Power BI is able to connect to all sorts of different data sources (and more are being added every month), and as my colleague Josh Fennessy pointed out in a recent blog post, there’s no shortage on different design patterns for implementing a big data cloud solution with HDInsight. This can make figuring out the best way to visualize your big data sources from HDInsight using Power BI a little challenging. Below, I will try to outline some common approaches to using Power BI with HDInsight.
Refresh from Hive Tables/Queries
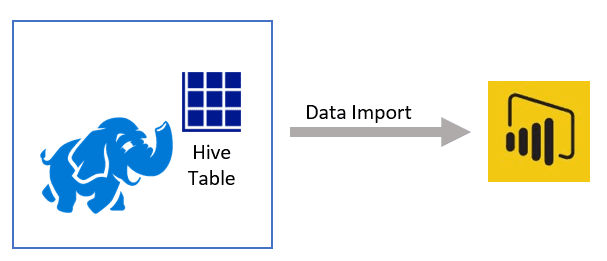
If you are using a Hadoop cluster in HDInsight, one way you might use Power BI to connect to your data is with Hive tables. Hive provides a logical layer for you to extract the data from. Using the Microsoft Hive ODBC Driver, you can import entire Hive tables into Power BI or write Hive queries to import data directly into Power BI.
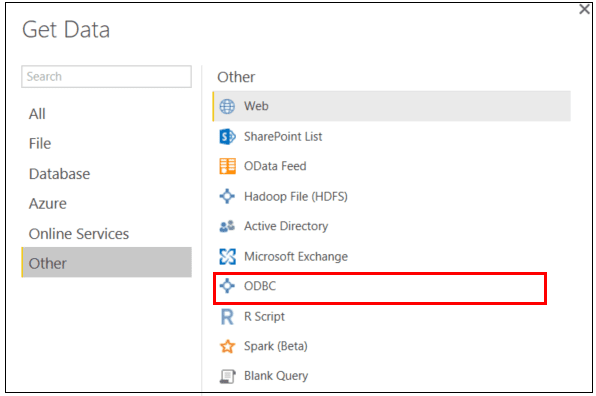
Importing from Hive tables/queries provides a familiar SQL-like feel and syntax, and you are able to use the whole gamut of modeling capabilities within Power BI Desktop. It is important to understand, however, that data refreshes with this method can often be slow as a Hive job will be executed on your cluster before transferring the data. Being that this method imports data directly into the Power BI model, you may also be limited in the size of the data that you can work with, as the model will have to fit into the memory of your machine and/or the file size limits of the Power BI service. Your cluster will also need to be up and running at the time of a Power BI refresh so that Power BI can see/access any Hive objects.
Refresh from Flat Files
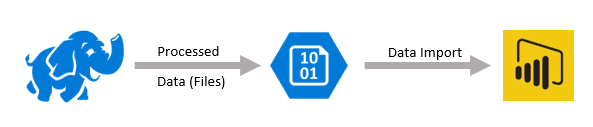
Another way to import data from HDInsight into Power BI is by connecting to flat files in either Blob or the Data Lake Store. In this scenario, you would use HDInsight to process your data and write the resulting curated or aggregated data into text files (CSV, TAB, etc.) Unlike refreshing from Hive tables, refreshing from flat files would allow you to only run your HDInsight cluster while processing data (deleting a cluster when it is not active can help save money in Azure consumption) as the resulting text files would still exist in Azure storage even when the cluster is deleted.
Data refreshes into Power BI are also likely to be faster when pulling directly from flat files versus using the Hive ODBC Driver referenced above. You will still run into the same model size restrictions as when using Hive tables/queries, as you are still importing data directly into a Power BI model.
The previous two methods for using Power BI with HDInsight required importing data into a Power BI model, thus limiting the size of your model to the constraints of your computer or the Power BI Service. The next two methods will utilize DirectQuery in which your data will stay at the data source, thus removing the model size limitations discussed before.
DirectQuery with Spark
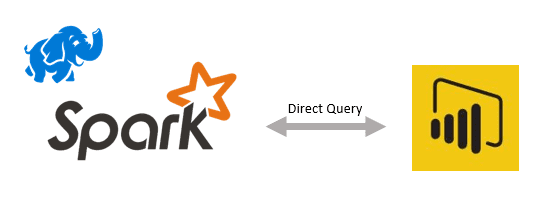
The first method is connecting directly to tables in a Spark cluster. With this method, you will process your data in Spark and then put the resulting data into tables on the cluster. Power BI can then use Spark SQL to interactively query the tables in Power BI’s DirectQuery mode.
Again, the key advantage here is that the data stays at the source, which removes the need to schedule Power BI refreshes and worry about Power BI model size. A downside to this approach is that in order for Power BI to connect to a table in Spark, the cluster must be running, which likely means the cluster is on all the time (depending on when your users will be using the reports/model). This can sometimes be more expensive than only turning your cluster on for processing data and deleting it when you are done (as with the flat files method).
DirectQuery from Azure SQL DB
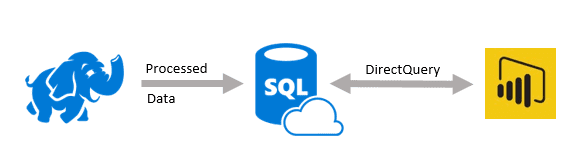
The final method we will look at is DirectQuery using Azure SQL Database (DB). In this approach, similar to the flat files approach, you would process your data in your cluster, but write the resulting curated and/or aggregated data to tables in Azure SQL DB (or Azure SQL Data Warehouse).

As with the flat files approach, this allows you to delete your cluster when you are done processing data (which helps control costs) as the processed data will still reside in the SQL DB when the cluster is gone. However, unlike the flat files approach, Azure SQL DB can be highly optimized and is well suited for DirectQuery in Power BI. This means that you will not have to worry about data refreshes at the Power BI level. When connected to Azure SQL DB with Power BI using DirectQuery, you also still have a lot of additional modeling capabilities included in Power BI, like creating new measures, calculated columns, and relationships between tables. The downside to this approach is that you will need to set up and configure an Azure SQL DB service, and that service will likely need to run all the time (depending on when your users will be using the reports/model). Also, while DirectQuery virtually removes any limitations on the Power BI model size, you still have to be concious of the size, performance, and cost of your Azure SQL DB instance.
While there are likely other ways to work with HDInsight using Power BI, these are some of the more common scenarios we have run into and deployed. Hopefully this helps in planning your architecture for visualizing your big data in the cloud.