Sample data is critical for learning data systems and techniques, developing proofs of concept, and performance testing. And while sample datasets are easy to find, a limitation shared by most of them is that they are small. This is fine in many cases, but if you really want to evaluate a big data system, you’re going to need big data. Unfortunately, big datasets are difficult to find. One solution to this problem is the TPC-DS benchmark dataset. Instead of having to download and move this data to the desired location, it is generated using software provided by the TPC (Transaction Processing Performance Council).
The TPC-DS dataset has some important advantages; the first being that it is variable in size – supporting datasets up to 100 terabytes (TB)!
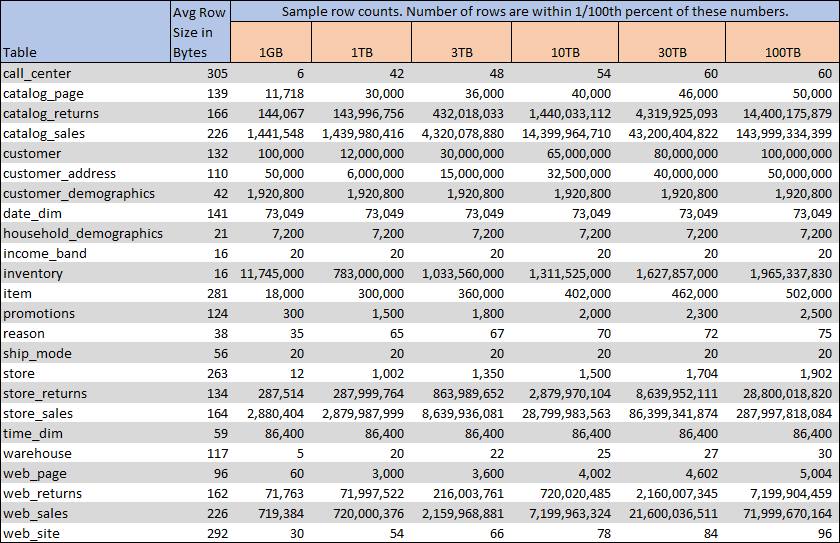
Another big advantage is that the data is modeled as multiple snowflake schemas, with fact and dimension tables having realistic proportions. This makes the dataset representative of typical data warehouse workloads. A nice summary of the TPC-DS benchmark can be found here.
Databricks spark-sql-perf Library
You can run the data generator as is from the TPC (dsdgen) on your personal computer or other machines, but the features are limited and it’s difficult to impossible to generate data at the larger scales on modest hardware. This is where the spark-sql-perf library from Databricks comes in handy. The spark-sql-perf library allows you to generate TPC-DS data on a Databricks cluster size of your choosing, and provides some important added features, such as:
- Additional file storage formats, such as Parquet
- File partitioning
- Database creation with optional statistics collection
With Databricks, you can use a powerful cluster of machines to generate the data at any scale, and when you’re done you can terminate or delete the cluster, leaving the data in place.
Generate Data
The 3Cloud GitHub repository tpc-ds-dataset-generator contains everything you need to generate the data except a storage account. Below are a few sample results from generating data at the 1 and 1000 scale.
| File Format | Generate Column Stats | Number of dsdgen Tasks | Partition Tables | TPC-DS Scale | Cluster Config | Duration | Storage Size |
| csv | no* | 4 | no | 1 | 1 Standard_DS3_v2 worker, 4 total cores | 4.79 min | 1.2 GB |
| parquet | yes | 4 | no | 1 | 1 Standard_DS3_v2 worker, 4 total cores | 5.88 min | 347 MB |
| json | no* | 4 | no | 1 | 1 Standard_DS3_v2 worker, 4 total cores | 7.35 min | 5.15 GB |
| parquet | yes | 1000 | yes | 1000 | 4 Standard_DS3_v2 worker, 16 total cores | 4 hours | 333 GB |
* Attempting to generate column stats with csv and json both resulted in error.
Explore the Data
Let’s take a look at how the data can be used for demo purposes. In this example we’ll query the same data stored as both uncompressed delimited and as Databricks Delta. The cluster has four Standard_DS3_v2 workers.
First let’s query the delimited data. The query is simple, but it involves a 418 gigabytes (GB) fact table that contains 2.9 billion rows.
%sql
USE tpcds001tbadlsgen2;
SELECT date_dim.d_year
,SUM(store_sales_delimited.ss_quantity)
FROM store_sales_delimited
INNER JOIN date_dim
ON store_sales_delimited.ss_sold_date_sk = date_dim.d_date_sk
GROUP BY date_dim.d_year
This query took 12.72 minutes. Now let’s convert the data to Databricks Delta, which stores the data as parquet.
%sql
USE tpcds001tbadlsgen2;
DROP TABLE IF EXISTS store_sales_delta;
CREATE TABLE store_sales_delta
USING DELTA
LOCATION ‘/mnt/adlsGen2/tpc-ds/SourceFiles001TB_delta/store_sales_delta’
AS SELECT * FROM store_sales
Parquet is highly compressed, and the data now sits at 141 GB. Let’s run the same query against the data stored as Databricks Delta.
%sql
USE tpcds001tbadlsgen2;
SELECT date_dim.d_year, SUM(store_sales_delta.ss_quantity)
FROM store_sales_delta
INNER JOIN date_dim
ON store_sales_delta.ss_sold_date_sk = date_dim.d_date_sk
GROUP BY date_dim.d_year
This time the query took only 1:35 minutes, which is 9.4 times faster!
This is just one example of how it’s helpful to have big datasets for testing. If you’d like to generate big datasets for yourself, head over to the 3Cloud repository on GitHub to get started!
Dive into Databricks
Interested in how we’ve put Azure Databricks to use for others? Visit our Databricks resources collection to discover how we’ve used it to implement predictive maintenance to cut operational downtime or explore a retail analytics product dimension load using Databricks.