concerned with that for this experiment.
At this point I have all the data I need for a simple logging of what I’ve had on my whiteboard any given day. Future enhancements will likely include logging it all into OneNote for me, or maybe a method to publish to a Teams channel to share with a group. Perhaps some better color matching to the original whiteboard background and marker color is in order too.
If you’re interested in learning more we’d welcome a discussion with you and your team. Please contact us today!



